定距數據 是沿著相鄰值之間距離相等的數值刻度測量的。這些距離稱為「間距」。
定距刻度上沒有真正的零點,這就是它與比率數據的區別。在定距尺度上,零是任意點,而不是變量的完全不存在。
區間量表的常見範例包括標準化考試(如 SAT)和心理量表。
3.5.1. 測量水平
間隔是四個分層測量級別之一。測量水平表明數據記錄的精確程度。級別越高,測量越復雜。
名義變量和有序變量是分類變量,而定距變量和比率變量是定量變量。與分類數據相比,可以對定量數據進行更多的統計檢驗。
3.5.2. 定距與比率刻度
定距和比率刻度在值之間具有相等的間隔。但是,只有比率刻度具有表示完全不存在變量的真零。
攝氏度和華氏度是 定距尺度 的例子。這些刻度上的每個點與相鄰點的間隔正好相差一度。20 度和 21 度之間的差異與 225 度和 226 度之間的差異相同。
然而,這些刻度具有任意的零點——零度並不是可能的最低溫度。
由於沒有真正的零,因此無法在區間刻度上乘以或除以分數。30°C 的溫度不是 15°C 的兩倍。 同樣,-5°F 的溫度也不低於 -10°F 的一半。
相比之下,克耳文溫標是一個 比率刻度 。在克耳文標度中,沒有什麽比 0 K 更冷的了。因此,以克耳文為單位的溫度比很有意義:20 K 的溫度是 10 K 的兩倍。
3.5.3. 定距數據範例
智力等心理概念通常透過測試或清單中的操作化來量化。這些測試的分數間隔相等,但它們沒有真正的零,因為它們無法衡量「零智力」或「零人格」。

要確定刻度是定距的還是有序的,請考慮它是否使用具有固定測量單位的值,其中任意兩點之間的距離是已知大小的。例如:
將數據視為定距數據可以執行更強大的統計檢驗。
3.5.4. 定距數據分析
要大致了解研究過程中所收集的數據,研究人員可以首先收集以下描述性統計資訊:
區間數據範例:
收集來自 A 市的 59 名應屆畢業生的 SAT 分數,考生的 SAT 分數可以在 400-1600 之間。
頻率分布:
表格和圖形可用於顯示並視覺化其分布。

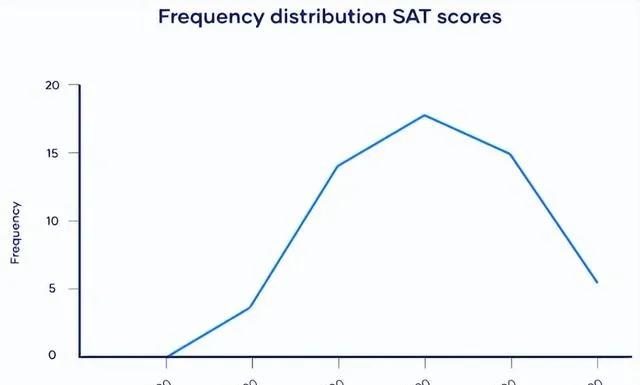
集中趨勢
從圖表中,可以看到數據是相當正態分布的。由於沒有偏度,要找到大多數值的位置,研究人員可以使用所有 3 種常見的集中趨勢度量:眾數、中位數和平均值。
(1) 眾數:眾數是數據集中最常重復的值。在這種情況下,沒有模式,因為每個值只出現一次。
(2) 中位數:中位數是正好位於數據集中間的值。要找到中間位置,請取 (n+1)/2 處的值,其中 n 是值的總數。
(n+1)/2 = (59+1)/2 = 30
中位數位於第 30 位,其值為 1120。
(3) 平均數:均值使用所有值為您提供一個數碼,以表示數據的集中趨勢。要找到平均值,請使用公式 ∑x/n。將所有值 (∑x) 相加,然後將總和除以 n。
∑x = 65850 n = 59 ∑x/n = 65850/59= 1116.1
當所收集到的定量數據呈正態分布時,平均值通常被認為是集中趨勢的最佳度量。這是因為它使用數據集中的每個值進行計算,這與眾數或中位數不同。
離散趨勢
全距、標準差和變異數描述了數據的分布程度。全距是最容易計算的,而標準差和變異數更復雜,但資訊量也更大。
(1)全距:要尋找全距,請從數據集中的最高值中減去最小值。我們的最大值是 1500,最小值是 620。
範圍 = 1500 – 620 = 880
(2)標準差:標準差是數據集中的平均變異量。平均而言,它告訴您每個分數與平均值相差多遠。大多數電腦程式都可以計算標準偏差。
s = 210.42
(3)變異數: 標準差是數據集中的平均變異量。平均而言,它告訴您每個分數與平均值相差多遠。大多數電腦程式都可以輕松為您計算標準偏差。
S2 = 210.42
統計檢驗
經過上面的數據簡要分析,研究人員已經對數據有了大致的了解,可以選擇適當的檢驗來進行統計推斷。在區間數據呈正態分布的情況下,參數檢驗和非參數檢驗都是可能的。
參數檢驗在統計上比非參數檢驗更強大,可讓研究人員對數據做出更有力的結論。但是,數據必須滿足若幹要求才能套用參數檢驗。
以下參數檢驗是一些最常見的參數檢驗,用於檢驗有關定距數據的假設。












