存算一體:GPU大型計算系統

1.存算一體技術在GPU領域的落地通道已被產業巨頭打通,加速了其套用部署。
2.采用20nm工藝結合HBM-PIM,僅需7nm集群即可實作2.5倍的計算效能提升,大幅超越未使用HBM-PIM的傳統HBMGPU。:產業巨頭已經打通存算一體技術的落地通道,存算一體技術加快套用部署。與未使用HBM-PIM(HBM-PIMGPU v.s. HBM GPU)相比,僅用20nm工藝就使7nm集群計算效能提升了2.5倍。
三星電子引領數碼存內處理新時代,打造高效計算系統。HBM-PIMGPU系統搭載世界上第一個基於數碼存內處理的芯片,效能大幅提升。這一革命性創新賦能人工智能、機器學習等領域,帶來更強大的計算能力。三星電子在計算技術領域再創輝煌,引領行業發展。12 月12日宣布,他們開發了世界上第一個基於數碼存內處理(PIM,也可稱存內計算或存算一體)芯片(HBM-PIM)的GPU的大規模計算系統。

三星電子揭示存算一體技術的新進展
在2022人工智能(AI)半導體未來技術大會上,三星電子高等技術研究院人工智能研究中心副主任崔昌圭分享了新計算技術的發展。
他們構建了一個大型計算系統,組合了96個來自AMD的GPU,每個GPU載入一個HBM-PIM芯片,展示了存內處理(PIM)芯片的效能。存算一體技術顯著減少數據在CPU和DRAM之間的移動頻次,提升效能。
該技術有望在人工智能、高效能計算、邊緣計算等領域帶來廣闊的套用前景。ChoiChang-kyu)在由三星電子主辦的2022人工智能(AI)半導體未來技術大會上透過主題演講披露了新計算技術的發展。他們透過組合來自AMD的96個GPU(MI100)構建了一個大型計算系統,每個GPU都載入了一個HBM-PIM芯片,並成功展示了存內處理(PIM)芯片的效能。這是一種存算一體技術,可以顯著減少數據在CPU和DRAM之間移動的頻度並提升效能。

存算一體技術超越傳統馮諾依曼架構
PIM:記憶體計算技術的突破
PIM(Processing-In-Memory)將計算單元與隨機存取記憶體(DRAM)整合在單個芯片上,這項技術有望有助於提高龐大的人工智能(AI)的效能。
三星推出了嚴格意義上的芯片內數碼近存計算,在HBM-PIM芯片的每個儲存塊中均包含一個內部處理單元,與其他公司HBM實作不同,該技術旨在提升AI計算效能。是指將計算單元與隨機存取記憶體(DRAM) 整合在單個芯片上。這項技術有望有助於提高龐大的人工智能(AI)的效能。三星使了嚴格意義上的芯片內數碼近存計算來提升AI計算效能。三星HBM-PIM芯片與其他公司HBM實作的不同之處在於,PIM芯片上的每個儲存塊內都包含一個內部處理單元。
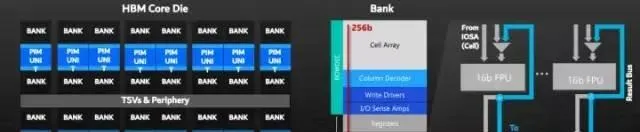
三星HBM-PIM陣列架構
*基於存算一體技術的20nmHBM-PIM(DRAM工藝)大大提升GPU效能。
*與7nmGPU相比,20nmHBM-PIM實作了2.5倍的效能提升。
*這一突破性技術將為高效能計算、人工智能和圖形處理等領域帶來變革。20nmHBM-PIM(DRAM工藝)使得7nmGPU效能增強2.5倍
三星在去年ISSCC釋出的學術文章披露了其HBM-PIM技術,該技術采用三星20nmDRAM工藝,將負責計算的PCU與DRAM陣列整合在同一晶圓平面內。效能提升主要歸功於存算一體技術,而非3D堆疊封裝。
僅使用20nm工藝的PCU進行簡單的邏輯計算,便使7nm工藝GPU集群的效能提升到2.5倍。這意味著,透過將計算和儲存整合在同一個芯片上,可以顯著提升效能。
此外,這種設計還具有功耗低、面積小的優點,非常適合套用於高效能計算和人工智能領域。
三星的HBM-PIM技術有望成為下一代高效能記憶體的主流技術之一。ISSCC釋出的學術文章資訊披露,該HBM-PIM使用的是三星的20nmDRAM工藝。負責計算的PCU與DRAM陣列在同一個晶圓平面內,顯著效能提升主要來自存算一體技術而非3D堆疊封裝。僅用20nm工藝的PCU進行簡單的邏輯計算(DRAM工藝做邏輯計算其實不劃算,外周的邏輯晶體管的實際柵長在32nm附近),就使得7nm工藝GPU集群的效能提升到2.5倍。
三星電子開發了一種名為PIM(Processing-In-Memory)的尖端技術,在提升AI計算效能的同時,大幅降低能耗。
該系統訓練語言模型演算法T5 時,效能提升了2.5 倍,功耗降低了2.67 倍。配備HBM-PIM 的GPU加速器一年的能耗下降了約2,100GWh,相當於減少960,000噸碳排放。
三星表示,該技術將對能源消耗和環境具有重大影響,可減少集群的年能源使用量,減少碳排放。T5(Text-to-TestTransfer Transformer)時,與未使用PIM時相比,效能提升了2.5倍,功耗降低了2.67倍。與僅配備HBM 的GPU加速器相比,配備HBM-PIM 的GPU加速器一年的能耗下降了約2,100GWh。三星表示,其PIM技術將對能源消耗和環境具有重大影響,可將集群的年能源使用量減少,相當於減少960,000噸碳排放。

