魚羊 發自 凹非寺量子位 | 公眾號 QbitAI
開源大模型,已經開啟大卷特卷模式。
全球範圍,太平洋兩岸,雙雄格局正在呼之欲出。
Llama 3中杯大杯剛驚艷亮相,國內通義千問就直接開源千億級參數模型Qwen1.5-110B,一把火上Hacker News榜首。
不僅相較於自家720億參數模型效能明顯提升,在MMLU、C-Eval、HumanEval等多個基準測試中,Qwen1.5-110B都重返SOTA開源模型寶座,超越Llama 3 70B,成最強開源大模型。

中文能力方面,對比僅餵了5%非英文數據的Llama 3 70B,Qwen1.5-110B更是優勢明顯。
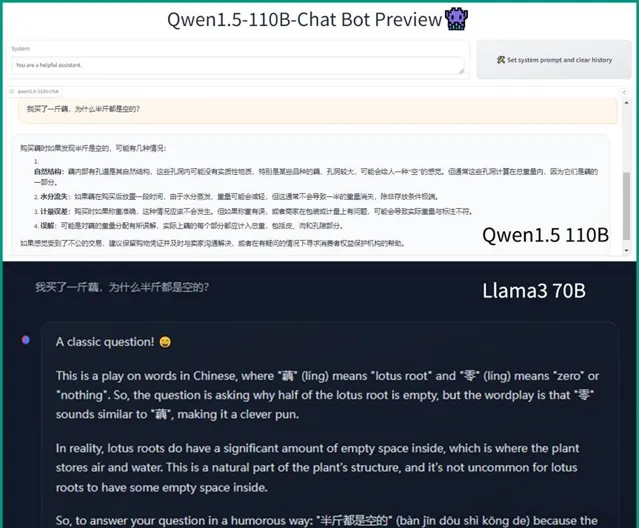
於是乎,模型一上線,開源社區已經熱烈響應起來。
這不,Qwen1.5-110B推出不到一天,幫助使用者在本地環境執行建立大語言模型的Ollama平台,就已火速上線連結。
值得關註的是,這已經是3個月內通義千問開源的第8款大模型。
開源大模型都在卷些什麽?
那麽,問題來了,因Llama 3和Qwen1.5接連開源而持續的這波開源大模型小熱潮中,開源模型又在卷些什麽?
如果說上一階段由馬斯克Grok和Mixtral所引領的話題熱點是MoE,那網友們這一兩周內聚焦的第一關鍵詞,當屬Scaling Laws——
尺度定律
OpenAI創始成員、前特斯拉AI總監Andrej Karpathy在總結Llama 3時,就著重提到過其中尺度定律的體現:
Llama 2在2T token數據上訓練,而Llama 3直接加碼到了15T,遠超Chinchilla推薦量。並且Meta提到,即便如此,模型似乎依然沒有以標準方式「收斂」。

也就是說,「力大磚飛」這事兒還遠沒有達到上限。
無獨有偶,Qwen1.5-110B延續了這個話題的討論。
官方網誌提到,相比於Qwen1.5-72B,此次開源的千億參數模型在預訓練方法上並沒有太大的改變,但包括編程、數學、語言理解、推理在內的各項能力提升明顯。
我們認為效能提升主要來自於增加模型規模。
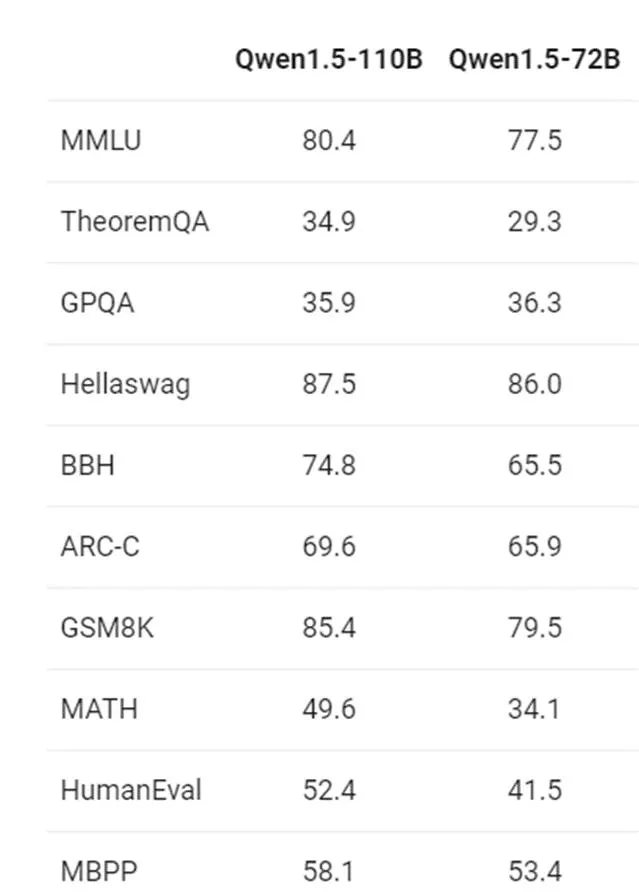
更強大、更大規模的基礎語言模型,也帶來了更好的Chat模型。

