
國產大模型不再追趕 OpenAI。
作者 | 賴文昕
編輯 | 陳彩嫻
近日(5.7-5.11),第十二屆國際學習表征會議(ICLR)在奧地利維也納的展覽會議中心召開。
ICLR 2024 的論文終審工作自 1 月份啟動以來,共收到了7262篇送出論文,相較於上一年度的 4966 篇,增幅達到了 46.1%,接近翻了一番。
在嚴格的評審過程中,大會最終接受了 2260 篇論文,整體接收率維持在 31%,與去年的31.8%基本持平,其中 Spotlights 和 Oral 兩種類別的論文展示分別有 367 篇(占5%)和 86 篇(占1.2%)論文獲選。
除了論文數量激增外,大模型(LLM)也成為今年 ICLR 的熱門關鍵詞之一。以 LLM 為研究主題的投稿論文數量暴漲,研究團隊來自全球各地,涵蓋多個細分方向,ICLR 也由此吸引了美國微軟、谷歌、OpenAI、Anthropic、Meta,以及中國智譜、百度、面壁等多個科技團隊的參會。
可以說,今年人工智能領域首個舉辦的 ICLR 不僅是一個傳統的學術會議,也是全球工業界大模型團隊正面較量的縮影。ICLR 2024 的截稿日期是2023 年 9 月 28 日,但在過去的大半年,LLM 在 AI 領域依然狂飆不止。
更值得關註的是,從今年的 ICLR 論文成果與演講來看,經過一年的研究,各家在大模型上的研究已經不只停留在「研究 OpenAI」、「追趕 OpenAI」 的階段。
尤其是中國的研究團隊,他們已經不再單純模仿 OpenAI。
相反,LLM 的研究團隊都不約而同地提出了自己對 AGI 的思考。
1
LLM 成為絕對主角
ICLR 是由深度學習領軍人物、圖靈獎三巨頭之二的 Yoshua Bengio 和 Yann LeCun 牽頭發起的,首屆會議於 2013 年在美國亞利桑那州的斯高亞迪斯代爾舉辦。
盡管與 NeurIPS(神經資訊處理系統大會)和 ICML(國際機器學習大會)相比,ICLR 的年資尚淺,但其學術影響力和認可度正日益提升,現已與前兩者一起被公認為機器學習領域的三大頂級會議,參會人數與投稿數量也逐年顯著增加。
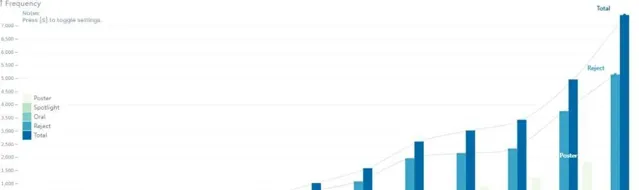
ICLR歷年數據:https://papercopilot.com/statistics/iclr-statistics/
會議召開的前一天,ICLR 2024 的官方網站公布了本年度的獲獎論文名單,特別表彰了 5 篇傑出論文和 11 篇榮譽提名論文。5 篇傑出論文主要圍繞影像擴散模型、模擬人機互動、預訓練和微調、離散蛋白質序列數據的建模與 Vision Transformers 展開研究,其中預訓練與微調就是大模型相關。
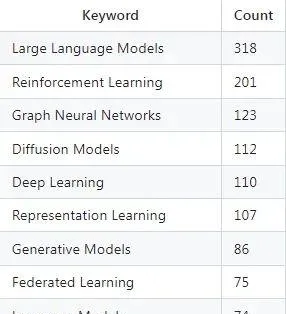
根據 ICLR 公布的接收論文數據,被提及次數最多的前十個關鍵詞分別是:大語言模型(LLM)、強化學習、圖神經網絡、擴散模型、深度學習、表征學習、生成模型、聯邦學習、語言模型與可解釋性。
在這些關鍵詞中,LLM 排名第一,被 318 篇研究提及,與位列第二名的強化學習(201篇)相比,整整多了 1/3,毫無疑問成為 ICLR 的絕對主角。
這 301 篇以 LLM 為研究主題的工作所涵蓋的具體方向也十分廣泛,如關於智能體(Agent)的研究、與強化學習結合、與其他生成模型結合、與三維重建結合、在 NLP 領域的套用、在多模態領域的套用、碳足跡建模等等。
在被 ICLR 接收的 LLM 相關論文中,有不少過去幾個月令人驚艷的新科研成果或產品,比如由深度賦智等中國團隊開發、開源的多 Agent 開發框架 MetaGPT。
MetaGPT 模擬了一個完整的虛擬軟件團隊,包括多個角色如產品經理和工程師,采用標準操作流程,旨在自動化編程任務,解決大模型套用問題,能輸出設計、架構和程式碼。這篇論文在 ICLR 2024 中得到了 8.0 的高分。