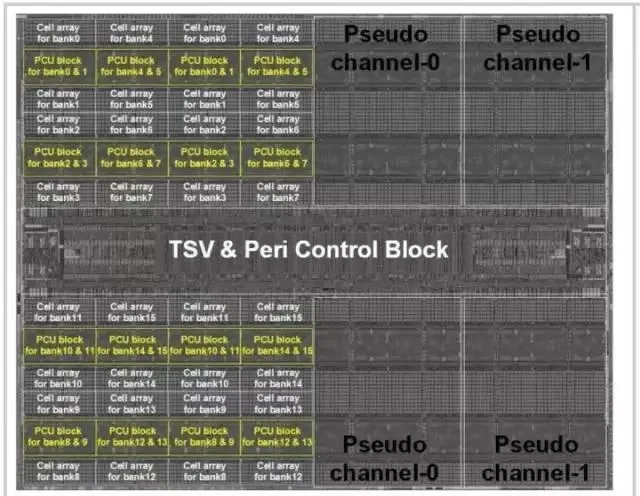
三星HBM-PIM架構圖
三星利用CXL開放標準,連線高速處理器與器材或記憶體,最佳化處理器與加速器之間的協同作業。該技術提高了處理器與記憶體的互動效率,從系統層面提升效能,讓使用者對關鍵套用的體驗更加流暢順暢。CXL(ComputeExpress Link)開放標準,用於高速處理器到器材和處理器到記憶體的介面,從而可以更有效地使用與處理器一起使用的記憶體和加速器。
CXL 與PNM的強強聯合,推動記憶體容量擴充套件新紀元
CXL的出現為記憶體容量擴充套件帶來了革命性的改變。它能夠與其他技術,例如Processing-near-Memory(PNM) 協同工作,實作記憶體容量的突破性增長。
CXL與PNM的有機結合,為數據密集型套用提供了強有力的支持,在AI、5G通訊、雲端運算等領域展現出巨大的潛力。
CXL與PNM的聯手,不僅提升了計算效能,更使記憶體容量實作了前所未有的擴充套件。這將為企業帶來更強大、更靈活的IT基礎設施,激發創新潛能,開創嶄新未來。可以與其他技術結合使用,例如 Processing-near-Memory (PNM),以幫助促進記憶體容量擴充套件。
PNM是一種新型的計算架構,它透過使用記憶體進行數據計算來減少CPU和記憶體之間的數據移動。與PIM 相比,PNM的計算功能在更靠近記憶體的位置執行,從而減少了CPU和記憶體數據傳輸之間的瓶頸。這使得PNM具有更快的計算速度和更高的能效。PIM一樣,它透過使用記憶體進行數據計算來減少CPU和記憶體之間的數據移動。在PNM的情況下,計算功能在更靠近記憶體的地方執行,以減少CPU和記憶體數據傳輸之間發生的瓶頸。
三星在AI領域取得重大突破,推出搭載CXL 的PNM技術。該技術可顯著提升記憶體頻寬,在推薦系統和記憶體數據庫等套用中,效能提升高達一倍。
三星PNM 技術采用CXL介面,可無縫連線伺服器和加速器,實作記憶體頻寬的大幅提升,有效解決AI模型處理中面臨的記憶體瓶頸問題。
在測試中,基於CXL 介面的PNM系統在推薦系統和記憶體數據庫等套用中效能翻倍,展現出強大的處理能力和高效的解決方案。CXL 的PNM技術,用於高容量AI模型處理。在測試中,基於CXL 介面的PNM系統在推薦系統或需要高記憶體頻寬的記憶體數據庫等套用中效能翻倍。
-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-











