這專案研究套用機器學習(ML)技術,特別是深度聚類,來自動辨識和分析羅斯冰架上部署的34站寬頻地震陣列(2014-2017年)觀測到的地震訊號。
西南極洲的冰蓋和冰架正在經歷快速變化,這對於預測未來海平面上升和相關社會環境影響至關重要。冰架的地震活動,如冰震,可以提供冰架崩解速率和冰架完整性變化的指示。使用深度聚類技術,透過自動編碼器將頻譜圖編碼為低維潛在表示,然後套用高斯混合模型(GMM)和深度嵌入聚類(DEC)兩種聚類方法來分析潛在數據。研究辨識了八類主導地震訊號,並將其與環境數據(如溫度、風速、潮汐和海冰濃度)進行比較。
發現了在2016年厄爾尼諾夏季,羅斯冰架前緣的地震活動水平最高。在部署期間,靠近前緣的接地區域附近的地震活動也較為頻繁。某些地震訊號類別與季節變化和羅斯島潮汐驅動的地震活動有空間和時間上的關聯。
研究中討論了深度聚類在數據處理、模型設計、數據預處理和後處理方面的靈活性,以及如何透過調整自動編碼器的架構和聚類演算法來進一步最佳化聚類效能。
說明了深度聚類技術能夠自動辨識不同類別的地震訊號,結合環境數據,有助於辨識特定環境因素與地震活動類別之間的關聯。這為大規模地震數據集的探索提供了一種有效工具,並可能成為現有地震數據處理和分析流程的補充。
也說明了深度聚類是一種探索大型地震數據集的有效方法,尤其是在辨識主導地震類別方面。結合非地震環境數據,深度聚類可以幫助辨識或關聯地震源機制。隨著地震數據集的不斷增長,新的機器學習技術將對充分利用這些數據至關重要。
此外,本文提供了如何獲取和處理羅斯冰架的地震數據,文章參照自SCI1區期刊,加入了作者觀點,具體參照連線已放在文末,受制於頭條限制,公式不能完美還原,如不滿,請查閱英文原文。
以下是研究具體內容,「無監督深度聚類在地震數據中的套用:監測南極羅斯冰架」,原文作者:William F. Jenkins II, Peter Gerstoft, Michael J. Bianco, Peter D. Bromirski 機構:加州大學聖地亞哥分校斯克里普斯海洋研究所
摘要: 機器學習(ML)技術和計算能力的進步已經產生了處理、分類和分析大型地震數據集的最新方法。在這項研究中,我們考慮了ML在自動辨識2014至2017年在南極羅斯冰架(RIS)部署的34站寬頻地震陣列觀測到的主導脈沖地震活動類別的套用。RIS地震封包含了許多冰川過程產生的訊號和雜訊,這些對於監測冰架的完整性和動力學非常有用。深度聚類被用來高效地研究這些訊號。深度聚類自動將訊號分組為假設的類別,無需手動標記,允許比較它們的訊號特征以及與潛在源機制的空間和時間分布。該方法使用頻譜圖作為輸入,透過自編碼器(一種深度神經網絡)將它們的重要特征編碼到低維潛在表示中。
為了比較,我們在潛在數據上套用了兩種聚類方法:高斯混合模型(GMM)和深度嵌入聚類(DEC)。我們辨識出了八類主導地震訊號,並將其與環境數據(如溫度、風速、潮汐和海冰濃度)進行了比較。在2016年厄爾尼諾夏季,RIS前緣的地震活動水平最高,整個部署期間,前緣附近的接地區域也出現了較高的地震活動。我們展示了某些類別的地震活動與RIS前緣的季節變化以及與羅斯島潮汐驅動地震活動的時空關聯。
關鍵詞: 深度聚類;地震數據;羅斯冰架;機器學習;無監督學習
1. 引言
西南極洲的冰蓋和冰架正在經歷快速變化。在2003年至2019年間,西南極冰蓋(WAIS)每年凈冰量損失1690億噸,導致海平面上升7.5毫米。溫暖的海洋正在增強冰架底部的融化,這減少了接地冰蓋的支撐,導致冰流入海洋的增加和海平面上升。隨著西南極洲單獨含有5.6米的海平面上升潛力,監測冰架的損失在預測未來海平面上升及其對海岸線和環境的社會影響方面起著關鍵作用。
增加的地震活動,如由斷裂產生的冰震,可以提供冰山崩解速率和冰架完整性變化的指示。然而,廣泛的連續記錄地震觀測系統的普及導致了數據量的激增,這使得使用傳統訊號處理方法分析變得越來越困難。與此同時,計算能力和機器學習演算法的進步使得研究自然過程和現象的更高效、數據驅動的方法成為可能。為了更高效地分析大型地震數據集,我們將當代ML技術套用於現有的訊號處理和數據分析技術。
地震學是一個數據密集型的領域,擁有完善的訊號處理和分析方法。ML技術的最近引入導致了開發出補充工具,為地震學家提供了傳統分析的新方法,如地震檢測和預警、相位拾取、地面運動預測、層析成像和大地測量。在這項研究中,我們展示了聚類,一種無監督ML的形式,用於在數據集中發現相似訊號的類別(Bishop, 2006; Holtzman et al., 2018; Johnson et al., 2020),它通常用作大型、未標記數據集的探索工具。
為了測試聚類相似訊號組以監測冰架的適用性,我們特別關註南極的羅斯冰架(RIS),在那裏從2014年11月到2017年1月部署了一個34站的被動地震陣列,以觀察RIS對海洋重力波沖擊的反應並研究冰架的結構動力學(Bromirski et al., 2015)。
