第五部分 核心子系统功能详述

1、故障短语抽取子系统
2.1 文本预处理
文本预处理是文本挖掘过程中必不可少的首要工作,预处理的结果直接影响到后续步骤处理的效果。因此,本系统通过文本预处理对语料库的数据进行清洗,以提高之后的故障特征提取的效果。文本预处理主要步骤包括分词、停用词过滤和词性过滤等。具体步骤如下:
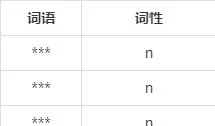
第一步,分词。本系统首先对语料库进行了中文分词,利用「jieba」分词工具,其主要使用了基于词典以及基于统计的分词算法:对于「jieba」自带词典中已用的词语可以最大概率的进行切分组合,分词效果好;对于未登陆的词语采用隐马尔可夫模型(HMM)进行识别切分,分词效果差。由于「jieba」自带词典中主要都是通用词汇,对于****领域的专业词汇并未记录,导致语料中如「***」、「***」、「***」等专业词汇不能有效识别,进而造成语料库的分词结果较差。因此,系统通过对「jieba」分词工具引入专业词典来确保分词结果的准确性。专业词典中主要记录了**故障相关的专业词汇,记录格式为「词语 词性」,如下表所示:
表3 部分专业词汇
第二步,停用词过滤。本系统过滤的停用词主要包括以下两部分:
1)特殊符号、标点符号以及单个字。
2)故障文本中特有的如***、***、***等干扰词。
第三步,词性过滤。通过上述分析可知故障关键词主要是名词、动词和动名词,因此,系统通过词性过滤将非以上词性的单词过滤掉,以提高关键词在分词结果中的出现概率,使得关键词提取算法的准确率有所提升。
经过以上三步的文本预处理后,由语料库中的故障文本得到候选关键词集合,之后将通过关键词提取算法提取出故障文本中的关键词。
2.2 基于改进TextRank的关键词提取
系统通过对**故障数据进行观察分析,提出了基于改进TextRank的关键词提取方法,以故障现象文本:「******」为例。将由共现关系得到的候选关键词词图中的边上权值改为改进后的转移概率。之后,基于第五部分的公示进行迭代计算,直到各词项的分值收敛,停止计算。按分值大小排序,取前5个词语作为关键词提取的结果:[('****',1.0),('故障',*****),('重启',****),('不成功',*****),('***',0.7798)]。
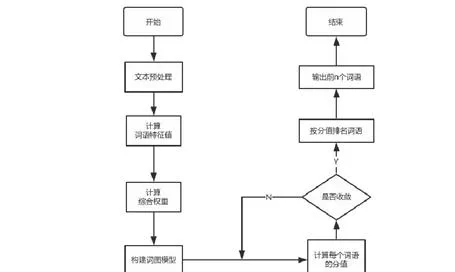
为验证改进TextRank关键词提取算法提取效果是否优异,探索不同词语特征对TextRank算法提取结果的影响,系统设计四组对照实验,都是以200篇故障现象文本为测试集,分别提取3个、5个和7个关键词。使用准确率P(precision)、召回率R(recall)、F值(F-score)进行效果评价。

其中,P和R的取值都在0到1之间,结果越接近于1,说明算法的查准率和查全率越高,效果越好;F值则是综合考虑了准确率和召回率。正确关键词由人工标注所得。
在TFIDF、LDA、TextRank和改进TextRank的结果比较的对照实验中,主要比较基于统计的TFIDF算法、基于主题模型的LDA算法、基于图的TextRank算法以及本文改进的TextRank算法的结果。其中LDA模型设置的主题个数为10个。
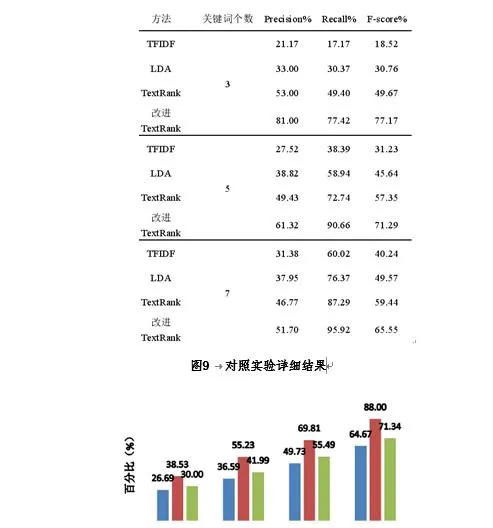
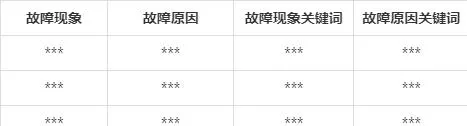
通过对照实验结果,可知系统提出的改进TextRank在提取故障文本关键词的效果上比传统算法有所提升。由此经过关键词提取算法得到的**故障文本关键词的部分结果如下表所示。提取的关键词是由分值从高到低排名的前5个。可以看到虽然绝大多数的故障关键词出现在分值排名前五中,但还是有如「***」、「***」、「***」和「***」等关键词分值排名在前五之后。所以单纯以关键词排名来抽取故障短语并不合适,而且分开的词语也不能很好的表示故障现象和故障原因,需要进行后续处理。
表4 部分数据的关键词提取结果
2.3 基于文本相似度的故障短语抽取