阿裏的研究人員們指出,Qwen1.5-110B的評測成績意味著,在模型大小擴充套件方面仍有很大的提升空間。
官方還淺淺劇透了Qwen 2的研究方向:同時擴充套件訓練數據和模型大小,雙管齊下。

多語言和長文本能力
尺度定律之外,由閉源模型掀起的長文本風潮,同樣在開源模型身上被重點關註。
Llama 3的8K上下文視窗,就遭到了不少吐槽:實在有點「古典」。
Qwen1.5-110B在這方面延續了同系列模型的32K上下文。在此前的測試中,長文本能力測試結果顯示,即使是Qwen1.5-7B這樣的「小模型」,也能表現出與GPT3.5-turbo-16k類似的效能。
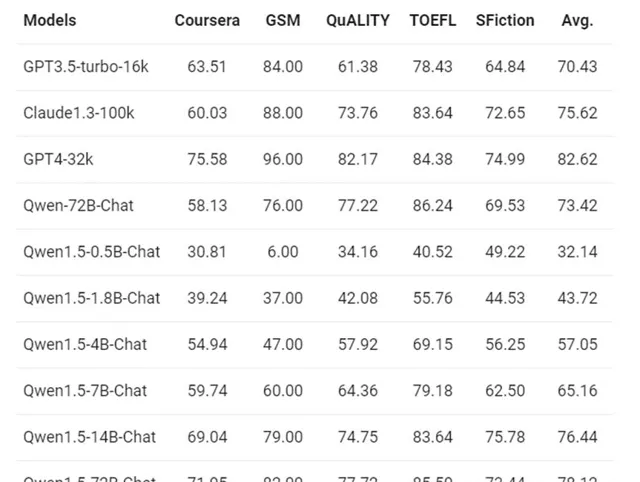
並且,開源的優勢就是敢想你就來。

Qwen1.5官方網誌中提到,雖然紙面給的是32K吧,但並不代表模型的上限就到這兒了:
您可以在config.json中,嘗試將max_position_embedding和sliding_window修改為更大的值,觀察模型在更長上下文理解場景下,是否可以達到您滿意的效果。
另一個由通義千問而被cue到的大模型能力評判指標,就是多語言能力。
以Qwen1.5-110B為例,該模型支持中文、英文、法語、西班牙語、德語、俄語、韓語、日語、越南語、阿拉伯語等多種語言。
阿裏高級演算法專家林俊旸分享過通義千問團隊內部收到的反饋:實際上,多語言能力在全球開源社區中廣受歡迎,正在推動大模型在全球各地的落地套用。
而Qwen1.5在12個比較大的語言中,表現都不遜於GPT-3.5。

對於中文世界而言,這也是國產開源大模型的優勢所在。
畢竟Llama 3強則強矣,訓練數據方面中文語料占比實在太少(95%都是英文數據),單就中文能力而言,確實沒法兒拿來即用。

相比之下,Qwen1.5 110B的中文實力就靠譜多了。
能讓歪果仁瞬間抓狂的中文水平測試,輕松拿捏:

弱智吧Benchmark,也能應對自如:

此外,還有不少網友提到了開源模型型號豐富度的問題。

以Qwen1.5為例,推出不到3個月,已經連續開源8款大語言模型,參數規模涵蓋5億、18億、40億、70億、140億、320億、720億和1100億,還推出了程式碼模型CodeQwen1.5-7B,和混合專家模型Qwen1.5-MoE-A2.7B。
隨著大模型套用探索的不斷深入,業界已經逐漸達成新的共識:在許多具體的任務場景中,「小」模型比「大」模型更實用。
而隨著大模型套用向端側的轉移,豐富、全面的不同型號開源模型,無疑給開發者們帶來了更多的選擇。
「把開源進行到底」
如同大洋彼岸OpenAI引領閉源模型發展,而Meta靠開放權重的Llama系列另辟蹊徑,在國內,阿裏正是大廠中對開源大模型態度最積極的一家。
從Qwen到Qwen1.5,再到多模態的Qwen-VL和Qwen-Audio,通義千問自去年以來可謂開源訊息不斷。僅Qwen1.5系列,目前累計已開源10款大模型。