該陣列連續記錄了長周期和短周期地震訊號,這些訊號表現出與冰架與海洋、大氣和地殼耦合相關的季節性和空間變化(Baker et al., 2019)。RIS上的訊號和環境雜訊包括Whillans冰流的潮汐驅動粘滑地震活動(Bindschadler, King, et al., 2003; Bindschadler, Vornberger, et al., 2003; Wiens et al., 2008);基底微地震和顫動(Barcheck et al., 2018);潮汐和熱驅動的裂隙(Olinger et al., 2019);
與地下融化相關的日間地震活動(MacAyeal et al., 2019);風產生的冰共振(Chaput et al., 2018);由海洋波動、次重力波和海嘯產生的彎曲和板塊波(Bromirski & Stephen, 2012; Bromirski et al., 2017; Chen et al., 2018);區域和遠端地震(Baker et al., 2020);以及由海洋重力波產生的冰震(Chen et al., 2019)。環境地震雜訊,可以用來估計RIS結構(Diez et al., 2016),也包含了海洋重力波的頻譜,其色散可以用來辨識它們的源距離和起源(Bromirski et al., 2015; Hell et al., 2019)。
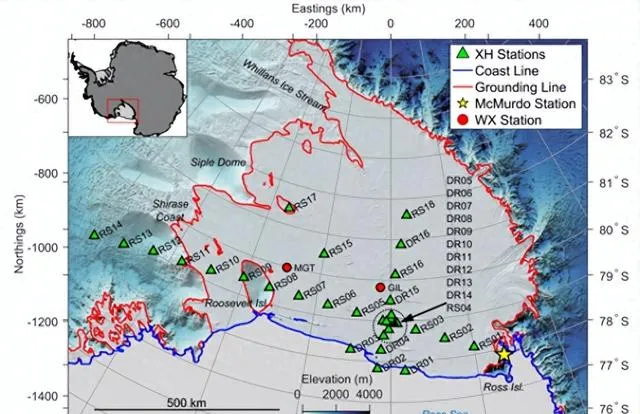
圖1. 無源寬頻地震陣列由34個地震站組成(羅斯冰架(RIS)對波浪誘導振動專案動態響應)。
RIS記錄的地震數據多樣,涵蓋了具有廣泛時空變異性的眾多源機制。在這項研究中,我們套用了兩種無監督聚類方法來辨識具有相似時間和光譜特征的地震事件類別。這些訊號類別的出現和分布提供了關於影響冰架演化的冰川過程的資訊。
2. 背景
具有相似特征的地震訊號分組(聚類)允許研究與環境強迫相關的冰川過程的空間和時間變異性。
2.1. 聚類
有許多方法可以對數據進行聚類(Aggarwal & Reddy, 2014),其中許多方法已被改編用於地震學和地球物理學(Kong et al., 2019)。基於稀疏建模的相關方法,稱為字典學習,已被套用於正則化地震反問題(Bianco & Gerstoft, 2018; Bianco et al., 2019)。層次聚類已被Mousavi et al. (2016)用於自動區分淺層和深層地震,Trugman和Shearer (2017)用於更精確地定位地震。圖形聚類已被Riahi和Gerstoft (2017)用於在密集地震陣列中定位源,Telesca和Chelidze (2018)用於在時間上聚類地震事件。
基於距離的聚類,如流行的k-means演算法(Hartigan & Wong, 1979; MacQueen, 1967),已被Chamarczuk et al. (2020)用於基於從地震數據提取的特征聚類地震活動。Perol et al. (2018)使用k-means來定義作為其摺積神經網絡(CNN)檢測和定位技術的一部份的概率地震位置。Wallet和Hardisty (2019)使用高斯混合模型(GMM)聚類,該模型假設數據中存在可以表示為線性疊加的高斯分布的聚類,從而辨識地震相。Seydoux et al. (2020)使用深度散射神經網絡和GMM來檢測和聚類地震訊號和背景雜訊。
並非所有的聚類方法都涉及ML。樣版匹配:其中從樣版波形構建匹配濾波器,用於掃描連續記錄以定位相似訊號(Beaucé et al., 2018; Chamberlain et al., 2018; Gibbons & Ringdal, 2006)。Yoon et al. (2015)和Bergen和Beroza (2018)提出了計算效率高的技術,其中局部敏感哈希用於將地震訊號對映到哈希表中,允許透過表項辨識相似訊號。Hotovec-Ellis和Jeffries (2016)開發了一種方法,使用基於相關性的相似性搜尋自動檢測和聚類連續數據中的重復火山地震。Cole (2020)采用了Hotovec-Ellis和Jeffries (2016)的方法,對RIS陣列數據在RS09、RS10和RS11站進行聚類,以表征這些站的潮汐強迫地震活動。
2.2. 維度
隨著維度的增加,聚類誤差指標可能會給出較少有意義的結果。由於高維數據聚類困難(Aggarwal et al., 2001; Steinbach et al., 2004),降維一直是開發的重點(Yang et al., 2017)。通常希望將輸入數據轉換為由較少、更顯著的特征描述的低維表示。一種流行的方法是使用主成分分析(PCA),它透過一系列非線性變換將高維數據投影到低維空間(Goodfellow et al., 2016),並被Reddy et al. (2012)用於壓縮地震數據以最大化特征變異數。
