【導讀】 在當今人工智能領域, AI 模型以卓越的語言理解和生成能力重塑了我們對智能互動的認知。然而,在其卓越表現的背後,隱藏著諸多尚未充分挖掘的關鍵因素。本文將分享大語言模型訓練過程中產生的多種 獨特 現象,推導在二階段預訓練時如何巧妙平衡數據量與背景知識的註入,從理論與實踐的角度揭示其內在運作機制,深入剖析語言核心區與維度依賴理論的作用及其帶來的深刻影響。
作者 | 張奇
責編 | 王啟隆
出品 | 【新程式設計師】編輯部

自然語言處理領域存在著一個非常有趣的現象: 在多語言模型中,不同的語言之間似乎存在著一種隱含的對齊關系。 復旦 NLP 團隊 在 早期 便開始做了一些相關的工作, 於 2022 年釋出了一篇關於 Mu ltilingual BERT 的分析[1] ,隨後 團隊 持續進行對大語言模型內語言對齊機制、語言與知識結構之間內在聯系的深入研究,並在 AAAI 2024 送出了一份 研究報告,提出了 關於大語言模型中語言對齊部份的 若幹 猜想。 基於 這些研究成果 ,本文將分享一些 大語言模型中語 言和知識分離的現象。

現象 1:mBERT 模型的跨語言遷移
2022 年開始,我們發現 Multilingual BERT 是一個經過大規模跨語言訓練驗證的模型例項,其展示出了優異的跨語言遷移能力。具體表現為, 該模型能夠在某單一語言環境下訓練完成一個部份後,可以非常容易地成功遷移到其他語言環境中執行任務。 這一現象不禁令人思考:模型中是否存在某種特定的部份?為了探索這種多語言對齊的現象,研究采用了 Prompt 搜尋方法對模型逐層分析( 見圖 1 ),針對每種語言的每一層網絡及各個 head(全稱 attention-head,BERT 的基本組成模組 )單元進行了細致研究,旨在考察它們對語法分類任務的執行能力。

圖 1 mBERT 不同層恢復各類語言語法關系的準確性
在針對多語言樣本的測試中,我們選取了每種語言不同層次的部份 head 進行測試,評估它們在語法關系預測任務上的表現。實驗結果顯示了一個較為顯著的現象: 在大規模預訓練過程中,即使未註入任何顯式的語法先驗知識,模型依然能夠在語法結構層面展現出良好的對齊特性,並能在不同層次間保持一定的精度一致性。 這一趨勢在大多數語言中尤為突出,但在某些特殊或較少使用的語言中則不甚明顯。
透過對多種不同語法現象的預測比較,研究著重對比了英語與西班牙語、英語與日語之間的差異。在第 7 層網絡的語法關系視覺化中,數據顯示親緣性較高的語言,其預測位置更為接近且分布趨於均勻。而像英語與日語這樣差異較大的語言,部份語法成分的預測位置相對集中(見圖 2 ),未能有效區分開來。

圖 2 mBERT 第 7 層的不同語法關系表示的視覺化
接下來我們發現了更為不尋常的現象:當針對特定任務對模型進行微調(Fine-tune )時,比如運用 Multilingual BERT 進行任務傾向性分析或命名實體辨識等任務的微調後,模型在處理語法成分的對齊關系及區分邊界的表現會得到顯著提升(見圖 3 )。

圖 3 在進行任務 Fine-Tune 之後,聚合對齊更加明顯
在未經微調的原始模型中,其內部蘊含了大量的語法預測資訊,這些預測主要聚集在模型的中間層級,混合度比較高。但在執行相應的任務預測微調之後,這些預測分布會變得更為清晰、更具獨立性。基於這一現象,可以合理推測 Multilingual BERT 模型上 用單一語言微調特定任務後,其學習到的能力能夠快速遷移到其他語言 的原因。

