IT之家 5 月 14 日訊息,騰訊宣布旗下的混元文生圖大模型升級並對外開源,目前已經在 Hugging Face 及 Github 上釋出,包含模型權重、推理程式碼、模型演算法等完整模型,可供企業與個人開發者免費商用。


升級後的混元文生圖大模型采用了與 Sora 一致的 DiT 架構,騰訊表示,混元 DiT 是首個中英雙語 DiT 架構。混元 DiT 是一個基於 Diffusion transformer 的文本到影像生成模型,此模型具有中英文細粒度理解能力,混元 DiT 能夠與使用者進行多輪對話,根據上下文生成並完善影像。這也是業內首個中文原生的 DiT 架構文生圖開源模型,支持中英文雙語輸入及理解,參數量 15 億。
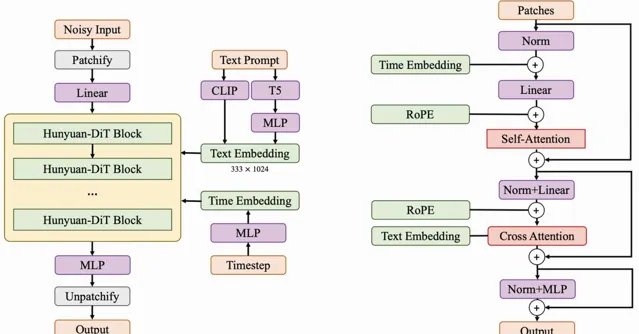
執行該模型需要支持 CUDA 的輝達 GPU,單獨執行混元 DiT 所需的最低視訊記憶體為 11GB,同時執行 DialogGen(騰訊推出的文本轉影像多模態互動式對話系統)和混元 DiT 則至少需要 32GB 的視訊記憶體,騰訊表示他們已經在 Linux 上測試了輝達的 V100 和 A100 GPU。

據IT之家此前報道,國內首個官方「大模型標準符合性評測」結果公布,騰訊混元大模型、成為首批透過評測的國產大模型,首批透過的大模型還有阿裏通義千問、360 智腦和百度文心一言。