在這項研究中,我們采用自編碼器來降低數據的維度。自編碼器是一種模型,其輸出旨在透過一系列非線性變換(使用深度神經網絡(DNN))來復制其輸入(Hinton, 2006; Murphy, 2012; Yang et al., 2017)。這些非線性變換提供了更大的降維能力,並且能夠比PCA更好地建模具有低維表示的數據。自編碼器首先將輸入數據(例如,頻譜圖)編碼為潛在特征向量。接下來,自編碼器解碼潛在特征並重構原始影像。由於自編碼器提供了數據的非線性變換,因此必須使用梯度下降進行訓練。在這種叠代訓練中,輸入和輸出之間的誤差被最小化。透過這樣做,網絡權重學習了數據的顯著特征。透過在潛在特征空間中降低輸入數據的維度,可以在數據的潛在特征空間中套用聚類演算法。
2.3. 深度嵌入聚類
在深度聚類中,使用DNN(如自編碼器)來降低數據的維度。Xie et al. (2016)開發了一種新的深度聚類方法,稱為深度嵌入聚類(DEC),它由兩個過程組成:(a)訓練自編碼器來表示數據的顯著特征;(b)聯合最佳化編碼層和聚類層。Yang et al. (2017)透過聯合最佳化整個自編碼器(不僅僅是編碼器層)來擴充套件DEC方法。DEC的其他變體也被提出:Xie et al. (2016)在他們最初的實作中使用了堆疊去噪自編碼器(Vincent et al., 2010),但Min et al. (2018)采用了由CNN層和其他架構組成的自編碼器。最近,Chazan et al. (2019)開發了一種方法,其中聯合聚類是與表示每個聚類的混合自編碼器一起執行的,而Boubekki et al. (2021)展示了一種與自編碼器嵌入聯合最佳化的聚類演算法的效能提升。
Mousavi et al. (2019)使用DEC來預測地震檢測是局部的還是遠端的,SnoVer et al. (2021)展示了DEC聚類人為產生的地震雜訊的能力。在與我們類似的訊號處理和聚類工作流程中,Ozanich et al. (2021)比較了DEC和GMM在珊瑚礁上收集的聲學數據的頻譜圖上的效能,但在他們的情況下發現GMM的效能優於DEC。
在這項研究中,我們在RIS地震數據的潛在特征空間中實作了GMM聚類,並將其效能與DEC進行了比較。使用2014年12月至2016年11月的RIS地震數據,我們辨識了幾種不同類別的訊號,並進一步展示了深度聚類作為大型真實世界地震數據集探索工具的實用性,透過將聚類結果與觀察到的環境因素相關聯。
3. 羅斯冰架地震陣列和數據
RIS地震陣列的每個站點都由三個分量的Nanometrics Trillium 120 PHQ地震計組成,這些地震計被放置在冰面下1米處,在南半球夏季由太陽能板供電,在南半球冬季由鋰離子電池供電。陣列由兩個子陣列組成。較大的子陣列由18個站點組成,這些站點大約相距80公裏(字首RS),主要沿著RIS前緣平行排列。RS站點以100 Hz的取樣率采樣短周期正交分量地面速度,除了兩個站點以200 Hz采樣。較小的子陣列由16個站點組成(字首DR),沿國際日期線大致垂直於冰架前緣排列,以200 Hz的取樣率采樣地面速度。在這項研究中,我們主要關註檢測和分類冰震和局部/區域地震,使用頻率在3至20 Hz之間的垂直分量觀測。這個頻帶被選中是為了保留脈沖訊號,消除低頻處普遍存在的高能雜訊,並排除風在20 Hz以上頻率產生的共振。
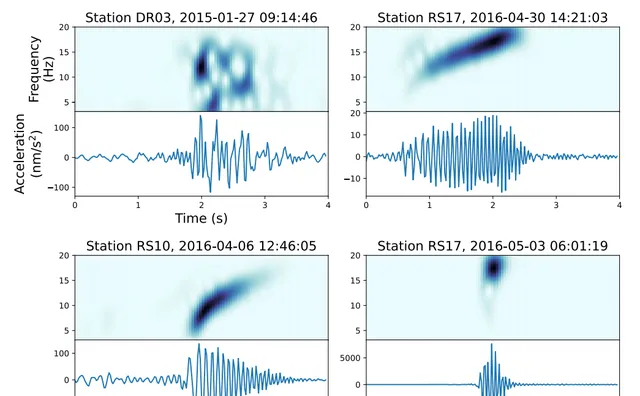
圖2. 顯示了檢測到的典型訊號類別
4. 深度聚類實作
深度聚類模型的目標是首先將輸入數據(在這種情況下是地震訊號的頻譜圖)編碼到一個包含潛在(低維)特征的層中,稱為嵌入層,然後在該潛在特征空間中套用聚類演算法。在接下來的實作中,輸入頻譜圖的8700個特征被一個摺積自編碼器減少到只有9個嵌入特征。然後我們描述了在聚類分析中使用的GMM和DEC聚類演算法。
4.1. 使用摺積自編碼器進行降維
自編碼器提供了一種透過一系列非線性變換使用低維表示進行數據近似的方法。自編碼器模型由三個部份組成:編碼器、瓶頸和解碼器(Murphy, 2012)。首先,編碼器將輸入數據從數據空間E_X對映到潛在特征空間E_Z,這個空間包含在模型的瓶頸部份。接下來,解碼器試圖從E_Z重構E_X。這個過程是叠代進行的,目標是最小化E_X和解碼器輸出E_X'之間的誤差。在最小化誤差的過程中,自編碼器學習了E_X的顯著特征,並準確地將它們編碼到E_Z中,從而降低了聚類任務的維度。
