現在市面上的智能電子產品千千萬,為了達到人們使用更加方便的目的,很多智能產品都開發了語音辨識功能,用來語音喚醒進行互動;另外,各大公司也開發出來了各種智能語音機器人,比如小米公司的「小愛」,百度公司的「小度」,三星公司的「bixby」,蘋果的「siri」等等。這些語音辨識的功能,提高人們使用電子的產品的體驗,但是作為一名測試員,給你一款語音辨識產品,要怎麽進行測試呢?
接下來,我就以小米手機為例,給大家介紹小米手機語音辨識如何測試。
小米語音辨識功能如何進行測試?
要知道語音辨識功能如何測試,我們先了解智能產品語音互動流程:

所以,要進行測試的話,我們需要從以下幾個維度來準備測試點:
01.基礎功能測試:
1 聲紋的錄入:
語音喚醒,為了確保每個人的聲音、每個人在不同場景下的聲音都能成功語音喚醒,測試一定要有各種不同的聲紋來進行測試。
所以,就需要錄入各種不同的聲紋,來豐富測試場景的覆蓋;
2 語音喚醒:
正常喚醒:使用正常的聲紋進行語音喚醒,檢查可以成功;
異常喚醒:使用異常的聲音,比如影片/錄音進行喚醒,音樂聲進行喚醒,確保不會有誤喚醒。
3 喚醒後的功能:
a、語音找器材:可以喚醒器材,比如手機,透過語音找到器材。
b、音量調節:可以透過語音對器材進行音量調節
c、連續對話:喚醒器材後,可以與其進行持續的語音對話,功能正常。
d、指令辨識:喚醒後,可以下發指令比如播放音樂,查詢天氣,撥打電話、定鬧鐘等,檢查指令可以正常被執行。
4 功能沖突互動測試
a、中斷測試:語音辨識過程中,有中斷幹擾,比如手機喚醒的時候有電話中斷;有鬧鐘中斷、低電量中斷等,確保這些中斷能被正常處理,不會造成異常;
b、麥克風沖突:如果麥克風被占用了,測試是否能被喚醒;
5 多使用者場景
因為使用者使用語音辨識的場景非常多,測試很難進行完全的覆蓋。所以,我們需要透過分析使用者的主流使用場景,來覆蓋主要的場景。
透過一些數據的采集,發現使用者使用的場景螢幕分布如下:
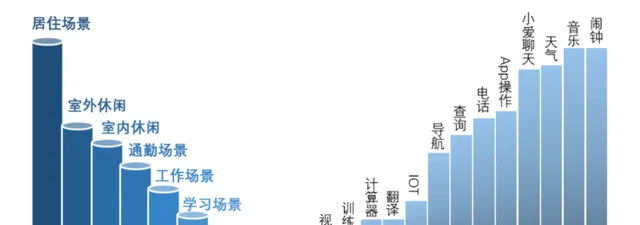
調查結果發現,使用者使用語音功能主要覆蓋以下場景:
所以測試就主要優先去覆蓋這些使用者場景,其他的場景用例優先級可以逐步降低,調整測試權重,保證使用者主流場景的穩定性和準確性。
02.UI 測試
語音喚醒的有 UI 界面需要進行 UI 測試。
比如手機的語音喚醒功能,需要進行 UI 界面的檢查,保持 UI 的友好型和美觀性;
03.相容性測試
1,第三方套用的相容性測試
如果器材裏有安裝其他的套用,比如手機裏的其他套用,是否可以透過語音辨識喚醒後進行指定的動作操作;第三方套用相容性需要保證;
2,外界器材相容
a、三段式耳機接入
b、四段式耳機接入
c、type-c 數碼耳機接入
d、藍芽耳機接入
透過接入這些第三方的耳機器材,可以進行語音辨識並且功能正常。
04.自動化語音辨識測試
以上都是透過手工進行測試的,要進行一個比較完整的語音辨識覆蓋,至少需要以下配置:
測試人數:
10/20 人(男女各一半)
測試次數:
每個場景 50 次
測試環境:
辦公室、會議室
測試場景:
亮屏喚醒、滅屏喚醒、手機播放音樂喚醒、聲紋誤喚醒、基本語句辨識率
但是手工測試是有不可忽視的一些嚴重缺陷的:
1、測試手法不統一:
不同的距離和不同的角度都會導致辨識結果不一樣。
2、測試過程中人員聲音波動大
同一演算法,同一產品,在測試人員不變,場景一致的情況下,多輪測試的數據差異大;
由此可見,手工測試耗時耗力、測試數據參考價值低。所以,語音辨識測試也可以進行一些自動化測試。
05.自動化測試的關鍵點
1 實作半自動化語音測試
因為手工測試就是沒有辦法提供那麽多人進行不同語料的測試,所以需要實作語料自動合成和模擬。可以采用 python+pyaudio 開發 + 音箱模擬人聲,來對語音進行辨識測試。
而且透過增加語料量級(至少 40 組聲紋),降低喚醒/辨識頻次;增加不同的噪音環境,不同噪音 + 不同距離,模擬使用者真實環境。
這樣,就可以覆蓋更多的不同的語料以及場景,大大提高辨識的正確率。
2 語料自動化播放 + 自動化檢測
現在有了語料,但是需要手動播放的話,工作量依然很大,所以需要實作語料自動播放和自動化監測。
3 增加雜訊播放系統 + 滑軌控制系統
因為使用者的使用場景往往有很多的噪音,如果測試不模擬這種噪音環境,是沒有辦法真正還原使用者場景的。所以,需要設定一些噪音源,可以自動化增加噪音,並可以調整距離。
如下圖,就是小米公司的專為為測試語言辨識造的混響室,以及自動化調節人頭系統












