 智東西
智東西
作者 | GenAICon 2024
2024中國生成式AI大會於4月18-19日在北京舉行,在大會第二天的主會場AI Infra專場上,新加坡國立大學校長青年教授、潞晨科技創始人兼董事長尤洋以【技術共享:類Sora開源架構模型與訓練細節】為題發表演講。
潞晨科技在今年3月開源的 全球首個類Sora影片生成模型Open-Sora ,是迄今GitHub上獲得星標數最高的開源影片大模型專案之一,截至發稿前已 有1.6萬個星標 ,使用者群體遍及全球。
值得一提的是,這個模型在低成本下訓練而成,相比Sora耗費數千張p00 GPU、花費數千萬美元乃至數億美元,Open-Sora的 訓練成本僅不到1萬美元 。
尤洋認為, 影片生成正處於「GPT-2時刻」,還沒有出現成熟的套用 。對於影片生成模型來說, 數據 可能是最核心的資產。他還談到, 模型開源是有意義且重要的 。正如Meta最新釋出的Llama 3,極大地調動了開源社區的積極性,不但造福大量開發者,更有助於開源社區整體的繁榮。
因此,Open-Sora模型也進行了 全面的訓練流程開源 ,開源了包括 模型架構、模型權重、訓練細節、數據處理 在內的多項技術細節,讓更多的開發者可以嘗試Open-Sora模型,共同叠代與升級。
在演講期間,他詳細解讀了成功復現類Sora影片生成模型的 四個關鍵要素 ,並分享了Open-Sora的底層架構、demo和教程。
在他看來,考慮到成本壓力,影片生成模型將分為 大規模影像預訓練、大規模影片預訓練、高質素影片數據微調 三個階段。在模型設計上, 時空分割處理 將是顯著降低影片生成模型計算成本和記憶體壓力的關鍵一步。他還提到,Open-Sora未來的發展方向主要在於 完善數據處理流程 以及 訓練影片壓縮Encoder 。
以下為尤洋的演講實錄:
我演講的主題是最近做的Open-Sora,希望幫助更多中小企業以及研究人員去快速地復現類似Sora這樣的影片生成模型。
首先簡要介紹一下我的技術背景。這張照片拍攝自我博士畢業答辯時,圖中的人物包括我在加州大學柏克萊分校的幾位教授,他們的專業背景主要集中在高效能計算(HPC)和電腦視覺(CV)領域。HPC的目標是提高模型訓練的效率,即用成百上千的處理器卡來加快訓練速度。CV則是影片生成模型的關鍵技術之一,這與我的個人技術背景非常相似。

目前,我們了解到大模型對計算能力的需求非常高,特別是在今天的Infra專場中,我們可以預見, 未來對算力要求最高的模型可能會是影片生成模型 。
今天我的分享旨在拋磚引玉,我認為 影片生成模型目前還處於一個相對早期的發展階段,其情形有點類似於影片領域的GPT-2時期 。市場上尚未出現一個完全成熟且廣泛可用的影片生成套用。因此,我將分享我們在這一領域的一些初步探索成果,並希望這能激發大家的興趣,進而深入探討。
本次演講將分為幾個部份。首先,我會簡單介紹Open-Sora模型,以及與之相關的OpenAI Sora。需要明確的是,盡管我們稱之為Open-Sora,也確實采用了類似於OpenAI技術報告中類似的技術,但它 實際上是一個不同的模型 。然後我將介紹Open-Sora的技術要點、效能表現,以及我們對未來發展的規劃。
一、未來人人都能成為導演,影片生成有顛覆教育和技術傳播的潛力