考慮一個由M個特征的光譜圖組成的數據集E_X,其中每個光譜圖E_x是數據集N個光譜圖中的第n個。在編碼階段,E_X到E_Z的對映由以下公式描述:
E_f(X) → Z = θ
其中θ是透過網絡訓練學習的參數。解碼階段是編碼器的映像操作,試圖將潛在特征空間E_Z對映回重構E_X':
E_g(Z) → X' = θ'
自編碼器的整體對映可以描述為:
E_F(X) → Z → X' = f(g(θ), θ')
其中F_g(θ) = θ ∘ θ'。輸入頻譜圖E_x對映到它們對應的潛在特征向量Z,以及它們的重構X',由以下公式描述:
D(Z) = f(θ) ∈ Z, X' = F(θ) ∈ X
由於自編碼器由摺積和轉置摺積層組成,E_Fθ是一個非線性對映,必須適當參數化。這是透過叠代學習參數θ來實作的,以便最小化輸入和重構數據之間的誤差。輸入頻譜圖E_x和其重構E_x'之間的均方誤差(MSE)定義為:
λ(X, X') = 1/M ∑_m (X_m - X_m')^2
MSE在數據集N的樣本上平均,以獲得自編碼器損失函數:
L_AE(θ, θ') = 1/N ∑_n λ(X_n, X_n')
在數據集上一次性執行此計算在計算上昂貴,記憶體密集,且可能導致收斂不良。相反,損失是在數據空間的迷你批次子集上計算的。對於每個迷你批次損失,使用隨機梯度下降(Goodfellow et al., 2016)來更新權重。當所有迷你批次都被處理後,下一個訓練周期開始,過程重復。在每個周期後,使用與訓練數據分開的子集來驗證模型的效能,而不更新權重,從而產生驗證MSE。訓練在達到指定的最大周期數或驗證MSE在10個周期內未能降至其最小值後提前停止。早期停止標準防止自編碼器過度擬合訓練數據。
自編碼器架構的設計選擇可以由數據集的先驗知識和其特征以及可用的計算資源等實際考慮因素來指導。我們的DNN架構在表1中詳細說明,旨在在計算上高效,易於構建,並且足夠強大以從嘈雜的地震數據集中學習顯著特征。在這個DNN架構下,θ包含218,250個可訓練參數。
4.2. 聚類方法
在我們的深度聚類框架中,聚類是在潛在特征空間E_Z中進行的,以在數據中找到K個不同的訊號類別。我們假設數據形成聚類,這些聚類在E_Z空間中是可分離的,並且這些聚類圍繞唯一的位置μ_k聚集,即其他相似訊號可能被發現的質心。我們使用歐幾裏得距離來衡量質心和潛在特征向量之間的相似性:
d_k,n = ||z_n - μ_k||^2
其中d_k,n是特征索引為n和k的向量之間的相似性度量。
4.2.1. 高斯混合模型(續)
線性疊加的高斯分布的混合物,每個高斯模型都有自己的質心μ_k和共變異數Σ_k。我們遵循Bishop (2006, p. 430)和Murphy (2012, p. 339)的方法。混合模型的整體分布在潛在空間E_Z中由它們的分布的凸組合給出:
p(z) = ∑_k π_k N(z | μ_k, Σ_k)
其中,N(z | μ_k, Σ_k)表示以μ_k為均值,Σ_k為共變異數矩陣的高斯分布。為了估計每個高斯分布的參數,我們使用期望最大化(EM)演算法來最大化關於參數μ_k, Σ_k和π_k的高斯混合模型的似然函數。
對於每個樣本z_n,引入一個二元隨機變量ξ_k ∈ {0,1}^K,其中只有一個元素等於1,其余為0。ξ_k的邊緣分布為:
p(ξ_k) = ∏_(j ≠ k) π_j
混合系數π_k滿足0 ≤ π_k ≤ 1且∑_k π_k = 1,以確保為有效概率。由於ξ_k是一個1-of-K(分類)表示,這個分布可以寫成:
p(ξ | z) = ∏_k π_k δ(ξ_k, argmax_k p(z | ξ_k))
其中,δ是狄拉克δ函數。然後,我們重寫方程式4,用因子聯合分布表示:
p(ξ, z) = p(ξ | z) p(z)
對於每個樣本z_n,我們有:
p(ξ | z) = p(ξ, z) / p(z)
其中,p(z)是邊緣概率,可以表示為:
p(z) = ∑_k p(ξ_k) p(z | ξ_k)
使用貝葉斯定理和方程式4和8,我們得到給定z_n的ξ_k的條件概率:
p(ξ_k | z_n) = p(ξ_k, z_n) / p(z_n)
這可以進一步重寫為:
p(ξ_k | z_n) = p(z_n | ξ_k) p(ξ_k) / p(z_n)
其中,p(ξ_k)是先驗概率,p(z_n | ξ_k)是後驗概率,給定觀察到z_n。
方程式4現在被重寫為:
p(z_n | ξ_k) = p(z_n | μ_k, Σ_k) p(ξ_k) / p(z_n)
使用貝葉斯定理和方程式4和8,我們得到給定z_n的ξ_k的條件概率:
p(ξ_k | z_n) = p(ξ_k, z_n) / p(z_n)
這可以進一步重寫為:
p(ξ_k | z_n) = p(z_n | ξ_k) p(ξ_k) / p(z_n)