普林斯頓大學和芝加哥大學聯合釋出的 LLM 評估框架 SWE-bench 也被選中為 Oral 論文。
這是一個由來自 GitHub 中真實的 2294 個軟件工程問題以及 12 個流行的 Python 儲存庫中的拉取請求所組成的評估框架,透過給定程式碼庫以及要解決的問題的描述,測評 LLM 編輯程式碼庫解決問題的能力。
解決 SWE-bench 中的問題通常需要同時理解和協調多個函數甚至是檔之間的更改,呼叫模型與執行環境互動,處理極長的上下文,並執行遠超出傳統程式碼生成任務的復雜推理。可以說,這個測評標準的出現,讓市面上大模型的效能比拼有了更直觀的數據。
此外,還有MIT、港中文及輝達提出的超長上下文 LLM 高效微調方法 LongLoRA 。
這是一種十分有效的微調方法,透過稀疏的局部註意力進行微調, LongLoRA 實作了上下文擴充套件,節省了計算量,並具有與普通註意力微調相似的效能。
ICLR 2024 還出現了 LLM 與碳足跡的新穎結合。來自印第安納大學與積遜州立大學的研究團隊發現,能在訓練前預測新神經網絡的碳足跡的工具 mlco2 存在局限性,如無法估算密集或專家混合(MoE)LLM 的碳足跡,忽視關鍵架構參數,僅關註GPU,且無法對具體碳足跡進行建模。
為解決這些局限,他們開發了一種專為密集和 MoE LLM 設計的、端到端碳足跡預測模型,顯著提高了 LLM 碳足跡估算的準確性。
關於 LLM 與三維重建的結合,澳洲國立大學與 Adobe 研究中心提出的 LRM,能夠在短短5秒內從單個輸入影像預測物件的3D模型。
與以往在小規模數據集上訓練的方法不同,LRM 采用高度可延伸的、基於 Transformer 的架構,擁有5億個可學習參數,並可以直接從數據集預測神經輻射場(NeRF)。研究團隊在大約包含100萬個物件的海量多檢視數據上以端到端的方式訓練了 LRM,包括來自 Objaverse 的合成渲染和來自 MVImgNet 的真實截圖。
無論是 MetaGPT 還是 LongLoRA,國內大模型的研發人員均參與其中,放眼望去,入選的華人作者更是比比皆是。
而來到 ICLR 2024 的大會現場,中國的大模型初創團隊如智譜 AI,互聯網科技大廠如字節、百度、美團、華為、螞蟻的身影更是遍布在展會各處,在 32 個參會企業中占領了其中的 6 席。
Keynote 演講中,智譜等來自中國的大模型公司也作了深入分享,吸引了來自國內外 LLM 參會者的廣泛關註。

不難發現,中國團隊已成為大模型研究熱潮中不可忽視的主力軍。
2
從 ICLR 看見「中國 AGI」
2023 年 ChatGPT 引爆大模型熱潮後,AGI 就成為了備受關註的焦點議題。如何通往 AGI,成為了無論是技術驅動、產品驅動還是商業驅動團隊都要爭相回答的問題。
從 GPT-3 到 GPT-3.5,從 ChatGPT 到 GPT-4 與 GPT-4V,OpenAI 的下一步「GPT-X」一度成為行業最熱的話題猜測,並曾被狂熱地視為「LLM 的下一步」。
然而,隨著越來越多的研究者加入,中國的大模型研究者開始批判思考「OpenAI 模式」與「GPT 路線」。據 AI 科技評論與多個中國大模型團隊的交流,他們越來越相信,如果一味追趕 OpenAI,那麽「我們將最多成為 OpenAI,卻無法超越 OpenAI」。
比如,有大模型團隊指出,大模型不具備「智能湧現」的能力,一味追求透過擴大模型規模來實作模型智能的路線風險極高,大模型要透過具體的產品與服務來實作價值。2023 年史丹佛團隊獲選 NeurIPS 最佳論文的工作「Are Emergent Capabilities of LLMs a Mirage?」就指出,大模型的智能湧現能力也許是錯覺。
OpenAI 的單向路線以及過度依賴長序列的方法,也引起行業的反思。以長文本為例,如果說大模型的目標是實作 AGI,那麽從 AGI 的終極目標倒推,AGI 所應包含的能力並不是 OpenAI 大模型的現有架構所能很好解決的。類比人類的能力,人會透過多次做一件事、越做越熟練,且掌握一項技能(如騎單車)後就不會遺忘,但目前的大模型並不具備類似人的這種「經驗性記憶」,長文本與長序列目前也沒有顯示出表達這種能力的潛力。
