大家好,今天要给大家推荐一款堪称全能的开源Markdown格式文件提取器— MinerU 。

这款开源工具不仅在GitHub上收获了6.9k的星星,还凭借其强大的数据提取功能俘获了大量开发者和内容创作者的青睐。
MinerU项目介绍

MinerU 是一款一站式的高质量数据提取工具,主要功能包括从PDF、网页和电子书中提取数据,并将其转换为Markdown格式。
它包含两个核心模块: Magic-PDF和 Magic-Doc 。
无论是处理繁琐的PDF文档,还是从网页和电子书中提取有价值的信息,MinerU都能够轻松应对。
该项目采用PyMuPDF以实现高级功能。

Magic-PDF:PDF文档的神奇转换
Magic-PDF 是专为将PDF文档转换为Markdown格式而设计的工具。它不仅支持本地文档的转换,还能处理存储在支持S3协议的对象存储上的文件。主要功能包括:
Magic-Doc:网页与电子书的全能提取
Magic-Doc 则主要负责将网页或多格式电子书转换为Markdown格式,其功能同样令人印象深刻:
作为一个程序员,Markdown格式文档使用的比较多,对于md格式的阅读习惯很深,而MinerU可以轻松实现从各种PDF文档、网页和电子书中提取数据并整理成Markdown格式。
这对于我来说,简直是一大福音,省了不少事情和精力。
精准识别版面元素,自动删除页眉页脚信息,保留正文图表

精准解析数学复杂公式
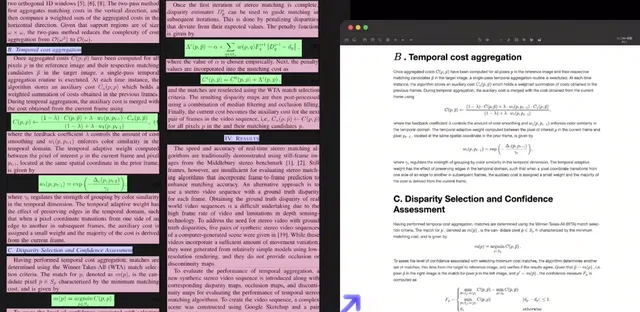
跨模态解析CSDN网页文章
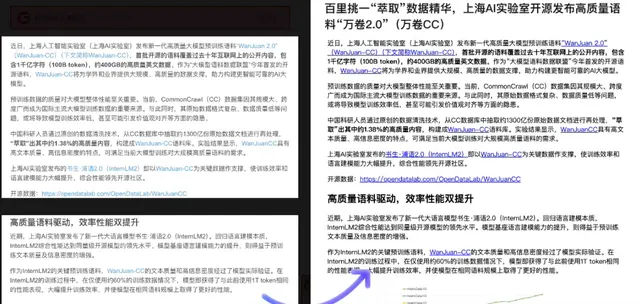
更加支持多种格式文献转Markdown

至于使用的方式,最方便的当然是官方在线Demo:
https://opendatalab.com/OpenSourceTools/Extractor/PDF
也可以自己依据项目说明进行本地或在线部署,毕竟人家是开源的(不过部署起来有些许麻烦,涉及许多配置及模型)
具体的需访问GitHub项目主页(https://github.com/opendatalab/MinerU),根据文档进行安装配置,即可开始使用。
总结
总的来说,MinerU是一款非常实用且强大的数据提取工具。无论你是开发者、互联网从业者,还是有具体需求的新人小白,MinerU都能极大地提升你的工作效率,让你专注于更有价值的工作。
最后,如果你对MinerU感兴趣,不妨亲自尝试一下,相信你会爱上这款全能的Markdown格式文件提取器。