其中,p(ξ_k)是先驗概率,p(z_n | ξ_k)是後驗概率,給定觀察到z_n。
對於每個潛在特征向量z_n,我們將其分配給一個高斯分布,透過argmax[γ_k(ξ_k)]來確定:
γ_k(ξ_k) = p(ξ_k | z_n) / p(ξ_k)
在實踐中,每個潛在特征向量z_n被分配給一個高斯分布,透過argmax[γ_k(ξ_k)]來確定。
使用上標t表示叠代索引,GMM的EM演算法如下:
1. 初始化參數μ_k^(1), Σ_k^(1), 和π_k^(1)。
2. 期望步驟。這一步透過評估責任(γ_k(ξ_k))來編碼樣本分配到每個高斯分布的概率,使用μ_k^(t-1), Σ_k^(t-1), 和π_k^(t-1)(方程式9)。
3. 最大化步驟。使用責任(γ_k(ξ_k)),這一步更新潛在空間E_Z中每個分布的質心位置(μ_k^(t)),形狀(Σ_k^(t)),和歸一化(π_k^(t)):
μ_k^(t) = ∑_n γ_k(ξ_n) z_n / ∑_n γ_k(ξ_n)
Σ_k^(t) = ∑_n γ_k(ξ_n) (z_n - μ_k^(t))^T (z_n - μ_k^(t)) / ∑_n γ_k(ξ_n)
π_k^(t) = ∑_n γ_k(ξ_n) / N
4. 收斂檢查。使用方程式5評估E_Z的對數似然,並檢查參數μ_k^(t), Σ_k^(t), 和π_k^(t)是否收斂。如果對數似然或參數發生收斂,EM演算法達到局部最大值並終止;否則,演算法返回步驟2。
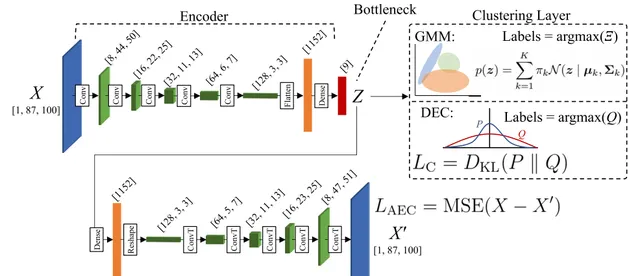
圖3.深度聚類框架使用摺積自動編碼器和解碼
為了加速EM收斂,使用k-means聚類來初始化GMM聚類演算法(Bishop, 2006, p. 438)。EM在1000次叠代後停止,或者當方程式5的對數似然變化小於0.001時停止。為了避免收斂到局部最大值,初始化執行100次,並保留具有最佳對數似然的初始化。
4.2.2. 深度嵌入聚類
在DEC中,聚類與自編碼器的繼續訓練相結合,聚類層連線到瓶頸,提供額外的損失函數,該函數透過自編碼器層進行反向傳播。
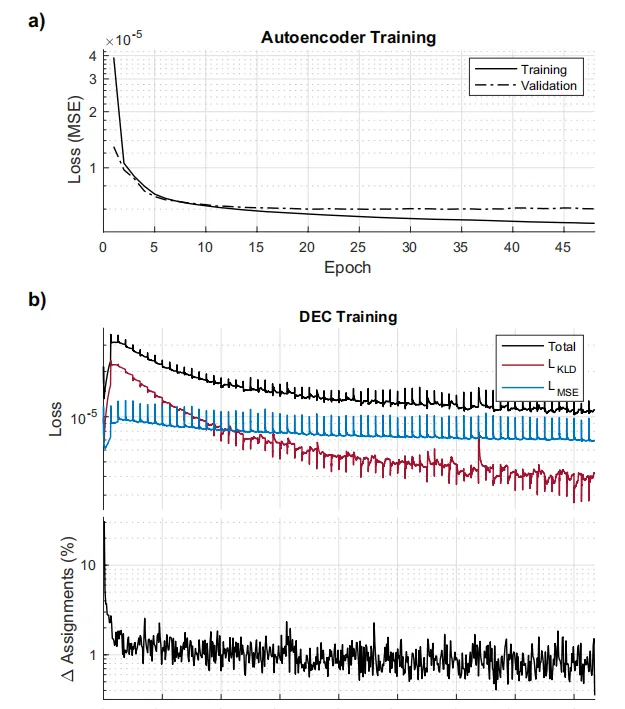
圖4.(a) 自動編碼器培訓期間的培訓和驗證損失(b)深度嵌入聚類(DEC)的損失曲線
DEC模型DNN參數使用訓練好的自編碼器的參數進行初始化,聚類層參數使用GMM聚類的質心進行初始化。DEC旨在透過使用嵌入頻譜圖和聚類質心之間的歐幾裏得距離(方程式3)作為額外的損失函數來改進GMM聚類。由於輸入數據是未標記的,需要一種自監督方法。我們實作了Xie et al. (2016)開發的方法,他們從t-分布隨機鄰域嵌入(t-SNE)演算法(van der Maaten & Hinton, 2008)中汲取靈感,提出測量潛在特征向量z和輔助目標分布之間的差異。簡化的學生t分布用於測量嵌入頻譜圖z_n和聚類質心μ_k之間的相似性:
q_k(z_n) = (1 + ||z_n - μ_k||^2)^(-1)
這導致了一組軟類別分配,即嵌入頻譜圖z_n被分配到類別k的概率。潛在特征向量z_n被分配到一個類別k,透過arg max[q_k(z_n)]確定。然後,使用軟類別分配來計算輔助目標分布p_k,其形式旨在提高聚類效能,強調具有高置信度分配的嵌入,並使每個聚類質心對損失函數的貢獻標準化,以便大聚類最小程度地扭曲E_Z:
p_k(z_n) = (q_k(z_n))^2 / ∑_k' (q_k'(z_n))^2
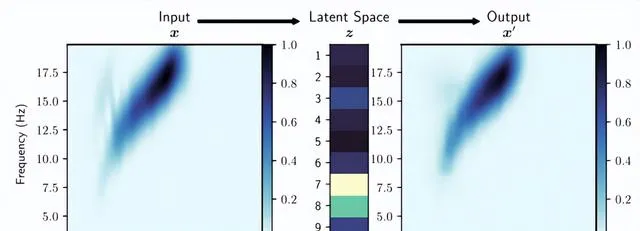
圖5.經過訓練的自動編碼器獲取輸入譜圖EX並將其編碼為九維潛在特征向量EZ
使用以上方程式,我們得到聚類層的損失函數:
L_C = ∑_k ∑_n C_k(z_n) log(p_k(z_n) / Q_k(z_n))
其中,C_k(z_n)是Kullback-Leibler散度,用於測量分布p_k(z_n)和Q_k(z_n)之間的差異。在DEC中,將方程式2和13的損失函陣列合成總損失函數:
L_total = L_AE + λ L_C
其中,λ是一個超參數,用於平衡兩個損失的貢獻,因為它們的量級不同。λ必須進行調整:如果λ太大,聚類損失會導致模型不穩定並導致潛在空間的扭曲,此時潛在空間將不再代表數據的顯著特征。如果λ太小,對聚類效能的影響將很小。我們發現λ = 10^(-4)對於模型訓練和聚類效能是最優的。
在DEC模型訓練期間,同時發生兩個組成過程。首先,透過DEC模型參數(包括自編碼器和聚類質心)反向傳播整個損失函數。其次,為了考慮訓練過程中聚類質心的變化,更新分布q_k(z_n)和p_k(z_n)。更新間隔是一個超參數,必須進行調整。透過超參數調整,發現每10個訓練周期更新一次是聚類效能最優的,最小化DEC損失,並在合理的時間內完成訓練。訓練在每個更新間隔後樣本更改分配的次數少於總訓練樣本數的0.4%時停止。
