文 | 光錐智能,作者|郝鑫
Kimi有多火爆?憑一己之力攪亂A股和大模型圈。
Kimi概念股連日引爆資本市場,多個概念股隨之漲停。在一片看好的態勢中,誰都想來沾個邊,據光錐智能不完全統計,目前,至少有包括讀客文化、掌閱科技、萬興科技等在內的十家上市公司釋出公告透露正在了解或接入了Kimi 智能助手。
眼看著Kimi的火越燒越旺,大廠也垂涎三尺,連夜加入了大模型「長文本」 的四國大戰。
對標月之暗面Kimi 智能助手的200萬字參數量,百度文心一言將在下個月開放200萬~500萬字長文本處理功能,較此前最高2.8萬字的文件處理能力提升上百倍;阿裏通義千問宣布升級,開放最高1000萬字的長文本處理能力;360智腦正在內測500萬字,功能正式升級後將入駐360AI瀏覽器。
四家中國大模型公司把長文本能力「卷」出了新高度。作為參考,目前,大模型最強王者OpenAI的GPT-4 Turbo-128k可處理文本能力約為10萬漢字,專攻長本文的Claude3-200K上下文處理能力約為16萬漢字。
但同樣都是「長」,有人是孫悟空,有人是六耳獼猴。
一位大模型行業的人士向光錐智能表示:「確實有一些公司用RAG(檢索增強)來混淆視聽。無失真的長文本和RAG,兩項技術各有優勢,也有結合點,但歸根到底還是不同的技術……很容易就用‘長本文’來混淆視聽。」
「百度、阿裏、360,大概率都使用了RAG方案」,該業內人士表示道。
無論是RAG還是長文本,一味地「長」並不能代表所有。如同上一輪,大模型廠商「卷」參數,大模型參數不是越大就越好, 文本長度,也不是越長,模型效果就越好。除了上下文長度,記憶能力、推理能力、算力都是共同的決定性因素。
進入2024國產大模型落地元年,大模型套用千千萬,為什麽是長文本能率先掀起波瀾?基於長文本的特性,又能解決哪些AI套用落地的實際問題呢?
長文本,真的越長越好嗎?
自ChatGPT誕生以來,國外一直在持續不斷地湧現出新的AI套用,產生流量的同時,也令人看到了商業化的可能性。
據風險投資公司a16z近期釋出的【GenAI 消費套用 Top100 報告】顯示,使用者月存取量最大的套用網站中,類ChatGPT的效率助手占據了榜單前十的大壁江山,ChatGPT的每月網絡存取量接近20億次,第二名Gemini的每月存取量約為4億次。
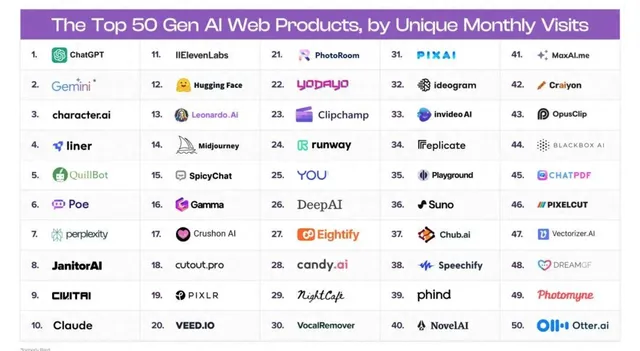
但同樣AI套用活躍而繁榮的場景卻並沒有在中國成功上演。在月之暗面的Kimi 智能助手憑借流量和人氣出圈之前,國內能夠達到一定體量的套用只有兩個, 一個是百度推出的文心一言App,另一個是字節跳動推出的豆包。
據相關數據統計,截至2023年9月,百度文心一言App的月活量達到最高峰值710萬;同年12月,字節豆包月活達到200萬,2024年1月在此基礎上翻了一番達到400萬。
文心一言憑借百度的大模型先發優勢和搜尋流量優勢,一度成為國內流量最大的AI套用;而豆包背靠抖音流量轉化池,雖然釋出時間稍晚一步,但在後期實作了反超。
在這樣背景之下,Kimi的爆火顯得尤為特殊, 某種意義上可以說,Kimi是國內第一個靠產品能力和使用者自來水破圈的AI套用。
月之暗面創始人楊植麟曾告訴光錐智能,其團隊發現正是由於大模型輸入長度受限,才造成了許多大模型套用落地的困境,這也是月之暗面聚焦長文本技術的原因所在。
站在使用者角度來看,好不好用是檢驗AI套用產品最關鍵的指標,而這都依賴於Kimi背後的長文本技術。
若將長文本的能力進一步拆解,大致可以包括長度、記憶、理解、推理幾個能力。
越來越長的文本長度,可以進一步提升現在AI套用的可用性和專業性。
對普通使用者而言,與AI助手簡短的閑聊能夠引起興趣,但不能解決問題,特別對於法律、醫學、金融等一些專業領域,需要前期「餵」給大模型特定的數據和知識,才能精準地輸出答案;對企業而言,更需要一個「專家型」的助手,大量的企業數據、行業數據都需要提前匯入,沒失真耗地輸入和輸出,從而保證最後的分析結果具有可參考性。Claude就是一個典型的例子,憑借長文本的優勢與ChatGPT走出不同的路線,收獲了大量的2B垂直行業的企業使用者。
