引言:探索大型語言模型中低秩適應的新方法
在自然語言處理領域,大語言模型(LLMs)的迅猛發展帶來了前所未有的效能提升。然而,隨之而來的是模型參數數量的激增,這不僅導致了調優成本的線性增長,也給在常規硬件上進行微調帶來了挑戰。為了解決這一問題,研究者們提出了一系列 參數高效的調優方法 ,如LoRA,它們透過只調整模型中一小部份參數來實作與全參數微調相當的效能。盡管這些方法能夠降低約30%的GPU記憶體需求,但仍需要計算梯度和進行反向傳播,這對於大語言模型的使用和部署提出了挑戰。
近期,研究者們開始探索 無導數最佳化(derivative-free optimization, DFO)方法 ,以避免梯度計算,並在少量樣本(few-shot)設定中展示出更強的魯棒性。本文提出了一種新的無導數最佳化方法,透過在每個自註意力層前置低秩模組,並交替使用兩種無導數最佳化方法來最佳化這些低秩模組。實驗結果表明,與現有的基於梯度的參數高效調優方法和無導數最佳化方法相比,該新方法在各種任務和語言模型上都取得了顯著的改進,並在記憶體使用和收斂速度方面展現了明顯的優勢。
論文標題:
Derivative-Free Optimization for Low-Rank Adaptation in Large Language Models
低秩適應(LoRA)的挑戰與衍生無導數最佳化方法的誕生
低秩適應(LoRA)是一種參數高效的調優方法,它透過調整模型參數的一小部份來實作與模型調優相當的效能。然而,這一過程仍然需要 大量的計算資源 ,因為它涉及到計算梯度並在整個模型中進行反向傳播。
近年來,研究人員開始嘗試使用無導數最佳化方法來避免計算梯度,並在少量樣本設定中展示出更高的魯棒性。本文的研究者們將低秩模組插入到模型的每個自註意力層,並交替使用兩種無導數最佳化方法來最佳化這些低秩模組。在各種任務和語言模型上的廣泛結果表明,此方法在記憶體使用和收斂速度方面與現有基於梯度的參數高效調優方法和無導數最佳化方法相比,都有顯著的改進。
目前,利用大語言模型的主流方法是透過上下文學習,將模型視為一項服務。這種方法 只涉及前向計算 ,並且需要設計適當的提示或演示,而不更新模型參數。然而,上下文學習需要精心選擇提示和演示,模型的效能完全依賴於所選的提示和演示。
本文研究者考慮到直接使用無導數方法在高維空間中最佳化每層的所有低秩模組可能會減慢收斂速度,於是采用了分而治之的策略。分別最佳化每層的低秩模組,並且引入了一個 線性對映矩陣 。該矩陣將無導數最佳化後獲得的參數對映到每層所需的低秩模組。研究者們根據正態分布初始化線性對映矩陣,其標準差與每層的隱藏狀態相關。
研究者在 RoBERTa-large、GPT2-large和GPT2-XL 上進行了全面的實驗,以評估方法的有效性。結果表明,提出的方法在少量樣本設定中平均在七個自然語言理解任務上取得了顯著的改進。此外,該方法在GPU記憶體使用和模型收斂速度方面表現出明顯的優勢,與現有的無導數最佳化方法相比效能更優。
方法概述:無導數最佳化方法與低秩模組的結合
1. 無導數最佳化方法的基本原理
無導數最佳化(DFO)演算法能夠在 不依賴反向傳播 的情況下處理復雜問題。通常,這些DFO演算法采用采樣和更新框架來叠代地增強解決方案。這些演算法在各種領域都有廣泛的套用,從自動機器學習到強化學習和目標檢測等。
代表性的DFO演算法包括CMA-ES(共變異數矩陣適應前進演化策略)、Fireworks演算法(煙花演算法)、遺傳演算法等。
基於CMA-ES和FWA,研究者提出了兩種無導數最佳化方法用於低秩適應:C-LoRA和F-LoRA。
2. 低秩模組的引入與最佳化策略