與自編碼器和DEC模型訓練相同的迷你批次大小和初始學習率(表2)。圖4b顯示了DEC訓練過程中損失隨時間的下降以及每個迷你批次訓練叠代中類別重新分配的百分比變化。盡管損失曲線的整體趨勢呈指數衰減,但在每個更新間隔時,當q_k(z_n)和p_k(z_n)被重新計算時,會出現周期性峰值,並且由於損失是在每個迷你批次而不是每個周期後記錄的,因此這些峰值是可見的。
4.3. 選擇最佳聚類數量
在無監督機器學習中,確定最佳聚類數量K是一個主要挑戰。在本研究中,我們將K視為一個超參數,透過叠代深度聚類工作流程,對一系列K值進行評估,以選擇最佳值。結果透過定量和定性評估進行評估。
定量評估是透過檢查每個類別的累積分布函數和概率密度函數作為到每個類別質心的距離的函數(方程式3)來執行的。此外,還參考了選擇最佳聚類數量的傳統統計方法,如間隙統計量(Tibshirani et al., 2001)和輪廓系數(Rousseeuw, 1987)。
定性方法是透過視覺檢查潛在特征向量z_n與各自類別質心μ_k的相似性,以及檢查分配給每個類別的頻譜圖和地震圖是否表現出相似性。一般來說,如果兩個或多個相似的類別形成,可能表明初始化了太多類別,這些類別中的數據可以在後處理中合並為一個類別。類別內頻譜圖之間的變異性過大可能表明需要一個或多個額外的類別。我們發現,對於RIS數據集,K = 8是最佳類別數量。
5. 結果
以下分析重點在於GMM和DEC效能如何影響潛在空間E_Z,以及這些方法是否在數據空間E_X中產生有意義的結果。由於數據集中的樣本未標記,沒有「真實」結果可以與結果進行比較,因此檢查了頻譜圖和潛在特征向量之間的類內相似性。我們得出結論,GMM和DEC在聚類效能上沒有明顯優勢。因此,我們建議在深度聚類RIS地震數據時實施GMM。GMM的統計和數學基礎被充分理解,而在沒有顯著效能提升的情況下,DEC的實作和解釋復雜性難以證明。此外,在實踐中,GMM聚類在圖形處理單元上對整個數據集進行聚類大約需要1分鐘,而一次DEC超參數調整執行可能需要幾個小時。
在接下來的分析中,我們呈現了包括訓練和驗證數據子集在內的531,407個頻譜圖的整個數據集的結果。我們透過使用不到10%的數據集進行訓練和驗證,並隨機無替換地抽取訓練樣本,以實作訓練子集代表整個數據集,來減輕DEC模型在訓練數據上過擬合的風險(Murphy, 2012, p. 23)。
5.1. 聚類效能
透過比較質心與其分配的潛在數據樣本來定性檢查深度聚類效能。GMM的結果如圖6所示。每個類別k由圖6中的列表示,每個質心μ_k及其重建(g(θ)μ_k)沿頂行繪制。雖然質心不是數據集的成員,但由於質心代表了其類別的顯著特征,其重建應類似於分配給其類別的頻譜圖。隨後的行顯示了分配給各自類別的數據樣本的潛在特征向量z_n、頻譜圖x_n和相關的地震圖。為了檢查隨著距離質心的增加(即隨著d_n,k的增加),類內相似性如何保持,顯示了{1,1000,5000,10000,15000,20000,25000}_n的樣本。
在質心附近,潛在特征向量z_n通常具有與其類別質心μ_k相似的值,表明GMM已成功將相似的潛在數據樣本分組到類別中,並且質心代表了其類別中的數據。每個類別中的頻譜圖也彼此相似,類似於質心重建(g(θ)μ_k),這證實了嵌入在質心中的潛在特征代表了類別中的頻譜圖。最後,潛在空間和時頻域中的相似性擴充套件到時域,其中每個類別中的地震圖彼此相似。隨著距離的增加(即隨著d_n,k的增加),開始出現不相似的情況,因為樣本與相鄰類別重疊。
除了檢查聚類的效力外,結果直觀地指示了是否選擇了合適數量的類別。例如,類別4和8在時間和頻率上表現出相似的特征,主要在峰值振幅上有所不同。如果這種區分沒有用處,或者相似性是多余的,類別可以在後處理中合並。如果選擇的類別太少,類別可能包含差異很大的訊號,表明需要增加類別數量。
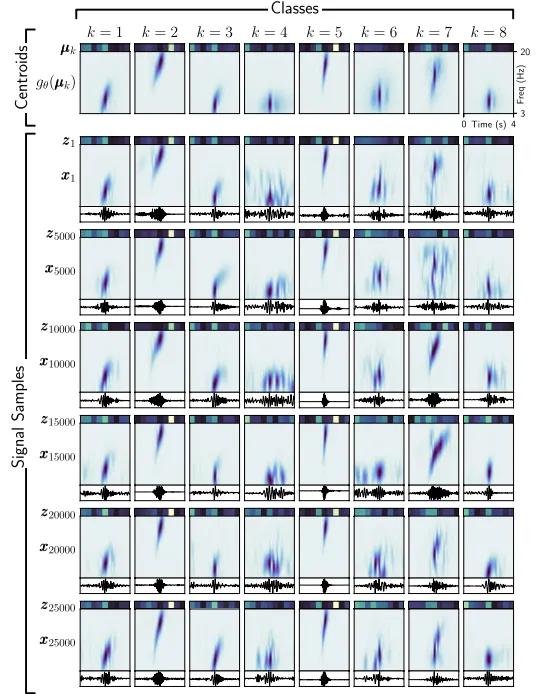
圖6.高斯混合模型(GMM)的聚類結果
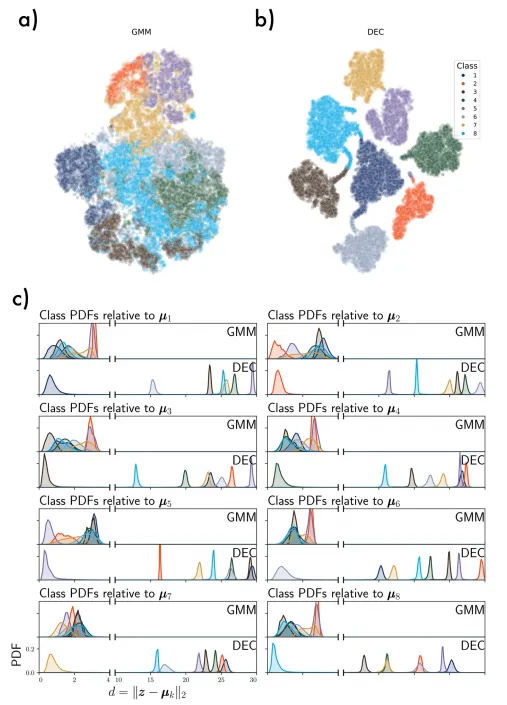
圖7. (a)t分布隨機潛在數據空間視覺化 高斯混合模型聚類。(b) 深度t-SNE圖 嵌入式聚類(c) DEC潛在特征作用
5.2. 深度聚類方法考慮
本研究中深度聚類實作的一個關鍵優勢是使用自編碼器來降低輸入數據的維度,以獲得更有效的聚類效能。透過降低數據空間的復雜性,聚類問題也相應降低,距離度量變得相關。自編碼器能夠快速學習數據的顯著特征並將其嵌入到潛在空間中,使該技術適用於新的數據集。雖然本研究中的自編碼器設計選擇足夠健壯,但自編碼器設計提供了進一步實驗和改進的機會。設計變量包括層的數量和類別、潛在特征空間的維度、啟用函數類別、最大池化和dropout層的結合以及過濾器的大小、深度和步長。
