
雖然大家普遍認為量子力學非常復雜,但這個科學領域,至少允許我們透過實驗去直接向自然界求解。然而,當我轉向經典概率學時,我發現那裏的挑戰似乎更加令人困惑,甚至可以說是一種超越常規的「瘋狂」。在經典概率學中,深層次的理論探索可能會引發更大的混亂和挑戰,與量子力學相比,經典概率學在某些方面可能更加難以理解和掌握。
當科學家或研究者對某個領域或某些理論過於熟悉時,他們可能會變得過於自信,從而忽視其他可能性或新的觀點。這種現象在量子力學的學習過程中尤為明顯,許多初學者試圖用他們所熟悉的經典概率理論來解釋量子力學,這其實是一種誤解,因為概率論本身就是一個極其復雜的概念。
因此,我傾向於將量子力學看作是對現實世界隨機過程的基本模型,這是一個可以透過實驗來驗證的具體領域 。量子力學不僅是理論的起點,也是一個不斷發展中的領域,特別是在解釋量子結果方面。
坦誠地說,我對概率論的理解是有限的,並且我懷疑是否真的有人能完全理解它。
經典概率實際上暗示了量子力學
在量子力學中,有一個來自數學視角的獨特見解,認為量子力學的核心特征—— 振幅( magnitude ) 加法,實際上可能是概率存在的根本原因。振幅加法涉及到量子狀態的疊加,這些狀態用 復數 表示,它們的平方和給出了發現粒子在特定狀態的概率。
在任何自然過程中,所有可能結果的概率之和都是固定的,總是等於1,這說明概率在自然界中的一致性。這個性質與數學中描述向量的平方範數概念相似,即一個向量的各分量平方的和。
將這個概念套用於量子力學,我們可以把量子態想象為一個向量,其分量代表不同狀態的振幅。這些分量的平方和——也就是概率——始終保持不變。 透過將概率論中的「可能性」轉換為量子力學中的「狀態」,我們可以看到這兩個概念之間的緊密聯系,這突出了量子力學對於理解概率本質的重要性。
量子力學中有個至關重要的概念叫 么正算子U(Unitary Operator), 因為它們保持概率總和的不變性。類似地,左隨機、右隨機和雙重隨機(馬可夫)矩陣在矩陣乘法下形成一個群,就像么正矩陣一樣。
馬可夫矩陣,也稱為馬可夫轉移矩陣,是用來描述馬可夫過程中各狀態之間轉移概率的矩陣。在馬可夫過程中,系統的未來狀態只依賴於當前狀態,而與過去的狀態無關。
這些矩陣的特點是它們的行或列元素之和為1,這在描述概率過程中非常關鍵。這些數學概念的結合為理解量子系統的性質提供了深刻的視角。
給定任何作用於有限n維量子空間的么正轉換矩陣U,和一個量子概率幅值狀態向量X,概率(平方大小)位於n×n矩陣下面矩陣的對角線上:
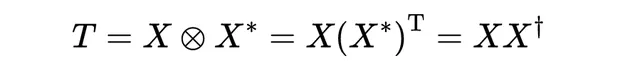
(這裏†代表 復共軛轉置 ),而么正轉換對這個實體的作用是線性的,「旋量」左右作用稱為U的伴隨表示,即
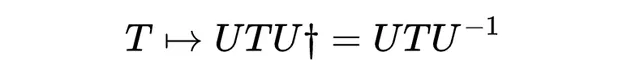
因為么正矩陣的逆是其復共軛轉置。因此,這種伴隨表示是線性的,在矩陣T中保持 跡 不變,即概率(因為U透過相似變換作用)。因此,每個馬可夫矩陣及其對概率向量的線性作用可以由作用於包含該概率向量在其主對角線上的n×n矩陣:
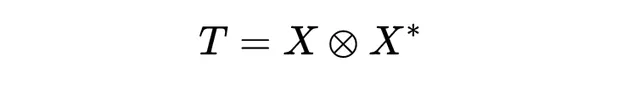
的一整個么正矩陣家族的線性、伴隨表示作用來表示。當然,這種對應關系是高度的一對多(馬可夫矩陣對么正矩陣),因為我們可以將X的元素乘以任意相位因子而不改變T的主對角線。
實值的么正矩陣稱為「正交」矩陣。么正性實質上是指在復數向量空間中,透過保持向量間的復數內積不變,來維持它們的正交關系。這種性質表明,當向量經過么正變換後,它們之間的正交性(即內積為零的關系)得以保持。
我們的概率直覺從哪裏來?
