隨著全球能源需求的不斷增長和環保要求的日益嚴格,催化劑的設計和開發成為科學與工業界的熱點。催化劑在能源轉換、環境修復和化工生產中起著至關重要的作用。然而,傳統催化劑的開發往往依賴於反復試驗的「試錯法」,這一過程不僅耗時且成本高昂。因此,如何加速催化劑的開發和最佳化,成為了當今科研和技術領域的重大挑戰。隨著人工智能(AI)和機器學習(ML)技術的發展,數碼化工具在催化研究中的套用逐漸顯現出巨大潛力。
本次綜述【Catalysis in the digital age: Unlocking the power of data with machine learning】深入探討了機器學習如何與實驗數據及理論計算相結合,用於催化劑設計和最佳化。作者詳細分析了當前機器學習在催化研究中的套用現狀、挑戰以及未來發展方向。
機器學習與催化研究的結合:
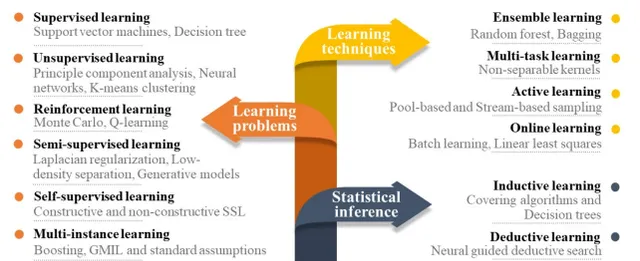
機器學習是一種能夠從數據中學習並作出預測的技術,已廣泛套用於影像辨識、語言處理等領域。近年來,隨著計算能力的提升和數據儲存技術的發展,機器學習在催化研究中逐漸展現出其獨特的優勢。透過對實驗和計算數據的處理,機器學習能夠辨識出催化劑效能與其組成、結構之間的關系,幫助科學家發現更具活性的催化劑。
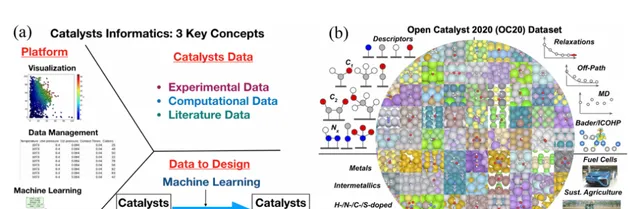
在該綜述中,作者們指出了機器學習在催化研究中的幾種關鍵套用,包括反應預測、材料特性分析和結構最佳化等。例如,機器學習能夠透過已有的催化劑數據,快速篩選出潛在的高效催化劑,並預測其活性、穩定性和選擇性。此外,機器學習還能透過大資料探勘和分析,發現催化劑反應中的關鍵描述符,為催化劑設計提供理論指導。
數據驅動的催化劑開發:
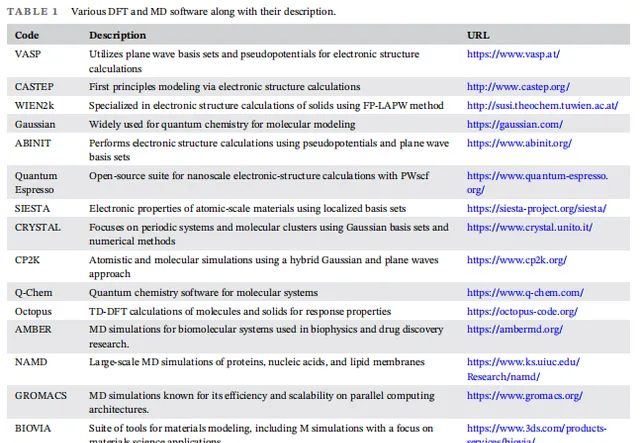
在催化劑開發過程中,數據的質素和數量是決定機器學習模型效能的關鍵因素。透過大規模的高通量實驗、密度泛函理論(DFT)計算以及文獻資料探勘,研究人員可以構建催化劑特性數據庫,利用這些數據訓練機器學習模型,從而預測催化劑的效能。在本文中,作者列舉了多個材料科學中的著名數據庫,例如NOMAD、Materials Project等,這些數據庫包含了大量催化劑的結構、熱力學和電子性質,為機器學習模型的開發提供了堅實的數據基礎。
挑戰與機遇:
盡管機器學習在催化研究中展現出巨大的潛力,但其套用也面臨諸多挑戰。首先,催化劑本身的復雜性對機器學習模型的構建提出了嚴峻考驗。由於催化劑的反應機制涉及多尺度、多維度的動態過程,如何從有限的實驗和計算數據中提取出能反映催化效能的有效描述符,仍然是一個開放的研究問題。
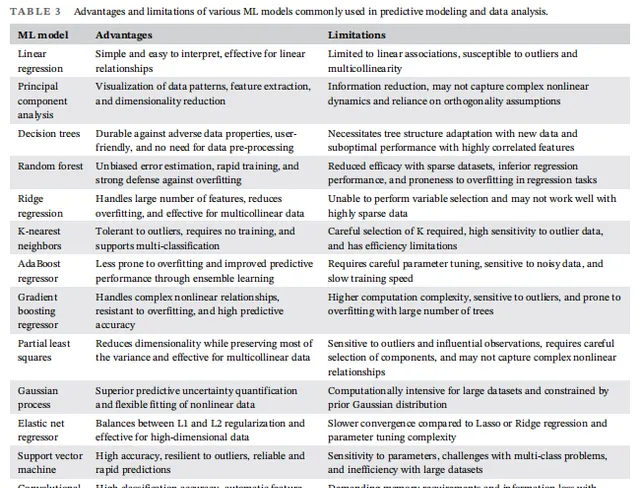
其次,機器學習在催化研究中的套用仍處於起步階段,數據的質素和模型的可靠性是影響研究結果的關鍵因素。為了提高模型的準確性,研究人員需要對數據進行清洗、預處理,並使用交叉驗證等技術來評估模型的效能。此外,催化劑設計中的「黑箱」問題,即機器學習模型難以解釋的預測結果,也是未來亟待解決的挑戰之一。
盡管面臨挑戰,本文的作者們對機器學習在催化研究中的前景持樂觀態度。他們認為,隨著演算法的不斷發展、數據集的不斷擴充套件,以及計算成本的逐步降低,機器學習將成為催化劑設計和最佳化中的核心工具之一。
未來展望:
本文總結了機器學習在催化研究中的套用現狀,並提出了未來的發展方向。首先,作者指出,未來的催化劑設計將更加依賴於數據驅動的科學發現,尤其是在開發高效、低成本的催化劑方面。其次,機器學習將與其他計算工具(如量子力學計算、分子動力學模擬)緊密結合,形成一種多尺度、多物理場的研究框架,從而更好地描述催化反應中的復雜現象。
此外,作者還強調了可解釋性機器學習的重要性。未來的研究應致力於開發更加透明的模型,以幫助研究人員理解催化劑效能與其微觀結構之間的關系。這將為催化劑的設計提供更加直觀和有效的指導。