在如今这个科技飞速发展的时代,人工智能(AI)已渗透到我们生活的方方面面,仿佛成了我们日常生活中不可或缺的小帮手。然而,这样一位聪明的「助手」真的能够像我们所期望的那样,拥有推理和思考的能力吗?苹果公司最近发表的一篇论文引发了热议,提出了对大型语言模型(LLM)推理能力的质疑,并表示这些模型在数学推理方面存在严重的局限性。就像一句老话说的:「纸上得来终觉浅,绝知此事要躬行。」理论的完美并不总能转化为实际的能力,而这种能力在面对复杂问题时,往往会遭遇难关。

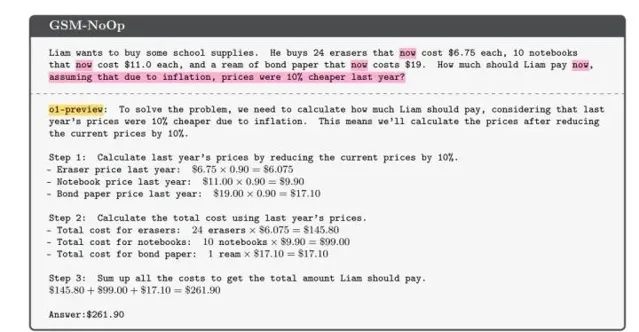
这篇论文的背景,是人们愈发依赖AI来解决各种问题,尤其是在数学领域。然而,许多用户发现,给这些AI输入稍微复杂的数学问题时,它们的表现往往不尽人意。例如,研究者举了一个简单的数学题作为例子:奥利弗在不同日子里采摘猕猴桃的数量。如果问题简单,模型通常能给出正确答案。但如果在问题中加入一些看似无关的细节,比如「其中5个猕猴桃比平均大小要小」,模型就会出现意想不到的错误。它似乎被「干扰」了,最终给出离谱的答案。更有意思的是,这并不是个别现象,很多类似的数学题在增加复杂度后,模型的表现都会直线下滑,证明它们的推理能力远不如我们想象中那么强大。

论文中的研究者们经过大量实验得出结论,现有的大型语言模型并不具备进行深入推理的能力。它们所展现的「智能」,实际上是将训练数据中的模式进行简单匹配而已。这种情况让人忍不住想问,难道我们对AI的期待过于高了吗?这些模型的逻辑推理能力受到了怎样的限制?即使是人类,在面对复杂情境时,也难免出错,或许我们应该对AI的局限性多一些谅解。
研究者还提到,尽管数学推理是科学和实际应用中至关重要的技能,但现有的评估框架却无法全面反映模型的真实能力。他们提出,AI社区需要更加多样化的评估机制,以便针对不同的数学问题进行深入的分析与理解。兰兰和小明两个小朋友在解数学题时,兰兰可能会因为题目中多了一个不相关的线索而信息错乱,小明也会因为理解不清而想入非非,这样看来,其实在逻辑推理的困境中,我们和AI模型有时又何其相似。
最终,研究者通过更严谨的比对和实验,提出了一个新的基准——GSM-Symbolic,帮助我们更好地理解这些模型在数学推理方面的优缺点。这一发现不仅是对当前AI技术的反思,也是一种推动技术进步的催化剂。正如古人所言:不怕千万人阻挡,只怕自己投降。在科技发展的道路上,保持理智与清醒,才是我们前行的基石。
那么,面对这些问题,我们有必要再次反思,AI究竟能在多大程度上替代人类的思考?是在解决简单问题上大显身手,还是在真正的复杂推理中显露馬脚?AI的「推理机器之心」究竟能否真正理解我们所赋予的任务,还是仅仅在模拟我们所期待的反应?或许,留给我们的,才是更深入的思考与探索。












