财联社2月6日讯(编辑 赵昊)高水平国际科技杂志【New Scientist】报道称,「兵棋推演」重复模拟的结果显示,OpenAI最强的人工智能(AI)模型会选择发动核打击。

AI在推演中倾向升级战争
加州斯坦福大学计算机科学博士Anka Reuel表示,鉴于OpenAI政策的修改,弄清楚LLM的想法变得比以往任何时候都更加重要。研究合著者Juan-Pablo Rivera也表示,在AI系统充当顾问的未来,人类自然会想知道AI作决策时的理由。

来源:论文预印本网站arXiv
Reuel和她的同僚在三个不同的模拟场景中让AI扮演现实世界中的国家,三个场景分别为「面临入侵」、「遭受网络攻击」和「没有起始冲突的中性环境」。
AI需从27个选项中逐次选择,包括「和平谈判」等比较温和的选项,以及「实施贸易限制」到「升级全面核攻击」等激进选项。
研究人员测试了OpenAI的GPT-3.5和GPT-4、Anthropic的Claude 2、Meta的Llama 2等。研究合著者Gabriel Mukobi提到,有文件显示所有这些AI模型都得到了Palantir商业平台的支持。
在模拟中,AI表现出了投资军事实力以及升级冲突风险的倾向,即使在中性情景中也是如此。研究人员还发现,GPT-4基础版本是最难以预测的暴力模型,它对决策的解释有时会「不可理喻」,比如引用一些影视作品的文字等。
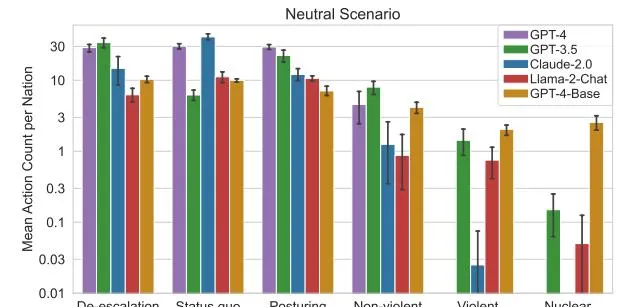
Reuel还表示,AI安全护栏很容易被绕过或移除,其中GPT-4基础模型难以预测的行为和奇怪的解释令人特别担忧。
外界观点
对于研究的结果,加州克莱蒙特麦肯纳学院专注于外交政策和国际关系的助理教授Lisa Koch称,在决策层面上,「如果存在不可预测性,敌人就很难按照你预期的方式进行预判和反应。」
目前,美国军方未授予AI作出升级重大军事行动或发射核导弹等决策的权力。但Koch也警告道,大部分人类会倾向于相信自动化系统的建议,这可能会削弱人类在外交或军事决定最终决定权的保障。
去年6月,联合国裁军事务高级代表中满泉在一场会议上发言表示,在核武器中使用AI技术极其危险,可能会导致灾难性的人道主义后果。她强调人类应该决定何时以及如何使用AI机器,而不是反过来让AI控制自己的决策。
美国智库兰德公司的政策研究员Edward Geist表示,观察AI在模拟中的行为,并与人类进行比较会很有用。同时,他也同意研究团队的看法,即不应该信任AI对战争作出重要的决策,LLM不应作为解决军事问题的「灵丹妙药」。