多輪對話和記憶能力可以直接套用到現在大部份的場景中, 比如遊戲場景中的NPC,透過長文本輸入給予其角色設定,玩家每一次的對話都會被記錄,並且能夠生成個人化的遊戲檔案,避免了重新登入而需要反復喚醒的問題;在執行Agent(智能體)任務場景,能夠增強記憶能力,輔助Agent形成清晰的行動步驟,避免出現Agent打架的現象。
長文本的理解和推理能力體現在兩個方面, 一類是對想象類的套用理解生成,一類是對邏輯類套用的生成。 例如在對AI小說的套用中,長文本的能力體現在能夠理解使用者輸入的prompt,對其想象性的擴寫;在編程、醫療問答等領域,則需要呼叫其邏輯的推理能力,合理化地續寫編程,根據使用者描述推理病狀。
月之暗面副總裁許欣然曾表示,大模型無失真上下文長度的數量級提升,將進一步開啟對 AI 套用場景的想象力,包括完整程式碼庫的分析理解、自主完成多步驟復雜任務的智能體Agent、不會遺忘關鍵資訊的終身助理、真正統一架構的多模態模型等。
所以,長文本從來都是一項綜合性的能力,而非越長就越好。相反,過分追求長,可能引發算力匱乏的問題。
大模型公司卷「投流」,一天獲客成本20萬
流量狂飆、宕機後五次擴容;日活使用者數達百萬,月環比增長率107.6%;趕超微信、殺進App Store免費版套用第五名,月之暗面交出了一份漂亮的成績單。
但這也只是一個開始,多位業內人士在今年剛開年曾向光錐智能透露, 走過高速技術叠代的2023年,大模型來到了產業落地和商業化的下半場。
去年,各家已經相繼亮劍,智譜、百川、面壁不同程度上都開啟了商業化。月之暗面稍慢,目前還未公布商業化的方案,但急切地開始了商業化加速行程,B站、抖音等社交平台都能看到Kimi助手投流的廣告。

盡管,各家都從未將2C的變現路線排除在外,但是延續2016年AI 1.0時代的思路,多數還是將2B作為了首要的突破口。有了技術,去找技術和產業落地方向,探索落地方案似乎成為了理所應當。
月之暗面則是大模型公司的另類,去年10月份第一次公開露面後,就瞄準了2C的套用市場。楊植麟曾表示,長文本是月之暗面根技術,在這技術之上可以分裂出不同場景和領域的2C套用。
在Kimi效應爆發前,就有很多普通和企業使用者反饋,「Kimi是國內最好的AI助手,沒有之一」,從一開始就註重產品效果和使用者體驗的Kimi,現在爆發似乎帶有一定的必然性。
商業化壓力之下,大模型公司大概率會選擇2B、2C兩條腿走路。對比其他大模型公司,月之暗面則又提供了另一種商業化的路徑參考, 其他玩家從先2B再2C,以2B拉動2C,而月之暗面則屬於先2C後2B,再以2C的產品拉動2B的單子。
畢竟,除了國外的ChatGPT,之前在國內根本看不到2C產品增長的案例。Kimi靠近半年的積累,憑一己之力在2C撕開了一道口子,眾多大廠或許是看到了2C更多的可能性,才急於下場向市場證明自身具備長文本能力。
但回到商業化賺錢的本質,仍要思考如何將一時的流量轉化成實打實的付費率。
光錐智能觀察發現,現在大部份的大模型公司在推產品時還是互聯網推流的那一套,舊瓶裝新酒,抖音、B站、小紅書投流推廣,線上下的寫字樓電梯、機場、地鐵打廣告。
一通操作下來的實際轉化率有多少尚未可知,但為獲客花出去的都是真金白銀。據新浪科技報道,有投資人透露,目前Kimi使用者獲客成本達到12元~13元。 根據下載量預估,Kimi近一個月來日均下載量為17805。按此計算,Kimi每天的獲客成本至少20萬元。
現在市面上大部份的AI助手都是免費下載使用,基於網絡負外部效應,當使用者越來越多的時候,其資源的耗損就越來越大。此次的Kimi宕機事件就是最好的例證,順時暴漲的使用者量給算力和伺服器都造成了壓力,與之帶來的還有大量的token成本的消耗。
對大模型公司而言,規模化、付費率和成本的三方拉扯問題,短時間內無法得到解決, 即使是流量吊打其他套用的ChatGPT也面臨盈虧平衡的困境。
據data.ai數據顯示,截至2023年6月19日,ChatGPT iOS端上線首月的日活付費率約為4.36%。OpenAI預測,對於壓縮成本後的GPT-3.5模型和GPT-4模型,若月付費率每月提升0.25%或不能持續;若月付費率每月提升0.5%或能扭虧。
月付費率不斷提升聽起來很性感,但現實卻是「未老先衰」,爆發性的增長還未迎來,增長停滯先一步到來。
對大模型廠商,特別是創業公司來說試錯的機會並不多,不能剛從技術的坑出來,又一頭紮進投流的坑,跟風長文本不能解決所有問題,跑出商業化模式才是。











