AI漫长的历史中,ChatGPT绝对是浓墨重彩的一笔。正是它引爆了AI大模型概念,也让以往高高在上的AI飞入了寻常百姓家,开始融入每个人的日常工作、生活,AI PC、AI手机、AI边缘也都在大踏步前进,变革千行百业。
有调研数据显示,预计到2026年,AIGC相关投入将超过3000亿美元,到2028年,80%以上的PC都会转换成AI PC,而在边缘应用中AI的普及率也将超过50%。

AI大模型等应用最需要的当然是高算力,GPU加速器随之变得炙手可热,但是AI的发展与变革同样是多元化的,CPU通用处理器、NPU神经网络引擎也都在各司其职,贡献自己的力量。
尤其是传统的CPU,也在紧跟时代的脚步,全方位拥抱AI,Inte第五代至强(Emerald Rapids)就是一个典型代表。

Intel 2023年初发布的第四代至强(Sapphire Rapids),年底就升级为第五代,速度之快前所未有,主要就是为了跟上形势,尤其是AI的需求,很多指标都是为此而优化的。
这包括更多的核心数量、更高的频率、更丰富的AI加速器,都带来了性能和能效的提升,对于AIGC非常有利。
还有多达3倍的三级缓存,可以减少对系统内存的依赖,内存带宽也同时进一步提升。
软件生态方面,Intel提供了全方位的开发支持与优化,尤其加大了对主流大模型、AI框架的支持,特别是PyTorch、TensorFlow等等,在AI训练、实时推理、批量推理等方面,基于不同算法,性能提升最多可达40%,甚至可以处理340亿参数的大模型。

根据Intel提供的数据,五代至强SPECInt整数计算性能提升21%,AI负载性能提升最多达42%,综合能效也提升了多达36%。
具体到细分领域,图像分割、图像分类AI推理性能提升最多分别42%、24%,建模和模拟HPC性能提升最多42%,网络安全应用性能提升最多69%。
网络与云原生负载能效提升最多33%,基础设施与存储负载能效提升最多24%。
有趣的是,Intel指出五代至强也有很高的性价比,其中一个评估标准就是同时支持的用户数,五代至强可以在BF16、INT8精度下同时满足8个用户的实时访问需求,延迟不超过100ms。
五代至强的优秀,也得到了合作伙伴的验证,比如阿里云、百度云都验证了五代至强运行Llama 2 700亿参数大模型的推理,其中百度云在四节点服务器上的结果仅为87.5毫秒。
再比如京东云,Llama 2 130亿参数模型在五代至强上的性能比上代提升了多达50%。


接下来,Intel至强路线图推进的速度同样飞快,今年内会陆续交付Granite Rapids、Sierra Forest两套平台,均升级为全新的Intel 3制程工艺。
其中,Sierra Forest首次采用E核架构,单芯片最多144核心,双芯整合封装能做到288核心,今年上半年就能问世。
Sierra Forest主要面向新兴的云原生设计,可提供极致的每瓦性能,符合国家对设备淘汰换新的要求,而且因为内核比较精简,可以大大提高同等空间内的核心数量。
紧随其后的Granite Rapids,则依然是传统P核设计,具备更高频率、更高性能。
Granite Rapids针对主流和复杂的数据中心应用进行优化,尤其是大型程序,可以减少对虚拟机的依赖。
到了2025年,Intel还会带来再下一代的至强产品,代号Clearwater Forest,无论制程工艺还是技术特性抑或性能能效,都会再次飞跃。

那么问题就来了,Intel至强的更新换代如此频繁,尤其是五代至强似乎生命周期很短,它究竟值不值得采纳部署呢?适合哪些应用市场和场景呢?
五代至强发布之初,Intel从工作负载优化性能、高能效计算、CPU AI应用场景、运营效率、可扩展安全功能和质量解决方案五个方面进行了介绍。
现在,我们再换一个维度,从另外五个方面了解一下五代至强的深层次价值。
一是制程工艺改进。
五代、四代至强都是Intel 7工艺,都采用了Dual-poly-pitch SuperFin晶体管,但也改进了关键的技术指标,特别是在系统漏电流控制、动态电容方面,它们都对晶体管性能有很大影响。
通过这些调整,五代至强在同等功耗下的整体频率提升了3%,其中2.5%来自漏电流的减少,0.5%来自动态电容的下降。
二是芯片布局。
受到芯片集成复杂度、制造技术的限制,现在主流芯片都不再是单一大芯片,而是改为多个小芯片整合封装。
四代至强分成了对称的四个部分,做到最多60核心,五代至强则变成了镜像对称的两部分,核心数反而提升到最多64个。
之所以如此改变,是因为切割的小芯片越多,彼此互相通信所需要的控制器、接口和所占用的面积也更多,还会额外增加功耗,并降低良品率。
通过芯片质量控制,五代至强可以更好地控制芯片面积,并且在相对较大的面积下获得很好的良率,镜像对称的布线也更灵活。