我們對概率的直觀理解,我相信,並非源於對隨機性或隨機過程的理解(這些概念本身就相當復雜和混亂),而實際上更可能來源於我們對測量的本能認知,例如對面積和體積的直觀感受。

在數學中,概率理論的嚴格處理以測度理論為基礎。測度理論提供了一種精確的方式來定義和處理集合的「大小」,這在概率理論中至關重要。在這個背景下,集合的「大小」可以被理解為該集合內元素發生的概率。
測度理論是一個高級的數學領域,包含許多新的和復雜的概念,如 勒貝格積分 。對於只上過一門相關課程的學生來說,這些概念可能會顯得非常難以理解和吸收。盡管測度理論在初學時可能顯得復雜和困難,但其核心目標實際上是將我們對物理世界中的「大小」概念(如長度、面積和體積)進行形式化和公理化。例如,在測度理論中,「面積」和「長度」這些術語被用於描述更一般的集合大小的概念,無論它們是在一維、二維還是更高維度的空間中。
在概率論中,我們將所有可能發生的事件的集合視為一個 測度空間 ,其中每一個點代表了一個特定的事件。更復雜的事件,如由一定規則定義的一組事件,形成了這個空間的子集。為了理解這些事件的概率,我們可以將它們的發生概率想象為它們在測度空間中所占的比例,類似於在一個目標上盲目投擲飛鏢,飛鏢落點代表發生的事件。因此,一個特定事件發生的概率就是這個事件(子集)在整個測度空間中所占比例的大小。

在討論測度空間和相關術語時,這些詞語的具體含義僅在與測度空間的概念相聯系時才成立。這是科學研究的一個常見特點,即透過精確定義術語來消除概念上的不確定性和模糊性。這樣做的目的是為了建立可以透過實驗驗證的清晰模型,確保在科學探究中有一個共同的理解基礎,並使理論可以在實驗中得到檢驗。
許多人自然而然地具有一種理解隨機性的直覺,這種直覺是基於測度理論的。換句話說,即使沒有經過正式的數學教育,很多人似乎能夠本能地把握概率和隨機事件的概念。這種能力可能是人類前進演化過程中形成的,就像一種內建的、與生俱來的特性。
此外,這種對隨機事件的直覺不僅限於人類,對於動物也是非常重要的。動物需要在充滿不確定性和不可控因素的環境中生存下去,例如天氣變化、食物來源的不確定性等。能夠直觀地理解和預測這些不確定性,對於動物做出有效的生存決策至關重要。這樣的能力有助於它們更好地適應環境,提高在自然選擇中的存活率,進而影響它們的前進演化過程。
放棄這種直覺
當你深入探索這種直覺時,你會迅速發現情況變得異常神秘且讓人感到不安。
就像量子力學一樣,概率理論包含了多種解釋和理論框架。盡管傳統教育中通常強調頻率主義這種嚴格的概率定義,但在物理學,特別是理論物理學的發展中,需要采用更廣泛的視角,包括考慮那些尚未發生的事件,如「未拋擲的硬幣」。這要求物理學家們不僅局限於客觀主義的概率觀念,而是更多地融入主觀主義和貝葉斯方法。這些方法為處理不確定性和未知事件提供了更大的靈活性。最重要的是,無論采用哪種概率解釋,都必須透過實驗來驗證這些理論,確保理論物理學的發展與實際物理現象相符合。
頻率主義是一種概率論的解釋和方法論,它定義概率為一個事件在長期重復試驗中發生的相對頻率。根據頻率主義的觀點,概率是一個客觀的量,它反映了特定事件發生的長期趨勢或規律性。
與量子力學不同,概率理論沒有辦法直接透過實驗來測試 。事實上,它在物理學中之所以有效,是因為物理結果對預測它們的概率理論非常不敏感!
熱力學中的手法!
波茲曼在熱力學中對能量分布的推導實際上是基於一種主觀的方法論,這種方法依賴於對稱性的概念。特別是,他使用了被稱為「最大熵」的原則,這是一種理論上的假設,旨在透過假設系統狀態盡可能均勻和隨機來排除任何特定偏好。簡言之,波茲曼的方法強調了在資訊缺乏的情況下,系統傾向於達到可能性分布最均勻的狀態,即熵最大的狀態。

這裏沒有頻率主義的嚴格性。對於熱力學數量級的分子,這種嚴格性將是完全不可能的。
在這個熱力學模型中,我們考慮一個包含N個相同氣體分子的系統,這些分子可以占據一系列特定的離散能量狀態,標記為E_j。這個系統被置於絕熱瓶內,因此系統內部的總能量保持恒定,不會有熱量或能量的流入或流出。我們這裏所討論的是能量狀態的離散化,而不是量子化過程。這種離散化是作為對連續能量譜的一種近似。雖然開始時考慮的是離散的能量狀態,但在進一步分析的過程中,這些狀態可以被視為連續譜的一部份,以便更全面地理解系統的特性。