現象 2:大語言模型同樣存在顯著的語言對齊
鑒於我們已經在上述 2022 年的研究中做了相關工作,並揭示了 Multilingual BERT 中的語言對齊現象,那麽在大語言模型上面,除了 decoder-only 結構的設計改進外,剩下的就是模型的寬度和深度拓展。此現象在 Multilingual BERT 中的存在,自然引起了我們 對大語言模型內部語言對齊和語法-語意對齊特性的探究。
為了更深入地解釋這一問題,我們首先在 2023 年 EMNLP 發表了一篇論文[2] ,不僅在原始 Multilingual BERT 上進行了相應的分析工作,還在 LLaMa 模型上復現了這一現象。研究采用了一系列額外的語言評價指標,諸如 RSA 等,以期望獲得更全面和準確的結論。研究結果表明,該現象在大語言模型上面與 Multilingual BERT 非常類似( 見圖 4 )。若按照先前提出的分層邏輯,模型在語法層面展現出明顯的對齊性,這與我們早期的研究結果高度一致。
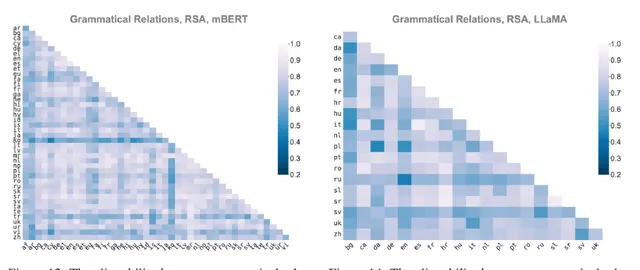
圖 4 語言直接在句法關系上具有很強的對齊性
其次,我們探索了將 Multilingual BERT 上的遷移工作套用到更大規模的語言模型上。具體來說,我們在詞性標註任務(POS tag, Parts-of-speech tagging )上設計了一種特殊的方法( 見圖 5 )。在面對單個語言的小規模數據集時,我們選取了若幹位置,無須任何標註數據,直接使用 Multilingual BERT 的遷移方式,從而在多語言環境中獲得了優秀的標註效果。舉例來說,即使缺乏阿拉伯語的標註數據集,僅擁有英語和法語的數據集,也能成功地遷移到其他語言環境。

圖 5 詞性標註任務,可以透過跨語言訓練得到非常高的結果
所以, 在大語言模型當中也依然存在這種語言對齊現象 。模型已成功實作了詞形(單詞形式,word form )與中間層語意表示、語法表示之間的轉換,脫離了原有的詞形,這一轉換使得模型能夠去 處理別的任務。
透過前面的分析和工作,我們 得出結論, 大語言模型在多語言預訓練階段確實有效地實作了不同語言間語意層面上的對齊。 我們認為, 相較於可能不太重要的形式層面,語意層面的一致性可能是關鍵所在。一旦語意層面實作統一,理論上可以直接應對多種相關的下遊任務。為了驗證這一猜想,我們進一步開展了 一 系列研究工作。

現象 3:知識與語言分離
以下是我們投稿至 AAAI 2024 的論文 [3] 。假設語意層面已經實作了很好的對齊,那麽詞匯形式的具體表達的重要性便會相應大幅削弱。 為此,我們深入探究了如何從 LLaMa 模型出發,將其語言 能力 遷移至其他小型語 種 的過程中,即便面對詞形的變化,模型內部已經具備一層進行語意轉換的能力。
從以英語為主的訓練語言轉向中文或任何其他語言時,實際上的轉換需求就僅限於形式上的改變。通常,將 LLaMA 擴充套件為小語言需要經歷三步( 見圖 6 ): 第一步是詞表擴充套件 (Vocabulary Extension ); 第二步是繼續預訓練 (Further Pre-training ); 第三步是任務添加,所以需要使用 SFT (Supervised Fine-Tuning ) 數據 。
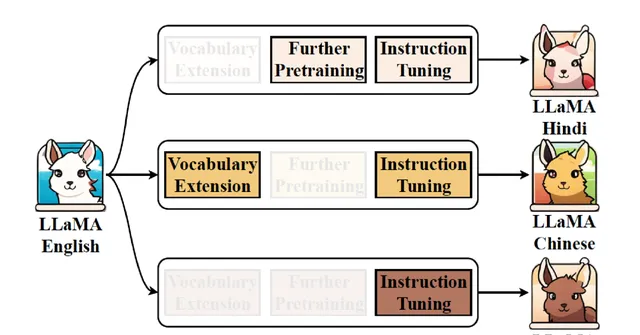
圖 6 將英文 LLaMA 擴充套件為其他語言
為了更清晰地理解這一過程,我們將其分解為三種形式進行觀察。第一種形式是完全不改動詞表,直接進行繼續預訓練和指令微調。第二種形式只進行詞表擴充套件,而不進行其他操作。第三種形式則完全省略前兩步,直接使用大量的 SFT 數據進行訓練。
基於這些設定,我們進行了對比實驗。首先,直接使用 LLaMA 或 LLaMA 2 進行 SFT 訓練,觀察使用經過詞料擴充套件和大規模負責培訓後的效果,例如 Chinese LLaMA、Chinese LLaMA 2 和我們實驗室開源的 Open Chinese LLaMA(經過 200b 數據訓練 )。此外,我們還測試了不進行詞表擴充套件,直接使用 100k 和 1m 數據對中文語料進行 SFT 訓練的情況。
由於評測的目的是模型生成能力,所以我們使用了能提供生成式問答題目的 LLMEVAL 評測方式,基於模型生成數據的正確性、資訊量、流暢性、邏輯性等部份,分別用 GPT-4 進行打分,結果如下(見圖 7 )。