这是五代至强单个芯片的布局图,可以看到中间是33个CPU核心和二三级缓存,其中一个核心作为冗余保留。
左右两侧是DDR5内存控制器,上方是PCIe、UIPI控制器,以及DLB、DSA、IAA、QAT等各种加速器,底部则是EMIB封装和通信模块,用于双芯片内部高效互连。
说到连接,五代至强使用了高速内部互连Fabric MDF,包括七个SCF(可扩展一致性带宽互连),每一个都有500Gbps的高带宽,让两颗芯片在逻辑上实现无缝连接。

三是性能与能效。
看一下五代至强的关键性能指标:
- CPU架构升级到Raptor Cove,13/14代酷睿同款。
- 核心数量增加,最多60核心来到最多64核心。
- 三级缓存扩容,平均每核心从1.875MB增加到5MB,这是历代提升最大的一次。
- DDR5内存频率从4800MHz提升到5600MHz。
- UPI总线速度从16GT/s提供到20GT/s。。
- 芯片拓扑结构更改,四芯片封装改为双芯片。
- 待机功耗降低,通过全集成供电模块(FIVR)、增强主动空闲模式等技术实现。

四是三级缓存。
至强处理器以前每核心的三级缓存都只有1-2MB,这次直接来到了5MB,总容量最多达320MB。
在数据集不是很大的情况下,三级缓存本身就可以基本承载,无需转移到系统内存,从而带来极大的性能提升。
但是,缓存容量并不是单纯堆起来的,因为大缓存会面临可靠性问题,尤其是在大规模数据中心里存在一个比特反转的软故障,缓存越大,故障几率越高,当错误足够多而无法纠正的时候就会导致系统宕机。
这就需要超强的纠错机制,五代至强就采用了新的编码方式DEC、TED,一个缓存行出现两个位错误的时候也可以纠正,三个位错误的时候也可以检测,比传统单位纠错、两位检错有着更强的容错性,此外还有一些新的数据修复方案。
五是内存IO。
DDR5-4800升级到DDR5-5600,看似幅度不大,但其实很不容易,因为内存速度提升后,从芯片到基板需要全线进行优化匹配,包括供电和噪音控制等。
为了保证高频下的信号完整性,五代至强还加入了4-tap DFE功能,尽可能减少码间干扰(ISI)。
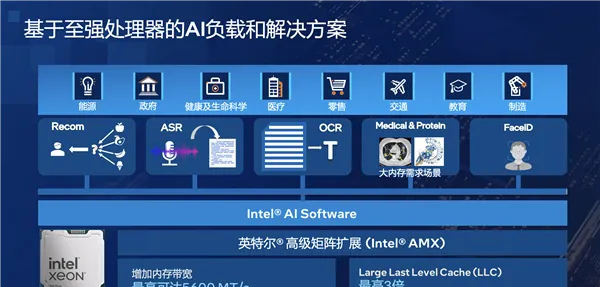
最后再单独说说基于至强这样的通用处理器的AI负载应用,以及相应的解决方案。
其实,AI应用并非只是大模型,还有大量的传统非大模型AI应用,都非常适合在CPU上部署。
比如基因测序这样的科学计算,2018年至今,至强每一代都有显著提升,因为科学计算很多时候就是「暴力」计算,最考验CPU的处理能力。
除了硬件上的支持,Intel还有强大的软件生态优化,包括基于OpenVINO对整个模型进行优化、量化,在推荐、语音识别、图像识别、基因测序等方面Intel都做了大量的优化。
比如模型非常大的推荐系统、稀疏矩阵等应用,CPU的效率其实优于GPU,因为单个GPU不够用的时候就得跨GPU,或者和CPU频繁交互传输,而在与内存互通方面CPU的效率是更高的。
其他像是网络、数据服务、存储等等,至强无论性能还是能效都在行业处于领先地位,更关键的是系统故障率非常低。

对于通用的AI工作负载,Intel采用了AMX、AVX-512两个指令集,并基于OpenVINO进行优化。
AMX适合处理BF16、INT8数据类型,比如推荐系统、自然语言处理、图像识别与目标检测等等。
AVX-512适合处理FP32、FP64数据类型,比如数据分析、机器学习等等。
在推理的过程中,指令集还可以进行灵活切分,通过加速器定向加速某一部分,替代基于GPU的AI模型是完全没有问题的。
事实上,AI只是工作负载的一部分,更多的是通用负载,很多深度学习模型也都是「混合精度」,四代、五代至强运行它们的时候都可以根据需要在AMX、AVX-512之间灵活无缝切换。
针对大模型的加速,Intel也推出了自己的框架BigDL LLM,有很多框架层针对CPU进行了大量的优化,并针对模型做了量化。
另外,Intel拥有开放的生态,行业伙伴和友商都可以直接纳用,这对Intel自身来说也是一件好事,可以带动整个生态的发展,让Intel的解决方案得到更广泛的普及。
总的来说,在这个AI时代,CPU、GPU、NPU等各种计算引擎都有自己的独特优势,都有自己的适用场景和领域,不存在谁取代谁,更多的是灵活的选择与协同的高效,需要结合具体业务的能效、成本等多方面综合考虑。
CPU作为最传统的通用计算引擎,始终都会占据不可替代的地位,无论是作为整个计算平台的中心枢纽,还是对各种通用负载、AI负载的灵活处理,未来依然可以横刀立马!