大家都看過Sora的Demo影片,其效果確實令人震撼。未來,我們可能會進入一個每個人都能成為導演的時代,每個人都能夠迅速生成自己想要的影片或故事,並且透過影片這種形式進行學習,這很可能比傳統的文字學習效率要高得多。
如果我們需要了解某個問題,能否讓AI為我們生成一段影片,以便快速掌握相關知識呢?我認為影片生成技術有潛力顛覆教育和技術傳播領域。
在Sora模型之前,市場上已經存在一些影片生成工具,例如Pika、RunwayML、Stable Video等。然而,Sora在影片長度上實作了顯著的突破,超越了之前所有頂尖產品,因此其效果還是非常驚艷的。Sora的套用前景非常可觀,可以涵蓋遊戲、藝術、媒體創作、藥物研發、市場行銷和教育等多個領域。甚至在未來,許多物理模擬領域也可能采用影片生成模型。
盡管如此, 影片生成技術目前尚未廣泛普及 。我們希望能大幅降低制作電影或影片的成本。以今天的標準,制作一部優秀的電影可能需要高達五千萬美元的投資,這顯然限制了普通人參與的可能性。但如果未來有了先進的影片生成模型,我們只需向AI描述我們的想法,它就能為我們生成一部高質素的動畫片或電影。
只有達到這樣的水平,影片生成模型的真正價值才能得到最大化的體現。
二、介紹首個類Sora開源影片生成模型,成功復現Sora有四個關鍵要素
在介紹了Sora及其影響力後,第二部份介紹一下Open-Sora。
Open-Sora 是一個開源的影片生成模型專案,我們的目標是將模型的重要部份都公之於眾,以便社區能進一步發展這一技術。

要成功復現影片生成模型,主要包括幾個部份。
首先,需要了解模型的架構 ,比如我到底用的是Diffusion、Llama、GPT還是BERT,不同的架構決定我模型基本的骨架。
其次 ,一旦模型訓練完成, 分享訓練得到的權重 也是非常重要的。這意味著其他人可以直接拿來用,而不需要從頭開始訓練模型。例如Meta剛剛開放了Llama 3,盡管4000億參數版本還沒有完全訓練完成,但已經可以從中看到很好的效果。透過分享這些權重,社區可以快速地將模型部署到各種套用中。
透過這種開放的方式,我們希望能夠促進影片生成技術的創新和普及,讓更多有興趣的研究者和開發者能夠參與進來,共同推動這一領域的發展。
第三 點非常關鍵,它涉及到 開源模型的透明度和可控性 。
雖然現有的一些開源模型,如Llama 1和Llama 2,已經公開了模型參數和使用方式,但它們並沒有公開訓練過程的具體細節,包括超參數的設定。這導致了我們無法完全復現其預訓練過程,也就是說,模型的預訓練並不是百分百自主可控的。
我們認為, 如果未來的影片生成大模型能夠實作百分之百的自主可控,那麽將能更有效地激發和調動整個行業的生產力 。
此外, 數據處理 也是決定模型效能的一個關鍵因素。
透過審視OpenAI的技術報告,我們可以發現,盡管在模型架構和演算法方面,OpenAI並沒有特別強調其創新性,沿用了如Video Diffusion等現有模型,但OpenAI在數據方面做得非常出色。 高質素的數據是決定影片生成效果的直接因素,因此,數據處理方式和數據集的質素極為關鍵。
三、解讀STDiT架構核心思想,將成本控制在1萬美元
我將展示一些我們的demo和教程,這將涵蓋開源模型的幾個重要組成部份。
從技術角度來看,Open-Sora模型采用了 STDiT 架構。我們選擇STDiT的主要原因是考慮到 成本效益 。我們的目標是將Open-Sora的成本控制在 1萬美金 或者更少。