圖 7 Token 擴充套件會導致原始資訊遺失,需要大量訓練才能恢復
因此,以 Chinese LLaMA 為例,恢復資訊需要達到 200 倍以上的二次預訓練數據,這會大幅增加訓練成本。如果使用需求是讓 token 的生成速度變快,我們認為依舊可以擴充套件詞表。反之,若對生成速度沒有特別大的需求,如 LLaMA 根據 UTF-8 編碼生成可能需要 2 ~ 3 個 token 才能產生一個漢字,在只追求生成質素的情況下,直接進行大量中文的 SFT 數據訓練,就已經可以實作非常好的處理效果。也就是說, 詞形和語意在語言層面已經進行了分離,提供其中文能力並不需要特別大量的數據訓練 。在 SFT 非常少量時,大規模的二次預訓練可以加快模型對於指令的響應學習,但當 SFT 數據量擴充套件到 950k 之後,再去增加中文的二次預訓練數據其實並沒有什麽特別的意義,例如在 950k SFT 的情況下,LLaMA 對比經過 1M 中文二次預訓練的 LLaMA 模型,效果並沒有大振幅的變化。
這也是我們之後在語言解釋工作上的基礎: 語言的詞形消失,知識和語言被分離,加入少量的中文數據無法在知識層面提升模型能力 。基於這種思考,我們開始了新的評測(見圖 8 ),其中藍色的部份是 LLaMA-7b 模型,粉紅色的部份是 LLaMA-2-7B 模型,綠色的部份是 LLaMA-13B 模型。我們希望借此看看,在經過大量的訓練之後,模型的知識層面會產生哪些變化。
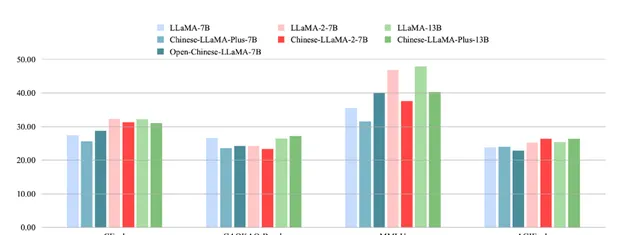
圖 8 使用中文進行二次預訓練並不能在知識層面提升模型能力
在經過 C-Eval、GAOKAO-Bench、MMLU 和 AGIEval 等基準評測之後,觀察到大量未經針對性最佳化的預訓練模型並未顯著提升其內在的知識掌握程度,反而在某些情況下相較於原始 LLaMA 模型有所下滑。這主要是由於目前普遍采用的中文語料庫訓練數據規模有限,進而制約了模型在語言理解和生成方面的效能表現,導致了此類評測結果的出現。因此,如何有效地開展針對中文環境的第二階段預訓練亟需更多思考。單純依賴現有方法,並不能充分反映出模型在特定中文領域知識的進步。值得 註意的是, 僅在現有的通用模型中融入少量涵蓋世界知識或是物理、化學、數學等領域專業知識的中文數據,是沒有太大意義的 。
在其他語言中,我們也做了類似的工 作( 見圖 9 )。 研究選了十幾種語言,每種語言都用相應的 SFT 數 據進行訓練和測試,觀察發現數據達到一定量級,如 65k SFT 之後,都處於相對可用的版本 。 但因 為這些 SFT 數據有一部份是機器轉譯的,不如中文直接使用的效果。

