繼文本生成、影像生成後,影片生成也加入到了「內卷」行列。
7月26日的智譜Open Day上,在大模型賽道上動作頻頻的智譜AI,正式推出影片生成模型CogVideoX,並放出了兩個「大招」:
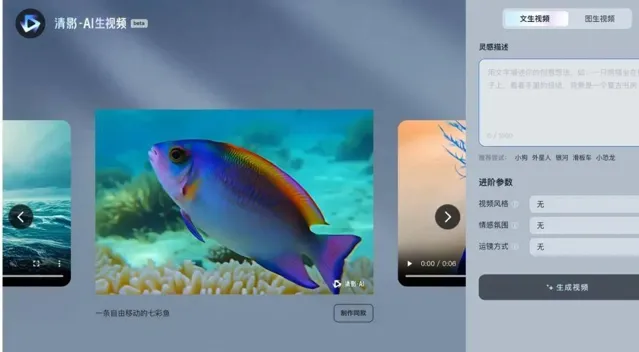
一個是智譜清言打造的影片創作智能體清影,可使用文本或圖片生成時長6秒、1440x960清晰度的高精影片。
另一個是智譜清言小程式上線的「讓照片動起來」,可以直接在小程式中上傳照片,輸入提示詞生成動態影片。
不同於一些小範圍開放或預約才能使用的產品, 清影智能體面向所有使用者開放,輸入一段提示詞,選擇自己想要的風格,包括卡通3D、黑白、油畫、電影感等等,配上清影內建的音樂,就能生成充滿想象力的短影片。企業和開發者也可以透過呼叫API的方式,體驗文生影片和圖生影片能力。
由此引出了這樣一個問題:目前影片生成類產品仍處於「可玩」的階段,距離商用仍然有不小的鴻溝,智譜AI的進場將產生什麽樣的影響?
01 更快更可控的「清影」
在Sora引爆影片生成賽道後,行業內掀起了一場連鎖反應,先是Runway、Pika等產品在海外市場走紅,國內在4月份以後也陸續曝光了多個文生影片類大模型,幾乎每個月都會有新產品上線。
市場層面越來越熱鬧,體驗上卻陷入了相似的困局,確切的說是兩大繞不過去共性問題:
一是推理速度慢,哪怕只是4秒的影片,也需要10分鐘左右才能生成,而且影片越長,生成的速度越慢;
二是可控性差,在限定的語句和限定的訓練樣本內,可以有不錯的效果,一旦「越界」就會出現「群魔亂舞」的情況。
有人將其比作為遊戲中的「抽卡」,多試幾次才會生成想要的效果。然而一個無法掩蓋的事實是,倘若文生影片要嘗試25次才能生成一次可用的,每次生成的時間動輒10分鐘,意味著想要獲得一條幾秒中的影片,需要長達四個多小時的時間成本,所謂的「生產力」也就無從談起。
在智譜清言裏試用了「清影」的文生影片和圖生影片功能後,我們發現了兩個令人驚艷的體驗:生成一條6秒的影片,只需要花費30秒左右,推理時間從分鐘級被壓縮到了秒級;采用「鏡頭語言+建立場景+細節描述」的提示詞公式,一般「抽兩三次卡」就能夠獲得讓人滿意的影片內容。
以文生影片的場景為例,給「清影」輸入「寫實描繪,近距離,獵豹臥在地上,身體微微起伏」的指令後,一分鐘內就生成了一段「以假亂真」的影片:風吹動草地的背景,獵豹不斷晃動的耳朵,隨著呼吸起伏的身體,甚至每一根胡須都栩栩如生……幾乎可以被誤認為是近距離拍攝的影片。
為什麽智譜AI可以「跳過」行業內普遍存在的痛點?因為所有的技術問題,都可以透過技術上的創新解決。
隱藏在智譜清言影片創作智能體「清影」背後的,是智譜大模型團隊自研打造的影片生成大模型CogVideoX,采用了和Sora一樣的DiT結構,可以將文本、時間和空間融合。
透過更好的最佳化技術,CogVideoX的推理速度較前代模型提升了6倍;為了提升可控性,智譜AI自研了一個端到端影片理解模型,為海量的影片數據生成詳細的、貼合內容的描述,以增強模型的文本理解和指令遵循能力,使得生成的影片更符合使用者的輸入,並能夠理解超長復雜prompt指令。
如果說市面上的同類產品還在「可用」上下功夫,創新上「全壘打」的智譜AI已經進入了「好用」的階段。
直接的例子就是智譜清言同步提供的配樂功能,可以為生成的影片配上音樂,使用者需要做的僅僅是釋出。無論是沒有影片制作基礎的小白使用者,還是專業的內容創作者,都可以借助「清影」讓想象力化為生產力。
02 Scaling Law再次被驗證
每一次看似不尋常的背後,都有其必然性。在同類產品要麽不開放使用,要麽還處於Alpha版本的階段,「清影」之所以成為人人可用的AI影片套用,離不開智譜AI在頻生成大模型上的多年深耕。
時間回到2021年初,距離ChatGPT的走紅還有近兩年時間,諸如Transformer、GPT等名詞只是在學術圈討論時,智譜AI就推出了文生圖模型CogView,可以將中文文字生成影像,在MS COCO的評估測試中超過OpenAI的Dall·E,並在2022年推出了CogView2,解決了生成速度慢、清晰度低等問題。
到了2022年,智譜AI在CogView2的基礎上研發了影片生成模型CogVideo,可以輸入文本生成逼真的影片內容。

彼時外界還沈浸在對話式AI的場景中,影片生成並不是焦點話題,但在前沿的技術圈裏,CogVideo已經是炙手可熱的「明星」。
比如CogVideo采用的多幀率分層訓練策略,提出了一種基於遞迴插值的方法,即逐步生成與每個子描述相對應的影片片段,並將這些影片片段逐層插值得到最終的影片片段,賦予了CogVideo控制生成過程中變化強度的能力,有助於更好地對齊文本和影片語意,實作了從文本到影片的高效轉換。