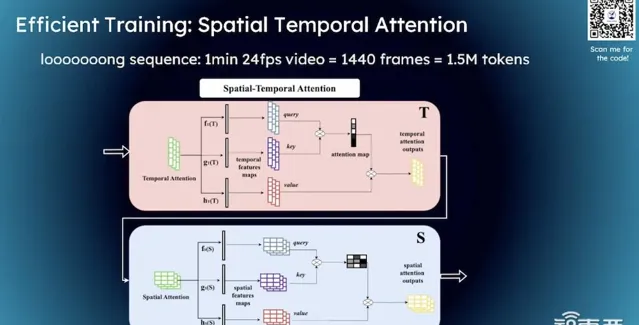
STDiT架構的核心思想在於它包含時間維度的Self Attention和空間維度的Self Attention,這兩個方面是分開處理的,而不是合並計算,這樣的設計可以顯著降低模型的訓練和推理成本。 相比於DiT模型,STDiT在成本上有著顯著的優勢,而且在相同的硬件條件下,其吞吐量也更高,這對於提升模型效率來說是非常有利的。

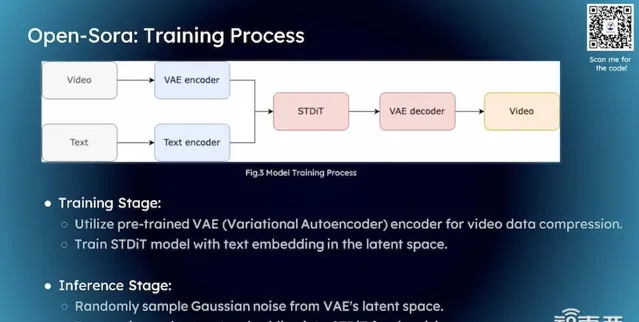
在架構方面,我們的創新點並不是特別多,核心思想仍然與DiT的架構相似。具體來說,處理影片的流程是這樣的:首先,我們獲取一個影片,然後透過Encoder將其壓縮到Latent Space中,這樣影片就可以在這個空間中進行互動和處理。這種方法實際上與文本到影像生成的技術非常相似。
我們對文生圖的概念並不陌生。我們首先對影片進行壓縮,目的是為了將其轉換到潛在空間中。 壓縮有兩個主要目的 :首先,原始影片檔可能非常大,直接處理它們成本太高;其次,我們的目標是生成特定的影片內容,比如一只狗在雪地裏追雪球的場景。如果我們不進行壓縮,而是直接在原始影片上操作,可能會生成不符合要求的內容,比如生成了一只老虎或一只貓,即使影片質素再高,如果內容不是我們想要的,那麽這樣的結果顯然是不可接受的。
透過這種方式,我們可以更有效地控制影片生成的過程,確保生成的影片內容符合我們的預期和需求。 這種方法不僅降低了處理成本,而且提高了生成影片的準確性和相關性。
在潛在空間中,我們需要融入人類的指令,這些指令通常透過自然語言處理來實作。然而,自然語言數據類別並不能直接與影片資訊進行互動。因此, 潛在空間的第二個關鍵作用是將自然語言也轉換到這個空間中 。這樣潛在空間就包含了視覺資訊和文本資訊,使得這兩類資訊能夠在該空間內進行互動。這是我們壓縮影片並將其轉換到潛在空間的兩個主要目的。
完成這一過程後,我們的工作流程與文本到影像生成技術非常相似。文本到影片生成本質上是文本到影像生成的一種擴充套件,因為影片可以被視為一系列圖片的集合。在這種情況下,我們仍然需要借鑒許多文本到影像生成的技術。
具體到實作方式,與擴散模型的做法非常相似,我們透過引入 高斯雜訊 來生成所需的影片。首先,在潛在空間中隨機采樣一個高斯雜訊,然後將這個雜訊與人類的指令一起輸入模型,模型據此生成影片。最後,我們將生成的影片從潛在空間解碼回原始的三維空間,完成整個生成過程。
四、影片生成模型三階段:影像預訓練,影片預訓練,高質素影片數據微調
至於如何實作這一技術,考慮到成本的壓力,我們可以將其分為 三個階段 進行。
盡管今天介紹的技術在未來十年或二十年可能會被新的技術所取代,但在當前算力有限的情況下,我們可能需要采取分階段的方法來訓練高質素的影片模型。直接使用高質素影片數據訓練影片模型的成本可能高達數千萬甚至數億美元,這顯然限制了大多數人參與的可能性。
在成本受限的現實條件下,我們的策略是,首先找到一個不錯的文本到影像生成模型,這類模型目前比較容易獲取,市場上也有很多選擇,當然我們也可以自己訓練一個。
第二階段,有了文生圖模型,再給它大量影片做初始訓練,讓它對影片世界有很好的理解。
