(报告的出品方是:中国平安)
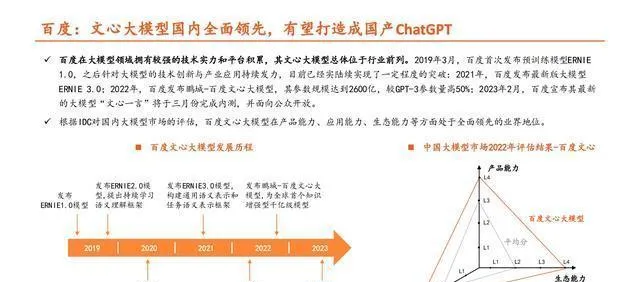
百度的文心大模型在国内是全面领先的,很有希望被打造成国产的ChatGPT。
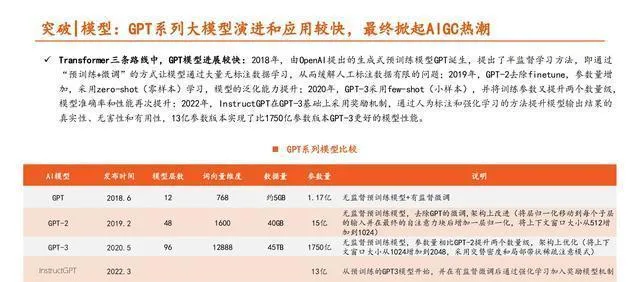
百度在大模型这块儿有很强的技术和平台积累,文心大模型在行业里大体上是排在前面的。2019年3月的时候,百度第一次推出预训练模型ERNIE 1.0,打这以后,在大模型的技术创新和产业应用上就一直下功夫,到现在也陆陆续续有了一定的突破。2021年,百度推出了ERNIE 3.0这个最新版的大模型;2022年,百度又发布了鹏城 - 百度文心大模型,这个模型的参数规模达到2600亿,比GPT - 3的参数量多出50%;2023年2月,百度说它最新的大模型「文心一言」会在3月完成内测,然后对公众开放。按照IDC对国内大模型市场的评估,百度文心大模型在产品能力、应用能力、生态能力这些方面,在业界是全面领先的。
百度创新性地引入大量知识,文心大模型的性能得到了很大提升。
百度的「文心一言」,其生态建设有了进展,有进行商用拓展的潜力。
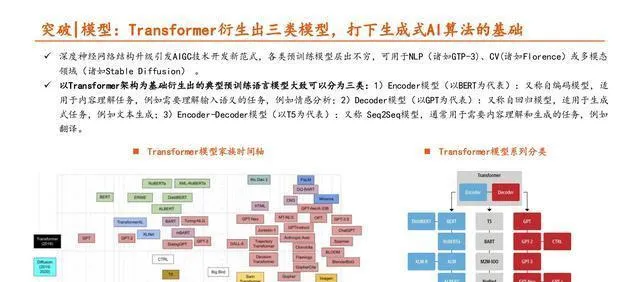
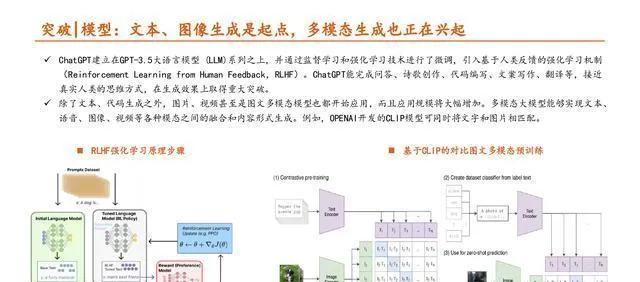
大模型(也叫基础模型)能够利用海量、各种各样的数据(一般是无标注的文本)预先训练,然后针对很多下游任务进行微调或者适配。对于不同的任务和应用场景,只要把大模型迁移学习到下游任务就能达成目的,这样就解决了传统自然语言处理(NLP)技术得从头开始训练下游任务的麻烦事儿。
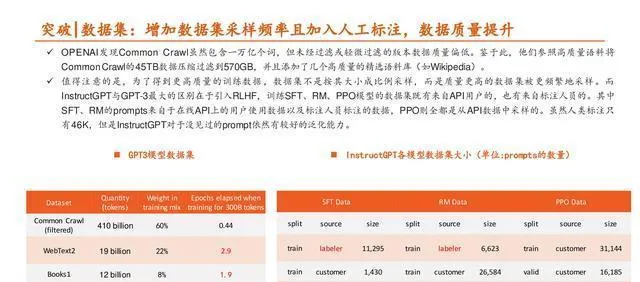