選擇聚類層的適當演算法在很大程度上取決於數據集的類別和內容。盡管在本研究中我們使用了GMM和DEC,如第2節所述,還有許多聚類演算法可能適用於深度聚類工作流程。無論選擇哪種聚類演算法,都必須仔細考慮聚類在潛在空間中的對映是否在數據空間中產生有意義的結果。
深度聚類的靈活性不僅體現在模型設計上,還體現在數據預處理和後處理上。模型設計主要關註如何學習數據的顯著特征,而數據預處理則關註提供給模型的資訊。這取決於訊號處理參數的選擇,特別是訊號持續時間、濾波器截止頻率和地震事件檢測演算法。此外,用於表征地震波形的各種數據變換通常可以用作深度聚類工作流程的輸入(Mousavi et al., 2016)。在我們的情況下,我們使用了頻譜圖,但其他變換,如連續小波變換尺度圖,也可以輕松用作輸入。在後處理中,可以合並冗余或相似的結果。
6. 討論:冰川學意義
從辨識的八類訊號的空間和時間分布中,我們獲得了關於RIS對各種氣候強迫(包括海洋和大氣變異性)響應的資訊。重要的是,兩年的連續地震監測允許辨識季節性和年際變化模式,特別是透過與2015年水平的比較,檢查2016年強厄爾尼諾對RIS地震活動的影響。
RIS陣列數據集包含531,407個地震檢測。數據集統計和類別特征的摘要(表4)顯示了每個類別的總檢測次數,以及在南半球夏季(1月、2月和3月)與冬季(6月、7月和8月)發生的檢測百分比。類別2、4、5、6和8在夏季與冬季的檢測次數差異明顯(超過10%),而類別1、3和7的差異較小(在5%和10%之間)。每個季節的年際比較顯示,類別5、6和7在2016年南半球夏季的活動增加,其中類別5和7的變化最大。
6.1. RIS前緣的季節性地震活動
在新冰山附近的RIS前緣約2公裏處,DR02站表現出與羅斯海海冰覆蓋和溫度變化相關的季節性地震活動模式。在南半球冬季,海冰覆蓋(圖11a)接近100%,抑制了海洋波動。在南半球夏季,海冰濃度降至約25%,允許海洋重力波直接沖擊冰架前緣並導致冰山崩解。此外,較暖的空氣溫度(圖11b)可能透過促進崩解來增加冰震活動(Chen et al., 2019)。
觀察到所有類別的地震活動增加,除了類別2和5。類別4、6和8在2016年南半球夏季特別活躍,當時強烈的厄爾尼諾條件導致整個西南極洲異常持續高溫(Nicolas et al., 2017),海洋-冰架相互作用增強。在DR01和DR03站也觀察到了類似DR02的地震活動模式,這些站也位於RIS前緣附近,如圖10a所示。在2016年1月10日至21日之間,RIS上觀察到了廣泛的表面融化(Chaput et al., 2018; Nicolas et al., 2017),這影響了雪層特性並透過凍融迴圈影響地震活動(MacAyeal et al., 2019)。
盡管類別6在夏季活動增加,但它在冬季月份也保持活動,這表明重力波活動不是主導強迫。類別1訊號的持續存在,通常由脈沖序列組成,表明它們可能是由冰架本身運動引起的冰震(Klein et al., 2020),因為DR02附近的冰流速度是RIS上觀測到的最高速度之一。類別5(圖11h)在一年中最冷的時期(4月至9月)更活躍,這表明這些訊號可能與極低溫度或強風事件有關。在冰架前緣約140公裏處的一個裂縫附近發生了冷天氣增強的地震活動(Olinger et al., 2019)。或者,從表4來看,這些類別的振幅低於在南半球夏季最活躍的類別,這表明這些檢測可能被其他類別的更高振幅訊號掩蓋。在所有類別中,不對應環境強迫 的高地震活動離散事件也會出現。這些事件可能表明發生了冰裂(冰震)或與裂縫擴充套件相關的事件。
6.2. 羅斯島的日間地震活動
位於羅斯島東側的RS09站在整個陣列中檢測到的事件最多,占整個數據集的22%。在圖12中,將潛在的環境地震源與每個類別的地震活動進行了比較。溫度和風速(圖12a和12b)是在RS09西南約122公裏的Margaret自動氣象站記錄的。潮汐(圖12c)是根據CATS2008模型(Padman et al., 2002)在RS10站實作的,該站位於浮冰上,近似於羅斯島和白瀨海岸之間的盆地中的潮汐訊號。RS09的類別1(圖12d)在全年都占主導地位,占檢測的52.8%。類別3、4、6和8(圖12f、12g、12i和12k)也在全年活躍。類別5和7(圖12h和12j)相對較少,地震活動似乎僅限於可能是與大裂縫或冰裂事件相關的離散訊號。盡管在2016年冬季類別5的地震活動增加,但在RS09沒有記錄到類別2(圖12e)的訊號。