第三階段,用高質素、精挑的影片提升它的影片質素。這種思想在大模型領域已經用了七八年,早在2018年、我們訓練BERT的時候,BERT訓練也是分兩個階段,第一階段sequence是128,第二階段的sequence是512。短序列上讓它對自然語言有基本的理解,再在長序列上微調,給它一個更好的生成效果,這些其實都是出於成本的壓力才這樣操作的。
理論上我們有無限算力的話,我們應該直接拿最好的數據讓它去訓練。包括Llama、GPT,它們訓練時也都參考了類似的思路,先在短序列上大規模訓練,之後再在長序列或者更好的數據上去做微調,提升最終的模型生成質素。
具體而言,我們可以看一下三個階段究竟是 怎麽操作的 。
第一個階段還比較簡單,現在有很多文生圖的模型,即便不自己訓練,也可能找一些不錯的文生圖模型,它其實就是我的基準,我從起點開始去構造我的整個方案。我們改造Stable Diffusion,可以快速把這件事完成。

第二階段,現在有了基本對三維世界的理解,文生圖本質上還是對自然語言指令資訊轉到三維世界,有一個基本的能力之後,現在我希望它每秒鐘能生成很多圖,每秒鐘生成60張圖就是一個影片了。這種情況下,再進一步給它很多影片數據讓它訓練。
我們的創新點有兩部份,用了STDiT,有時間資訊和空間資訊,我們新加了時間上的Attention模組,因為本身已經有空間上的Attention模組。比如空間上就是S,時間上就是T,現在有一個S和T,S是已經訓得差不多了,T剛剛開始。S相當於是一個初中生,T相當於是一個嬰兒,但現在我們希望S和T都能達到大學生的水平。
有時我們會采用一種 混合訓練 的方法,即將成熟度不同的模型一起訓練。這種方法聽起來可能有些冒險,因為S可能已經相當於一個初中生,而T可能還只是一個剛剛起步的嬰兒。如果將它們放在一起訓練,可能會擔心它們無法跟上對方學習的節奏。
然而,現代的大型模型擁有龐大的參數量,這使得它們能夠透過適當的調整迅速自適應不同的學習速度。在這種情況下,盡管S模型最初學習速度較慢,但T模型可以快速增長,最終兩者都能迅速達到相同的水平,最終都能達到 相當於大學生的能力水平 。
即使我們沒有自己的S模型,也可以利用一些現有的資源。當我們引入T模型後,透過適當的整合和調整,可以顯著提升整體系統的效能。

這種策略體現了深度學習模型訓練的靈活性和適應力,透過合理的設計和調整,即使是成熟度不同的模型也能夠協同工作,最終實作效能的共同提升。
當我們擁有了影片生成模型之後,接下來的第三部份工作是使用更高質素的影片數據對模型進行精調。
這裏的核心區別在於,第三部份生成的影片在質素上將顯著優於第二部份。盡管第二部份的模型已經對三維視覺世界有了一定的理解,但其生成的影片質素仍有提升空間,這也正是我們進行第三階段工作的原因。
在這一過程中,還有一個關鍵點值得註意,即我們在OpenAI的技術報告中發現,他們使用了多模態版本的GPT-4來進行影片描述,但這種方法的 成本較高 。為了降低成本,我們轉而采用了開源的 LLaVA 1.6 模型來進行影片描述任務。LLaVA 1.6是基於E34B數據集訓練的,如果大家對此感興趣,可以進一步了解和探索。
透過使用LLaVA 1.6,我們能夠在 保持描述質素的同時,減少計算資源的消耗 。這種方法不僅有助於提升最終影片產品的質素,也使得整個影片生成過程更加高效和經濟,從而為更廣泛的套用場景和使用者群體提供了可能性。

五、如何將成本降到最低?時空分割是關鍵一步
介紹完整體的模型、演算法、設計流程之後,接下來考慮 如何把成本降到最低 。