突破 | 数据集:数据量、多样性、数据质量很关键。
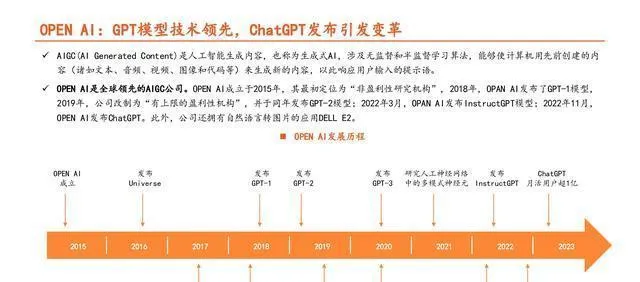
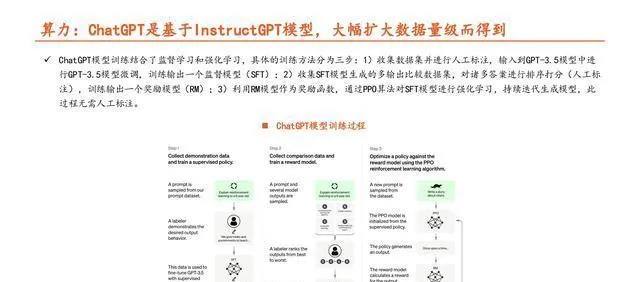
算力方面:ChatGPT是在InstructGPT模型的基础上,通过大幅增加数据量级而得来的。
ChatGPT模型的训练把监督学习和强化学习结合起来了,具体的训练方式分三步:1)先收集数据集,然后人工标注,再把标注好的数据集输入到GPT - 3.5模型里对这个模型进行微调,这样就能训练得到一个监督模型(SFT);2)收集SFT模型生成的有多个输出的比较数据集,对很多答案进行排序打分(这一步也是人工标注),通过这个就能训练得到一个奖励模型(RM);3)拿RM模型当奖励函数,用PPO算法对SFT模型做强化学习,不断迭代生成模型,这个过程不需要人工标注。
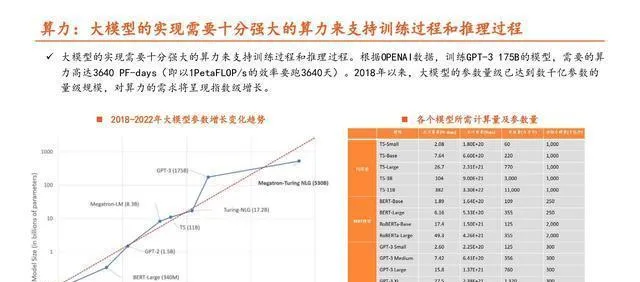
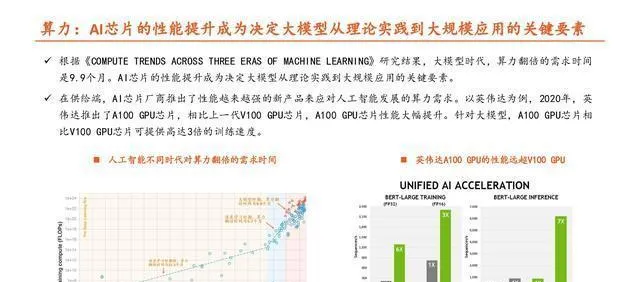
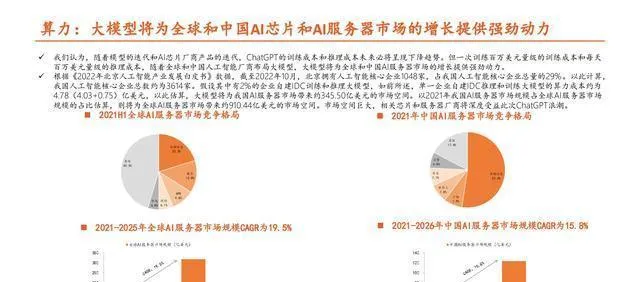
大模型要想实现,在训练和推理过程中得有非常强大的算力来支撑。
ChatGPT不管是进行训练还是推理,在算力上花费的成本都很高。
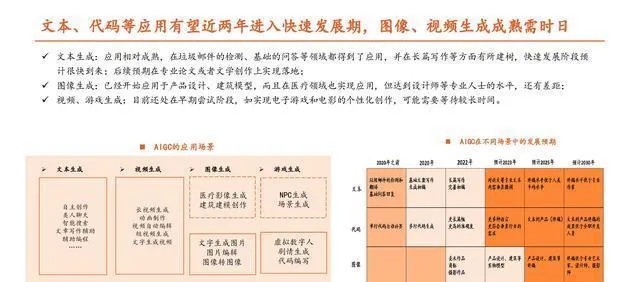
【应用:行业将逐步回归理性,能否突破需要看B端】
【报告节选:】

















(这篇文章只是用来参考的,不代表我们的任何投资建议哦。要是想要使用相关信息的话,就去看报告原文吧。)
精选报告来源:【未来智库】。「链接」