研究者首先將模型設計得接近預訓練階段(例如,保持一致的目標函數),透過將每個輸入X轉換為包含標記的掩碼語言模型(MLM)輸入。然後,模型確定用於替換標記的類Y的相應詞匯化器。
在低秩適應(LoRA)和黑盒提示調優(BBT)的成功基礎上,將低秩矩陣整合到預訓練語言模型的每層自註意力模組中。研究者使用無導數最佳化方法來最佳化引入的低秩矩陣參數。LoRA模組由兩個低秩矩陣組成。在訓練過程中,W的參數被凍結,不接收梯度更新,而A和B的參數使用無梯度方法進行更新。
考慮到大語言模型具有低內在維度,研究者進一步使用 兩種無梯度最佳化方法 在低秩空間中最佳化參數。在語言模型的每層自註意力模組中使用無梯度最佳化器(例如FWA和CMA-ES)最佳化向量。然後,這些最佳化後的向量透過特定的隨機投影模組,將其投影到低秩空間。
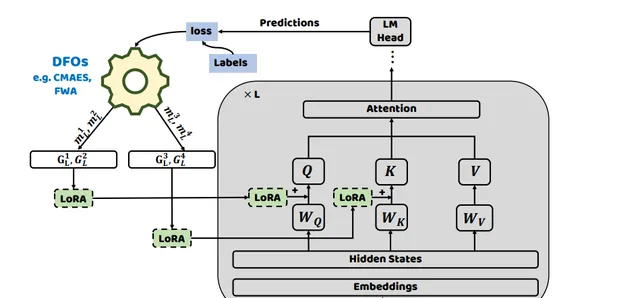
這一過程針對每個模型層分別進行,將最佳化自註意力層連線的低秩矩陣視為子問題最佳化過程。受到分而治之方法的啟發,研究者采用無梯度最佳化策略來最佳化整個模型中引入的參數。
上述模組在模型效能中起著至關重要的作用。研究者分析了 兩種不同的初始化方法 :隨機初始化與正態分布和使用與BBTv2類似的語言模型每層隱藏狀態的分布進行初始化。發現表明,隨機初始化與正態分布會導致語言模型效能略有下降,並減慢收斂速度。
因此,研究者使用語言模型每層的隱藏狀態分布來對模組進行初始化。這種初始化策略有助於保持模型的效能和收斂速度,從而獲得更好的結果。
實驗結果:與現有方法的比較
在RoBERTa-large上的實驗結果表明,研究者提出的方法在七個自然語言理解任務中的平均表現上取得了顯著的改進。與現有的基於梯度的參數高效方法(例如Adapter tuning、LoRA、P-Tuning v2和BitFit)以及無導數最佳化方法(例如BBT、GAP3和BBTv2)相比,本的方法展現了明顯的優勢。此外,在 記憶體使用和模型收斂速度方面 也展現了明顯的優勢。
討論:無導數最佳化方法的優勢與局限
1. 記憶體使用與訓練時間的改進
該方法在 單個NVIDIA 3090 GPU上 進行了實驗,該GPU具有24GB的記憶體。實驗結果表明,與BBTv2相比,該方法在SST2、AG's News和MRPC上分別提高了8.7分鐘、15.4分鐘和7.7分鐘的收斂速度,這表明該方法具有在大語言模型上套用的潛力,提供了參數高效、記憶體高效和更快收斂的優勢。
2. 子空間維度與低秩大小對模型效能的影響
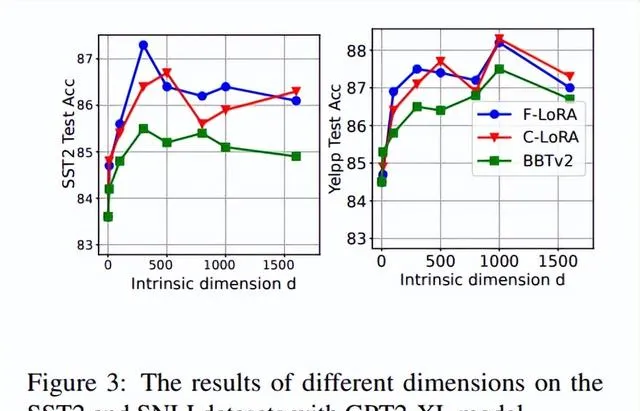
在探索子空間維度對方法的影響時,使用GPT2-XL模型在SST2和SNLI數據集上進行了實驗。該方法在增加子空間維度時始終優於BBTv2。
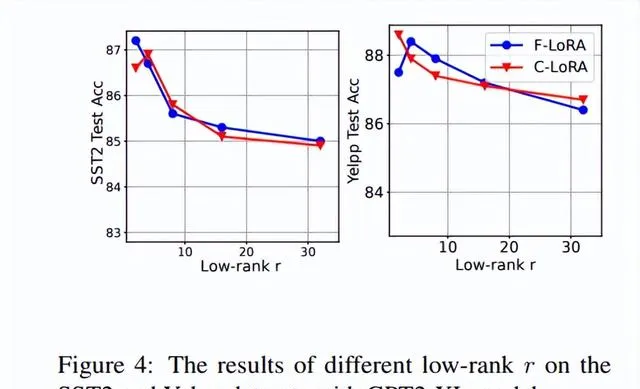
在考慮低秩r對提出方法效能的影響時,研究者在GPT2-XL模型上對SST2和Yelpp數據集進行了實驗。在使用無導數方法最佳化時,模型不需要在高維度上進行最佳化,只需要在低秩r上進行最佳化即可取得良好的結果。實驗中,研究者選擇r=2或r=4,允許模型透過引入非常少的參數來實作良好的結果。
結論與未來工作方向
1. 本研究的貢獻與意義
本研究的意義在於,它為如何在不計算梯度的情況下有效利用大型語言模型提供了一個有前景的方向。不僅提高了模型的穩定性和收斂速度,而且在GPU記憶體使用上也更為高效,這使得它在資源受限的環境中尤為有價值。
2. 對未來大型語言模型最佳化方法的展望
未來的研究可以在多個方向上進一步擴充套件本研究的工作。