相比模仿 OpenAI,中國的大模型創業者開始趨於從 AGI 的第一性原理出發,思考一條獨特的、同時符合中國市場與服務的技術路線。
即使是被外界視為從模型到產品全面對標 OpenAI 的智譜 AI,在如何實作 AGI 的路徑上也有與 OpenAI 不同的思考。這一差異在智譜團隊於 ICLR 2024 大會現場發表的主旨演講內容中可見一斑。作為唯一受邀作主旨演講的中國 LLM 團隊,智譜在 ICLR 圍繞「ChatGLM 的 AGI 之路」分享了團隊的獨特思考。
盡管模型矩陣與 OpenAI 相似,但智譜的 AGI 核心與路徑卻大大區別於 OpenAI。
從2019 年開始,智譜的大模型研究以「認知」(Cognition)為核心,借鑒人類思維,將模型的能力研發分為負責快速直覺的「系統 1」與負責慢速邏輯的「系統 2」。這借鑒了 Yoshua Bengio 最早提出的「System 1」與「System 2」理論。
智譜的思考是:系統 1 以 LLM 為核心,能迅速響應簡單問題;系統 2 則采用知識圖譜構建,能處理復雜的推理任務,建立短期和長期記憶,還具備無意識學習和自我管理等功能。這是為了讓電腦程式能像人類運用左右腦一樣,既能快速回答簡單問題,又能透過推理回答復雜問題。
此外,智譜的 GLM 大模型采取雙向自回歸路線,而 OpenAI 的 GPT 系列采取單向自回歸路線。雙向自回歸的特點是:在生成 token 時,GLM 可以只關註單側的上下文;在采用隨機化的 token 控制策略處理已知 token 時,GLM 又能同時考慮兩側的上下文,實作對單向和雙向註意力機制的雙重管理。
這相當於將 BERT 的填空功能與 GPT 的生成能力相結合,透過自回歸的方式做「完形填空」。因此,在某些任務,GLM-130B 的效能能超過 GPT-3。
此外,智譜的大模型技術團隊還認為,人類大腦具有多模態的感知與理解能力,以及短期和長期記憶能力以及推理能力的組合。因此,視覺語言模型(VLM)也是通往 AGI 不可缺少的一環。
CogVLM 就此誕生。這是一個開源的影像理解模型,旨在彌合 LLM 與視覺編碼器之間的差距。透過將文本資訊與視覺編碼相結合,並對該組合模組進行訓練,CogVLM 實作了文本與影像間精確的對映,極大地提升了模型對視覺內容的理解和生成能力,也被用於 Stable Diffufion 3 的影像標註。
技術團隊還研發了一個創新級聯框架 CogView3。作為第一個在文本到影像生成領域實作級聯擴散的模型, CogView3 在人類評估中比當前最先進的開源文本到影像擴散模型 SDXL 效能高出77.0%,推理時間卻僅為其大約一半的長度,其蒸餾變體在效能相當的情況下,甚至只需 SDXL 的1/10的推理時間。
隨著 CogVLM 的加入,GLM-4V 也投入了使用,無論是面對包含世界常識的圖片還是需要理解推理的圖表,GLM-4V 都能提供言之有物的回復。
為了讓 GLM-4V 能自動產生不同的功能,如增加長文本的模式以儲存長期記憶,或從反饋中不斷自我學習完善,GLM 大模型技術團隊開發了能為 LLM 啟用通用代理(Agent)能力的 AgentTuning。
此前,大模型訓練是透過輸入數據讓其不斷學習和微調,但這個方法的缺點是它無法推廣至其他更廣泛的情況。而 AgentTuning 只需用少量案例和有限的標記數據,就可以將訓練好的模型推廣到不同的模型之中。
與此同時,大模型的「湧現能力」同樣是智譜技術團隊一直在探索的問題。在 LLM 烈火烹油的幾年間,Scaling Law 被封為鐵律,不少人認為模型大小與訓練數據量的增加才能讓模型「智能湧現」。