圖 9 在其他低資源語言中表現類似

現象 4:語意和詞形對齊
訓練過程中,我們發現了一些有趣的現象,也可以從一定程度上說明這種語意和詞形對齊的關系。例如,用 95k 的 SFT 對某些進行訓練,並將早前的一些 checkpoint(在訓練過程中不同時間點保存的模型版本)打印出來,並詢問以下問題( 見圖 10 ):

圖 10 訓練過程中非常明顯的 Coding-Switch(語碼轉換)現象
模型在響應查詢時,輸出的部份內容以紅色和藍色標示。我們觀察到,模型能夠在保持語意連貫正確的前提下,自動插入其他語言的詞匯,而且這些詞匯與前面的內容銜接自然流暢,仿佛原本就應該屬於同一句話。這就從某種程度上表明, 模型在內部實作了語意與詞形的解耦,即模型有能力在維持語意完整性的同時,靈活處理不同語言的詞形表達 ,引證了我們前文中的一些猜想。我們做了十幾種語言,每種語言都出現了一定比例的 Coding-Switch 現象,所以這並不僅僅是中文特有的個例。

現象 5:少量的數據就能影響整個大模型
基於上述發現,我們開始深入思考。除了之前觀察到的這些現象之外,其實在大語言模型的訓練過程當中還有很多別的現象,比如「毛刺」( 見圖 11 ),即「噪音」(Noise )。在進行大規模預訓練時,我們自身也進行了 30b 和 50b 參數級別的模型預訓練,同樣發現了類似情況。每當遇到這些噪音數據,我們的解決辦法通常是回溯,回滾到出現問題的預訓練階段,檢查那一階段的數據。多數情況下,我們發現是由預訓練數據所引起的,這部份有問題的數據會導致模型的 PPL(perplexity )值急劇升高。
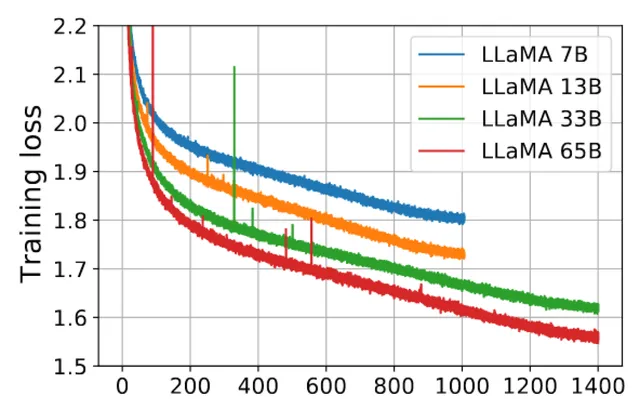
圖 11 「毛刺」
為何少量的數據會對如此大規模的模型造成如此嚴重的影響呢?OpenAI 和 Anthropic 在他們的論文 [4][5] 中均對此有所涉及,他們在研究 SFT 和預訓練相關課題時,大多得出類似的結論: 模型進行兩三輪的微調通常就已經接近最優狀態,過多的訓練輪次往往會導致模型效能下降 。這一結論在我們自身的實驗中均得到了印證。
在傳統訓練流程中,我們可能對某部份數據訓練 30 輪或 50 輪,即便數據質素不高,也只是導致這部份訓練效果不佳。然而,在大語言模型上,當我們引入少量 SFT 數據並進行六輪甚至十輪微調時,整個模型的能力卻可能會急劇下降,且在 SFT 數據上的表現也並未改善。這究竟是什麽原因呢?這一系列疑問驅使我們去探尋深層次的答案,促使我們開始想要開啟黑盒,去對它做更進一步的解釋和分析。
以前,想對人腦的認知功能進行深入分析是很難的,因為直接觀測和測量人腦各區域的功能是不可行,同時現代倫理準則也嚴格約束了對動物(如猴子 )進行復雜神經科學實驗的可能性。例如,我看過一則關於剝奪猴子視覺社交刺激的研究引發爭議,因其可能對動物造成不可逆的影響。
在人工智能領域,BERT 模型的出現雖然為語言處理帶來了重大突破,但其智能程度相對有限,且結構和動態行為相對易於分析。隨著大語言模型的發展,尤其是參數量龐大的預訓練模型,它們展現了更高水平的智能表現,同時也帶來了新的挑戰—— 模型的內部工作機理更加復雜且難以直觀理解 。那怎麽辦呢?我覺得不能像電視劇裏劉華強說的那樣,「給你機會還不中用」。既然有了機會,我們還是得把握住。