那麽具有能量E_j的分子數量為n_j。如果所有分子的排列都同樣可能,那麽這種特定排列的概率可以透過多項式分布來找到:
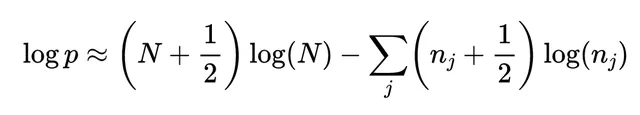
這個近似叫做 斯特林近似 ,它對於熱力學大小的數是非常精確的。由於假設氣體分子數和總能量恒定,我們有約束條件:
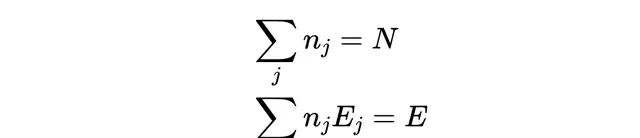
現在我們在兩個約束條件下最大化概率 p(n_1,n_2,n_3,…) 。由於數碼非常大,我們可以將離散的整數視為連續的實數,並簡單地將概率條件與兩個拉格朗日乘數 和 結合起來進行微分,然後將整個方程式組置為零,以找到最大似然或最大熵的波茲曼分布:
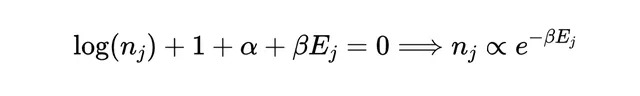
我們將在下面回到為什麽要最大化這個問題的原因。
拉格朗日乘數 的倒數 ⁻¹ 很容易被證明與分子的平均能量成正比,因此我們稱 ⁻¹ 為分布的溫度參數(取模一個用於匹配維度的常數,我們稱之為波茲曼常數 k)。因此,我們通常這樣表示波茲曼分布:
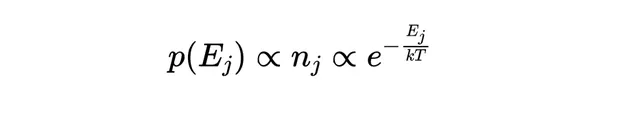
這或許是熱力學中最重要的方程式 。它假設系統的總能量是恒定的,分子的數量是恒定的,並且處於「熱力學平衡」,這顯然意味著系統處於其最可能的狀態。發現並假定一個「最有可能」的狀態具有特定的物理意義是一件有趣的事情,但這究竟是為什麽呢?
最大熵是一個非常溫和的假設
如果你對被普遍認為簡單明了的概率論論點感到困惑,這實際上是合理的。概率論的某些概念可能對初學者來說並不那麽直觀。然而,概率論在套用中通常非常可靠,因為其結果的健壯性不完全依賴於具體的假設或理論分析。特別是在涉及大量數據時,如大數定律所示,概率分布變得更加集中和明確,即使有些初始的理論假設不那麽精確,最終的結果仍然是有效的。

首先,考慮一個簡單的二項概率分布,比如,從一個紅球占比43%的總體中抽樣。如果你抽樣十個,那麽你最有可能得到四個或五個紅球,但得到2個、3個、8個或9個的可能性也非常大,甚至全部或沒有紅球的概率大約是0.1%。這表明,在小樣本量時,結果的變化性較大。
然而,如果取一百萬個球,紅球的數量將是430000,誤差比例非常小,大約是1/√N的數量級,這裏大約是0.001。
這種現象揭示了二項分布隨著樣本量的增大而變得更集中的趨勢,幾乎所有的樣本都緊密圍繞著理論預期的43%分布。這意味著,對於大量樣本,盡管精確獲得43%的紅球的概率很小,但大多數樣本的結果都會非常接近這一比例。這是大數定律的一個顯著體現,表明在大樣本量下,觀測結果會更加接近理論預期,從而提高了統計結果的可靠性。
我見過的幾乎所有推導都忽略了以下這個強有力的觀點:
分布變得「越來越尖銳」,以至於幾乎所有的排列都非常像最可能的那個。在大量粒子的熱力學極限下,出現與最可能狀態在宏觀上明顯不同的情況的概率極低,幾乎可以忽略。
所以,在任何大量粒子的系統中,都存在與最可能的宏觀狀態幾乎完全相同的狀態 , 而幾乎沒有其他狀態 。重要的點不是最可能的宏觀狀態最有可能,而是幾乎所有的宏觀狀態看起來都像這個「最可能」的宏觀狀態! 一個熱力學系統並不是神奇地選擇最大熵狀態,這個系統像一袋錘子一樣笨!它甚至不會寫「熵」,更不用說「找到」它的最大熵狀態了!最大熵就是最可能的狀態,所以它是最有可能發現系統處於的狀態,但肯定還有其他狀態嗎?是的,但當你做數學計算時,你會發現不像最大熵狀態的狀態實際上有多少,真的令人難以置信!
因此,如果由於某種原因,一個系統發現自己處於一個與最可能狀態顯著不同的狀態,那麽它幾乎肯定會透過其相位空間中的任何隨機行走,達到一個與最可能狀態在宏觀特征上幾乎相同的狀態。
在熱力學規模的數量分析中,導致結果穩健和一致的並非是復雜的概率理論,而是大數定律的效應。大數定律指出,在大量樣本的情況下,即使基於不同的假設,得出的結果也會趨向於一致性。這意味著在處理大量數據時,推導的結果對具體的假設細節不太敏感,因為大樣本量本身就足以保證結果的準確性和一致性。因此,這類熱力學推導具有很高的健壯性,可以在多種不同假設下產生相同或相似的結果。