RS09特別有趣的是與日潮汐相關的地震活動證據(圖12)。在年際時間尺度上,類別4和8表現出與春潮相關的周期性地震活動調制。在2016年3月15日至4月15日之間的兩周時間尺度上,類別1和3與日潮汐相關。甚至一些相對不活躍的類別(4、6和8)也顯示出日間地震活動的跡象。這些結果與之前的研究一致,該研究發現RS09超過95%的檢測來自全年發生的由潮汐引起的冰震群(Cole, 2020)。每周時間尺度還揭示了類別5和7冬季地震活動的突然開始和結束,這表明與冰架事件(如裂縫擴充套件或主要冰裂)有關。這種開始與2016年初在RIS陣列中可見的地震活動大幅增加一致(圖10)。
位於接地區域的其他站點也顯示出類似的地震活動模式,盡管程度較RS09輕。位於RS09東側的Shirase海岸的RS11站顯示出與RS09相似的地震活動模式。這些相似性表明,接地區域的冰架地震活動與相似的冰架過程有關。位於羅斯島西側的RS08站和位於Steershead冰上升的RS17站也顯示出日間地震活動,表明接地區域存在動態的日間過程。這些地震活動模式表明,冰架與固體地球在接地區域的相互作用受到潮汐的調節。在四個接地區域站點中,類別1、4和8是最常見的訊號,其中類別8訊號在這些站點中發生最頻繁。類別8訊號的平均峰值頻率為6.3 Hz,平均振幅為210 nm/s²,是整個陣列中檢測到的最強訊號之一。
7. 結論
使用GMM對RIS地震陣列數據集進行深度聚類,辨識出八類脈沖訊號,其中至少兩類與接地區域附近的潮汐變異有關。與2015年相比,2016年厄爾尼諾南半球夏季,RIS前緣附近的站點顯示出增加的冰震活動。在2016年南半球冬季過渡期間,整個陣列也觀察到了地震活動的突然增加。最高地震活動發生在接地區域,特別是在羅斯島東側。深度聚類是探索大型地震數據集的有效方法,特別是在辨識主導地震類別方面。當與非地震環境數據相結合時,深度聚類的結果可以幫助辨識或關聯地震源機制,如與RIS環境數據所示。此外,深度聚類可以輕松客製以調查相同或新數據集的不同方面。結合其在聚類地震檢測方面的有效性,這種靈活性表明深度聚類可以納入現有的地震工作流程,以加快探索性數據分析。
隨著地震數據集不斷增長,新的機器學習技術將對充分利用這些數據至關重要。深度聚類有潛力成為探索這些大型數據集的重要工具,並補充其他基於ML的工具以及傳統的訊號處理方法。將這些工具納入將使地球物理研究對快速變化的地球需求做出更全面和及時的響應。
數據可用性聲明
地震數據透過IRIS Web Services(https://service.iris.edu/irisws/)下載。地震數據使用ObsPy軟件(Beyreuther et al., 2010)進行處理。圖形在MATLAB(https://www.mathworks.com)和Matplotlib(https://matplotlib.org)中生成。DEC模型使用PyTorch(https://pytorch.org)生成。南極洲高程數據、接地線和海岸線來自Bedmachine(Morlighem et al., 2017),並使用Antarctic Mapping Tools for MATLAB(Greene et al., 2017)繪制。表面溫度數據來自AMRC, SSEC, University of Wisconsin–Madison(https://amrc.ssec.wisc.edu)。潮汐數據由CATS2008模型(Padman et al., 2002)生成。羅斯海冰覆蓋數據來自NASA NSIDC(Cavalieri et al., 1996,每年更新)。工作流程的程式碼可在https://github.com/NeptuneProjects/RISWorkflow獲取。
參照:
GB:Jenkins W F, Gerstoft P, Bianco M J, et al. Unsupervised deep clustering of seismic data: Monitoring the Ross Ice Shelf, Antarctica[J]. Journal of Geophysical Research: Solid Earth, 2021, 126(9): e2021JB021716.
APA:Jenkins, W. F., Gerstoft, P., Bianco, M. J., & Bromirski, P. D. (2021). Unsupervised deep clustering of seismic data: Monitoring the Ross Ice Shelf, Antarctica. Journal of Geophysical Research: Solid Earth , 126 (9), e2021JB021716.