阿裏官方,也已直接亮明「把開源進行到底」的態度。這在卷大模型的互聯網大廠中,確實是獨一份。
所以,阿裏堅持走開源路線,背後的底層邏輯是什麽?
或特許以拆解為以下幾個層面來分析。
首先,在技術層面,盡管以GPT系列、Claude系列為代表的閉源模型們目前占據著領先地位,但開源模型也「步步緊逼」,不斷有新進展驚艷科技圈。
圖靈獎得主Yann LeCun就曾援引ARK Invest的數據認為「開源模型正走在超越閉源模型的道路上」。
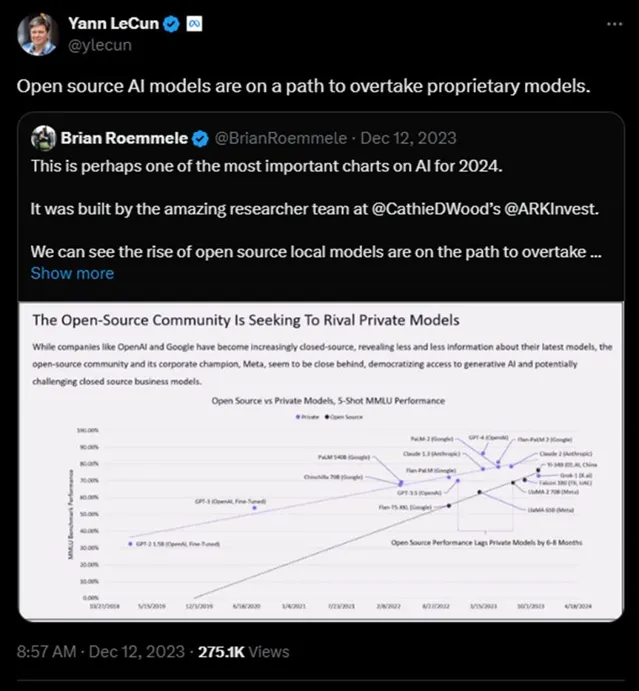
ARK Invest當時預測,在2024年,開源模型會對閉源模型的商業模式構成挑戰。
而隨著Llama 3為標桿的新一波開源大模型的爆發,越來越多的業內專家也開始期待,強大的開源模型「會改變很多學界研究和初創公司的發展方式」。

值得一提的是,開源模型獨特的一重優勢在於,來自開源社區的技術力量,同時也反哺了開源大模型的發展。
林俊旸就在量子位AIGC產業峰會上分享過,通義千問32B的開源,就是在因開發者們的反饋而推動的。
其次,在套用落地層面,開源大模型無疑起到了加速器的作用。
開源社區的熱情就側面佐證了開發者們把基礎模型的控制權把握在自己手中的傾向性。
以通義千問為例,在HuggingFace、魔搭社區的下載量已經超過700萬。
更實際的落地案例,也正在各行各業中持續實作。
比如,中國科學院國家天文台人工智能組,就基於通義千問開源模型,開發了新一代天文大模型「星語3.0」,將大模型首次套用於天文觀測領域。

而對於推動開源的企業而言,打響的也不僅僅是名氣和在開發者社區中的影響力。
通義千問的B端業務,也正因開源而加速。
最新訊息是,通義大模型不僅「上天」,現在還「下礦」了。
繼西部機場集團推出基於阿裏雲通義大模型打造的首個航空大模型後,西安塔力科技透過接入阿裏雲通義大模型,打造了新型礦山重大風險辨識處置系統,並已在陜煤建新煤礦等十余座礦山上線,這是大模型在礦山場景的首次規模化落地。
目前,新東方、同程旅行、長安汽車、親寶寶等多家企業均已宣布介入通義大模型。

轟轟烈烈的百模大戰硝煙漸散,當人們開始討論閉源模型格局初定時,2024年,不得不說開源大模型給整個技術圈帶來了不少新的驚喜。
而隨著大模型套用開始成為新階段探索的主旋律,站在開發者、初創企業、更多非互聯網企業的角度而言,以Llama、通義千問等為代表的開源大模型越強,垂直行業結合做行業大模型的自由度就會越高,落地速度也會越快。
過去互聯網的繁榮建立在開源的基礎之上,而現在,在大模型風暴中,開源大模型再次顯現出鯰魚效應。
自研大模型的必要性和競爭力,正在不斷被開源卷王們卷沒了。