Meta推出的Make-A-Video、谷歌推出的Phenaki和MAGVIT、微軟的女媧DragNUWA以及輝達Video LDMs等等,不少影片生成模型都參照了CogVideo的策略,並在GitHub上引起了廣泛關註。
而在全新升級的CogVideoX上,諸如此類的創新還有很多。比如在內容連貫性方面,智譜AI自研了高效三維變分自編碼器結構(3D VAE),將原影片空間壓縮至2%大小,配合3D RoPE位置編碼模組,更有利於在時間維度上捕捉幀間關系,建立起影片中的長程依賴。
也就是說,影片創作智能體「清影」的出現絕非偶然和奇跡,而是智譜AI日拱一卒式創新的必然結果。
大模型行業有一個著名的定律叫Scaling Law,即在不受其他因素制約時,模型的效能和計算量、模型參數量、數據大小呈現冪律關系,增加計算量、模型參數量或數據大小都可能會提升模型的效能。
按照智譜AI官方給出的資訊,CogVideoX的訓練依托亦莊高效能算力集群,而且合作夥伴華策影視參與了模型共建、另一家合作夥伴bilibili參與了清影的技術研發過程。沿循這樣的邏輯,「清影」在生成速度、可控性上超預期的體驗,無疑再一次印證了Scaling Law定律的有效性。
甚至可以預見,在Scaling Law的作用下,後續版本的CogVideoX,將擁有更高分辨率、更長時長的影片生成能力。
03 「多模態是AGI的起點」
一個可能被習慣性忽略的資訊在於,智譜AI並沒有將「清影」作為獨立的產品,而是以智譜清言的智能體上線。
個中原因可以追溯到智譜AI CEO張鵬在ChatGLM大模型釋出會上的演講:「2024年一定是AGI元年,而多模態是AGI的一個起點。如果想要走到AGI這條路上去,只停留在語言的層面不夠,要以高度抽象的認知能力為核心,把視覺、聽覺等系列模態的認知能力融合起來,才是真正的AGI。」
5月份的ICLR 2024上,智譜大模型團隊在主旨演講環節再次闡述了對AGI技術趨勢的判斷:「文本是構建大模型的關鍵基礎,下一步則應該把文本、影像、影片、音訊等多種模態混合在一起訓練,構建真正原生的多模態模型。」
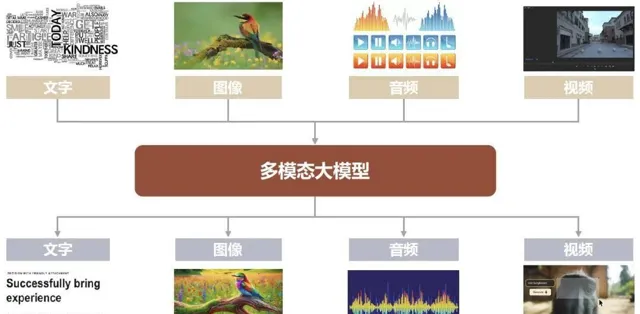
過去一年多時間裏,大模型的熱度一浪高過一浪,卻未能擺脫「缸中大腦」的局限,套用場景十分有限。而大模型想要脫虛向實,想要走進實際的生活和工作中創造價值,必須要長出手腳的執行能力,比如在語言能力外延伸出聽覺和視覺的能力,並透過這些能力和物理世界進行無縫連線。
再來審視影片生成大模型CogVideoX和影片創作智能體「清影」,無疑可以得出一些不一樣的答案。
CogVideoX的文生影片、圖生影片能力,可以看作是對認知能力的拆解,先實作單項能力的突破;以影片創作智能體形態出現的「清影」,可以看作是對不同模型能力的收攏,在原生多模態大模型還不太成熟的情況下,使用者可以透過多個智能體的組合,高效且精準地解決現實問題。
可以佐證的是,在智譜AI的大模型矩陣裏,已經涵蓋具備視覺和智能體能力的GLM-4/4V、推理極速且高性價比的GLM-4-Air、基於文本描述創作影像的CogView-3、超擬人角色客製模型CharacterGLM、擅長中文的向量模型Embedding-2、程式碼模型CodeGeeX、開源模型GLM-4-9B以及影片生成大模型CogVideoX,客戶可以根據不同的需求呼叫不同大模型,找到最優解。
而在To C套用方面,目前智譜清言上已經有30多萬個智能體,包括思維導圖、文件助手、日程安排等出色的生產力工具。同時智譜AI還推出了由數十萬個AI體組成的多智能體協作系統——清言Flow,不僅限於單一智能體的互動,涉及多輪、多型、多元的對話互動模式,人們僅需透過簡潔的自然語言指令,就能處理高度復雜的任務。
做一個總結的話:現階段距離真正意義上的AGI還有不小的距離,但智譜AI正在用「單項突破,能力聚合」的方式,提前讓AGI照進現實,讓強大的大模型能力真正用來幫助人們的工作、學習和生活。
04 寫在最後
需要正視的是,目前影片生成大模型對物理世界規律的理解、高分辨率、鏡頭動作連貫性以及時長等,仍存在非常大的提升空間。
在通往AGI的路上,智譜 AI等大模型廠商不應該是孤獨的行路者。作為普通使用者的我們,也可以是其中的一員,至少可以在智譜清言上用自己的「腦洞」生成有趣的影片,讓更多人看到大模型的價值,利用AI提升創作效率的同時,加速多模態大模型不斷走向成熟。