大語言模型參數中記錄了知識有明顯的語言核心區
經過先前的一系列分析,我們旨在探究這些現象如何具體表現在大型語言模型的參數結構中,並從參數當中研究出一些解釋和情況。過去半年以來,我們不停地實驗就是圍繞這一目標展開。在某種程度上,這與人腦的功能分區原理相似——人腦中有專門的語言區及核心區,而在大語言模型中也可能存在著負責語言理解與知識表達的部份結構。現在有相當一部份共識,認為一部份知識儲存和處理功能可能對應於模型中的 前饋神經網絡 (Feedforward Neural Network, FFN )部份,尤其是其中的 多層感知器 (Multi-Layer Perceptron, MLP )元件。然而,目前我們的研究結果其實還比較初步,有些實驗結論其實並不一定十分可靠。
研究中, 我們認為大模型中明視訊記憶體在著承載語言能力的核心區域 。為什麽會這麽說?這一判斷基於如下實驗設計:首先,我們選取了六種語言,針對每種語言收集了約十萬條未曾出現在 LLaMA 原始訓練集中的文本數據,這些資料來源自書籍並經由轉換獲取,出現重疊的概率較低。接下來,我們利用這些數據對 LLaMA 模型進行了二次預訓練。
預訓練完成後,我們對比了模型訓練前後參數的變化情況,針對每種語言獨立進行。首先對韓語進行預訓練並記錄參數變化,隨後依次對俄語、越南語等其余語言進行相同操作。實驗中,我們特別關註了權重變化最大的 1% 至 5% 的參數部份,因為直覺上人們通常認為權重變化較大的區域更為重要。經過四個月的研究,我們發現並非權重變化大的區域才最關鍵,相反,那些經過大規模預訓練後變化很小的參數區域才是模型的核心穩定部份。
為驗證這一點,我們進一步做了若幹實驗。我們發現 有非常少數的參數在所有語言二次預訓練中變化都很小 (見圖 12 ),無論在哪一層、哪個矩陣,都有一個顯著的集中區域,其參數變化極其微小,在不同語言上的變化都非常有限。 因此,我們 將六種語言訓練前後參數變化 振幅 累計起來,考察各個位置變化的綜合程度,並挑選出變化最小的 1% 至 5 % 的參數。