要想把成本控制在1萬美金左右,顯然我們不能用太多的GPU,我們可以簡單地做一筆數學計算。現在H800一台月租8萬-10萬人民幣,假設有8台H800,每月的租金就要80萬,如果用20台,每月的租金大概需要200萬。 要想一次性試驗成本控制在10萬以下,只能用8台H800 64個H800GPU,就需要把速度、效率破到最高。
之前我們打造了Colossal-AI系統,從三個角度,高效的記憶體最佳化、N維並列系統、低延遲推理,透過Colossal-AI進一步實作 2-4倍 的加速。
訓練過程中,一個關鍵因素是它們 需要處理的序列長度通常非常長 。無論是國內還是美國的大模型,研究者們都在努力擴充套件模型的序列長度,以期獲得更高的預測精度。以GPT模型為例,其損失函數依賴於一個視窗的資訊來預測下一個詞的概率,視窗越大,即包含的資訊越多,預測的準確性也就越高。
對於影片生成模型而言,即便是較短的影片,其序列長度,這裏指的是幀數,即每秒鐘包含的畫面數量,也可能是巨大的。例如,即便是每秒24幀的影片,如果幀率提高到60,那麽在數據訓練中的長度可能達到150萬tokens,這將導致計算和記憶體開銷急劇增加。
因此, 將時間資訊和空間資訊進行分割處理是非常關鍵的一步 。透過時空分割,我們可以顯著降低計算成本和記憶體壓力。具體來說,這意味著我們不是同時計算時間資訊和空間資訊,而是分步驟進行,先處理時間維度,再處理空間維度,這樣可以大幅提升處理效率。
透過這種方法,我們可以更高效地訓練影片生成模型,同時控制計算資源的消耗,使得模型訓練變得更加可行,即使是在資源有限的情況下。
經過我們的最佳化之後,訓練策略提升了很大。從右圖可以看出,即使在8個GPU上訓練速度也提升了 16% ,尤其在Encoder部份,計算密集型任務也實作了顯著加速。

六、低成本模型能生成20秒影片,Open-Sora已獲得1.4萬個GitHub星標
最後展示下我們的demo。我們的demo遠差於OpenAI,主要有兩個原因:
首先,我們的demo是在 低成本 條件下完成的,OpenAI使用了2000到4000個p00 GPU,花費了五千萬美元到兩億美元,而我們僅用了不到1萬美金進行試驗。在如此有限的預算下,我們取得的效果是可接受的。
其次,我們 沒有使用大量的數據 。通常數據質素越高,生成的影片質素越好。如果我們采用更好的數據集,我們目前的內部版本能夠生成大約20秒的影片。這是一個在成本受限條件下的演示版本,感興趣的朋友可以在我們GitHub頁面上檢視更多資訊。
Open-Sora目前在影片大模型開源領域中是GitHub上獲得 星標數最高的專案之一 。自從我們在3月3日開源以來,已經獲得了 1.6萬個星標 ,使用者群體遍布全球,包括中國、美國、歐洲、印度和東南亞。
我們的發展方向包括完善 數據處理流程 。我再次強調,對於影片生成模型來說, 數據可能是最核心的資產 。雖然演算法大多是公開的,比如STDiT、DiT或Video Diffusion,大家使用的演算法和模型結構相似,結果也不會有太大差異。但是, 如果數據質素有顯著差異,那麽模型的質素也會有很大差別 。因此數據處理流程非常關鍵。
此外, 影片壓縮和編碼也非常重要 ,如何將視覺資訊有效地轉換到潛在空間,以及潛在空間是否能夠準確表達影片內容的所有資訊,這對於模型的推理和學習過程至關重要。
以上是尤洋演講內容的完整整理。