OpenAI 科學家 Jason Wei 於2022年在機器學習期刊 TMLR 上發表了論文,提出 LLM 湧現能力中的某些能力僅在大模型中顯現,小模型並不具備,因此大模型的新興能力無法僅憑小模型的效能來預測,而增加模型的規模後,新興能力自然會呈線性提高。
而智譜在不久前釋出的研究卻提出了一個新的理解:損失(Loss)才是湧現的關鍵,而非模型參數。
將訓練損失標為 X 軸、模型效能標為 Y 軸後,研究人員發現,如果訓練損失達到了2.2的閾值,模型效能就會攀升。由此可見,模型的「湧現能力」除了與模型大小、訓練數據量緊密關聯,也可能源自於訓練損失。

論文地址:https://arxiv.org/pdf/2403.15796.pdf
可以預見,GLM 系列將迎來新升級,GLM-4.5 及其後續版本將融合超級智能(SuperIntelligence)和超級對齊(SuperAlignment)技術,在增強模型的安全性的基礎上構建全面的多模態模型。而這些成果的叠代,都是源於一個團隊的創新思考。
在 ICLR 大會演講中,智譜提出了自己的 AGI 思考:
首先是在文本這一最關鍵的智能基礎上混合影像、影片、音訊等多種模態,將 LLM 套用於聊天、OCR 辨識等場景中;接著開發虛擬的 Agent 來協助使用者完成多種任務,再之後是開發能與現實世界互動並得到其反饋的 Agent,接下來甚至可能是機器人,透過機器人和現實世界互動後得到真實反饋、以進一步實作 AGI……
智譜團隊還提出了一個有意思的概念:GLM-OS。
在他們的設想中,這是一個以大模型為核心的通用計算系統,能利用現有的 All-Tools 功能,結合記憶和自我反饋機制,模擬人類的計劃-執行-檢查-行動(Plan-Do-Check-Act, PDCA)迴圈,實作自我最佳化。這一設想引起會議觀眾的熱烈關註,也展示了中國大模型團隊的前瞻性與思考力。
最後,團隊分享了自2019年起研發的 GLM-zero 技術,該技術探索了類似人類在睡眠中仍進行學習的無意識學習機制,涉及自我引導、反思和批評,旨在深化對意識、知識和學習行為的理解,也代表了 AGI 的重要一步。
值得關註的是,在今天,能呼叫以上技術 API 的智譜大模型 MaaS 開放平台(bigmodel.cn)就大幅降價,其中最具性價比的基座大模型 GLM-3-Turbo 模型的呼叫價格下調80%,從之前的1元可以購買 20萬 tokens變為1元可以購買 100 萬tokens,新註冊使用者獲贈還從 500 萬tokens提升至 2500 萬 tokens(包含 2000 萬入門級額度和 500 萬企業級額度)。

3
寫在最後
今天,Sam Altman 預告 OpenAI 將在 5 月 13 日釋出新產品,既不是萬眾期待的 GPT-5,也不是前段時間廣為流傳的 ChatGPT 搜尋引擎產品。在海內外大模型仍在追趕 GPT-4 之際,OpenAI 又要開拓新的版圖。
「追趕 OpenAI,成為 OpenAI,超越 OpenAI。」這似乎已成為國產大模型的魔咒。
但在過去一年,智譜 GLM-4、阿裏 Qwen-Max 與百度文心一言4.0等國產大模型在各類評測榜單表現亮眼,躋身於國際舞台。此次 ICLR 大會現場的 LLM 成果就已表明,2024 年,「追趕 OpenAI」不再是中國大模型公司的核心,「超越 OpenAI」與商業化落地才是國內團隊的目標。
對比 2012 到 2022 的深度學習十年,我們不難發現,大模型時代的 AI 發展周期在不斷加快。在加速的技術周期中,技術從研發到商業的距離也大幅縮減,對創新者也不斷提出了新的要求。
「沒有第二個 OpenAI」,但有「第一個 ChatGLM」、第一個文心一言、第一個通義千問……也許從前國內行業觀察者信心不足,但 ICLR 2024 結束後,國產大模型的力量走出國門,能與國際知名的 LLM 公司較量——這一事實,會更加振奮國內 LLM 的信心。
本文作者 anna042023 將持續關註AI大模型領域的人事、企業、商業套用以及行業發展趨勢,歡迎添加交流,互通有無。