圖 12 有非常少數的參數在所有語言二次預訓練中變化都很小
把這部份參數拿出來之後,我們將這些變化極小的參數區域進行擾動實驗。透過 7b 參數規模的模型,我們選取底層變化最小的 3% 參數進行隨機化處理,然後觀察模型的 PPL 指標( 見圖 13 )。實驗結果顯示,當擾動這最小變化的 3% 參數時,PPL 值會顯著上升;而如果我們從模型中隨意選取 3% 的參數進行同樣的擾動,PPL 雖會下降,但下降振幅並不明顯。反之,如果我們對權重變化最大的那部份參數(同樣取 3% )進行擾動,雖然 PPL 會比隨機擾動稍高,但只要擾動那些變化最小的核心區域,PPL 值就會劇烈上升。同樣,我們還嘗試了僅擾動 1% 參數的情況,盡管變化振幅略有減小,但總體影響仍然較大,表現為幾千到幾萬的增量。
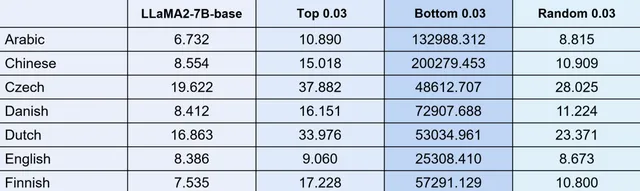
圖 13 擾動核心區域在 130 種語言上 PPL 全都呈現爆炸趨勢
如果用 13b 參數的模型重復上述工作,得到的結論是完全一致的(見圖 14 )。 只要是變動這個區域 3% 的部份,整個模型語言能力基本上就會完全喪失掉了 。
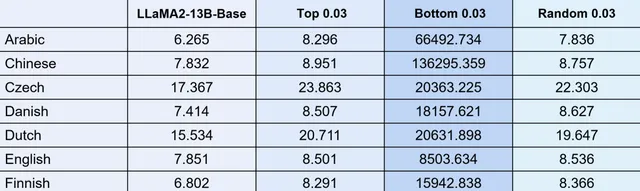
圖 14 LLaMA2-7B 和 13B 現象完全一樣
語言能力區域非常重要,所以我們透過凍結它做了另一個實驗(見圖 15 )。實驗中,我們首先釘選了模型的語言核心區參數,並用中文知乎數據對該模型進行再訓練。另一組對照實驗則是不解凍核心區參數。透過在中文微信公眾號和英文 Falcon 數據集各選取 1 萬條樣本計算 PPL,我們發現:若凍結語言核心區並用 5 萬條中文知乎數據進行訓練,模型的中文 PPL 可以恢復至約 7 左右,表明 模型透過其他區域的參數補償了語言能力;但英文能力在這種條件下無法恢復到先前的爆炸趨勢中 。
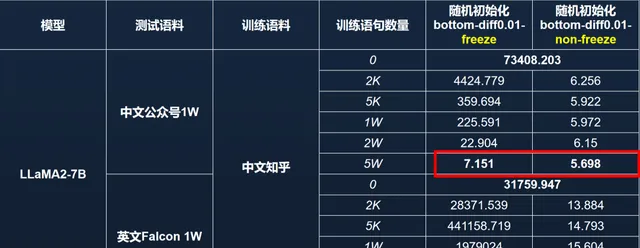
圖 15 模型具備一定的「代償」能力,可以使用中文數據訓練以恢復中文能力
然而,如果僅擾亂而不凍結語言核心區參數,僅透過中文知乎數據訓練,無論是中文 PPL 還是英文 PPL 都能恢復至接近原始模型的良好狀態( 見圖 16 )。 因此,語言核心區的參數至關重要,且對模型能力的影響呈現出平滑而敏感的特點,只需幾千條數據即可相對容易地恢復其原有功能 。然而,一旦該區域被釘選,模型能力的恢復 將變得困難,效能指標會出現顯著變化。
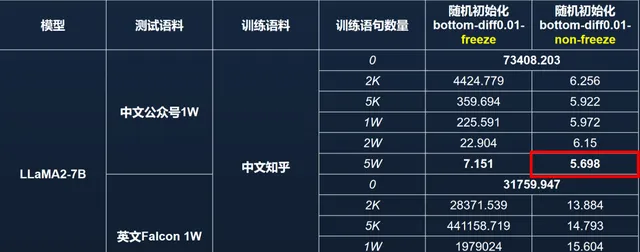
圖 16 在語言區不釘選的情況下,僅訓練中文,英文也能恢復一定能力
觀察打印出的區域(見圖 17 ),可以發現 QKVO 矩陣在維度上具有明顯的集中現象,即主要集中在一小部份維度上。
圖 17 QKVO矩陣都呈現維度集中現象
雖然 MLP 層沒有那麽明顯的集中性,但在進一步放大檢視後,發現在某些列上也存在顯著的現象( 見圖 18 )。
圖 18 FFN-UP & Down某些維度上具有明顯的列聚集現象
例如,在最後一層的 mlp.down 這個區域裏面,少量維度尤其集中( 見圖 19 )。
圖 19 維度集中現象明顯
基於此,我們進一步分析,這種維度集中性與 Layer Norm(層歸一化,Layer normalization )中的單個維度擾動在計算上等效,於是我們嘗試直接擾動 Layer Norm 中的單個維度。
實驗結果顯示,在 LLaMA 2-13B 模型中,如果僅擾動第一層的 input Layer Norm 2100 維度,將其隨機化,模型的 PPL 值會由 5.877 突升至 21.42;若將該值乘以 10,PPL 值則更劇烈地增加到為 3 億多(見圖 20 )。這表明盡管其他 Layer Norm 參數在理論上同樣重要,但擾動它們並不會導致如此嚴重的效能崩潰。然而, 對於這些特定維度,即便是微小的改動也會帶來顯著的效能變化 。
圖 20 擾動實驗
為了直觀展示這種變化,我們用擾動後的模型進行句子補全任務,輸入為「Fudan University is located in」(復旦大學位於…… )。在正常狀態下,LLaMA2-13B 模型能夠輸出高質素的結果,甚至可以處理中英混合,例如直接給出復旦大學官網的連結。然而,如果將 2100 維度的 Layer Norm 隨機化,模型便開始出現知識錯誤和語言錯誤,生成的文本不再正確(見圖 21 )。但同等程度地擾動其他維度,模型的語言輸出卻 不會出現較大變化。
圖 21 僅修改 130 億參數中的 1 個就會使模型混亂
再回來看圖 20,若將 2100 的維度乘以 10,模型的 PPL 值急劇增大,輸出變得雜亂無章。可見,如果在這個特定位置(2100 維度 )改動參數,整個語言模型的功能就會嚴重受損。當然,如果我們對其他位置的參數乘以 10,也會導致一些錯誤,比如模型可能會錯誤地將濟南等地辨識為復旦大學的校區。透過 PPL 指標,我們可以明顯看出這些擾動對模型效能的具體影響,更何況未經擾動的 LLaMA2-13B 模型上本身也經不起多次嘗試導致的錯誤。也就是說, 130 億參數的大模型只改一個參數,整個模型的語言能力就能完全歸零 。
大模型語言核心區與維度依賴理論
這些現象和理論能帶來什麽?其實我覺得它能在構建大模型時提供諸多有益的解釋。以往我們的部份工作采用了一些技巧性的方法,盡管成效顯著,但卻難以闡明其內在機制。
首先,在進行二階段預訓練時,若目標是增強模型在特定領域(如醫學或強化中文知識 )的表現,而原始訓練數據對該領域覆蓋不足,傳統的經驗告訴我們,必須輔以大量相關背景知識的混合數據。例如,在開發 Open Chinese LLaMA 時,我們發現僅添加純中文數據會導致模型效能大幅下降,而現在我們明白參數各個區域負責部份其實已經確定,如果大量增加某類在預訓練時沒有的知識,會造成參數的大振幅變化,造成整個語言模型能力損失。
若要對特定分區進行調整,就必須引入與之相關的背景知識,添加 5 ~ 10 倍原始預訓練中的數據,並打混後一起訓練,這樣才能讓模型逐步適應變化 。否則,一旦觸及核心區域,模型將喪失幾乎所有能力。
其次,大模型語言關鍵區域參數極為敏感,尤其是那些對模型效能至關重要的小區域。 在 SFT 階段,若訓練周期過長,針對少量數據進行多個 EPOCH 的訓練,會造成語言關鍵區域變化,導致 PP L 飆升,甚至整個模型失效。 因此,與小模型不同,不能針對少量訓練數據進行過度擬合 。
第三,模型對於噪音數據的敏感性是眾所周知的,但其背後的原因值得深挖。 比如,預訓練數據中如果出現大量連續的噪音數據,比如連續重復單詞、非單詞序列等,都可能造成特定維度的調整,從而使得模型整體 PPL 大振幅波動。
另外,有監督微調指令中如果有大量與原有大語言模型不匹配的指令片段,也可能造成模型調整特定維度,從而使得模型整體效能大振幅下降。 我們可透過語言核心區和維度依賴理論來解釋這一現象,這意味著 在未來訓練和 SFT 階段,我們需要采取相應的策略進行精細化調整 。
相關 資料:
[1] Xu et al. Cross-Linguistic Syntactic Difference in Multilingual BERT: How Good is It and How Does It Affect Transfer? EMNLP 2022
[2] Xu et al. Are Structural Concepts Universal in Transformer Language Models? Towards Interpretable Cross-Lingual Generalization, EMNLP 2023
[3] Zhao et al. LLaMA Beyond English: An Empirical Study on Language Capability Transfer. AAAI 2024 submitted
[4] Training language models to follow instructions with human feedback, OpenAI, 2022
[5] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Anthropic, 2023











