背景
这里将展示如何使用 Python 创建一个简单但实用的数字孪生。
锂离子电池将成为我们的实物资产。
该数字孪生将使我们能够分析和预测电池行为,并且可以集成到任何虚拟资产管理工作流程中。
名词1:虚拟系统和数字孪生
数字孪生(Digital Twin)是工业 4.0 的关键组成部分。
其基本原理是在虚拟世界中复制物理资产以对其动态进行建模。
数字孪生由三部分组成:
- 物理实体 :指实际存在的物理设备或系统。
- 数字映射 :指物理实体在数字世界中的虚拟模型。
- 数据连接 :指物理实体与数字映射之间的实时数据传输和反馈。
数字孪生通过传感器和物联网技术,将物理实体的实时数据传输到数字映射中,并通过大数据分析、人工智能和仿真技术,对设备的运行状态进行监测、分析和预测。
这个「twin」预计会以其「physical twin」相同的方式响应输入变量。
该虚拟对象必须集成一个模型才能做到这一点。
数字孪生最重要的特征是可以在数字环境中模拟「物理」行为的模型。
当我们说「物理」时,我们指的是任何现实世界的实体(可以是锂离子电池、水泵、人、城市或猫)。
任何可以建模的东西都可以虚拟化。

通过模型从物理世界到虚拟世界
名词2:锂离子电池数字模型
可充电锂离子电池是一种尖端电池技术,其电化学依赖于锂离子。
除了便携式技术设备之外,这些电池也是电动汽车和配电网络储能等应用的重要资产。
这些电池最关键的方面是它们的老化成本。
经过反复的充放电循环后,电池的电芯会退化,导致充电容量下降。
这种现象一直是开发更持久电池的关键研究领域。它的模型同样也是一个有争议的话题。
更多细节在下面代码中再详细介绍。
完整代码
1、导入包
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitimport kerasimport tensorflow as tffrom keras.models importSequentialfrom keras.layers import LSTM,Densefrom keras.optimizers import SGDfrom tensorflow.keras.layers importDropoutfrom matplotlib import pyplot as pltimport plotly.express as pxfrom plotly.subplots import make_subplotsimport plotly.graph_objects as goimport plotly.figure_factory as ff
2、加载数据
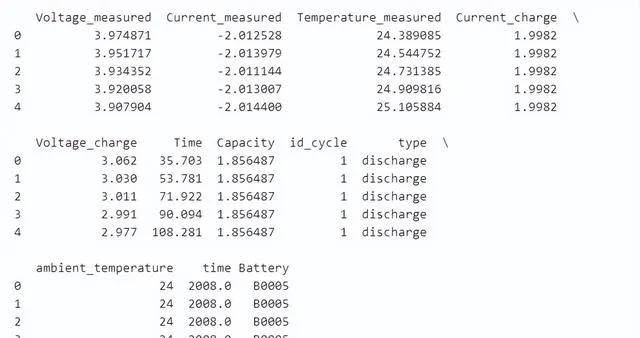
df = pd.read_csv('discharge.csv')print( df.head())# 筛选出了电池编号为 'B0005' 的数据df = df[df['Battery']=='B0005']# 进一步筛选了温度测量值大于 36 的数据df = df[df['Temperature_measured']>36]# 筛选后的 df 数据框按照 id_cycle 列进行分组,并对每个分组内的列取最大值dfb = df.groupby(['id_cycle']).max()# 添加了一个新列 Cumulated_T 到 dfb 数据框中,该列是 Time 列的累积和(累计时间)。# 这意味着 Cumulated_T 的每一行值是从第一个周期到当前周期结束的时间总和dfb['Cumulated_T']= dfb['Time'].cumsum()
数据集介绍:
- Voltage_measured :测量的电压值(单位:伏特)。
- Current_measured :测量的电流值(单位:安培)。负值表示放电状态。
- Temperature_measured :测量的温度值(单位:摄氏度)。
- Current_charge :充电电流值(单位:安培)。
- Voltage_charge :充电电压值(单位:伏特)。
- Time :测量时间点(单位:秒)。
- Capacity :电池的容量(单位:安时)。
- id_cycle :放电周期的编号。
- type :操作类型(放电或充电)。
- ambient_temperature :环境温度(单位:摄氏度)。
- time :数据记录的年份。
输出:
创建散点矩阵图
展示 DataFrame 中各个变量之间的关系,通过散点矩阵图可以一次性地看到多个变量之间的散点关系和分布情况,有助于数据探索和分析
import plotly.express as pxfig = px.scatter_matrix(dfb.drop(columns=['Time','type','ambient_temperature','time','Battery']),)fig.update_traces(marker=dict(size=2, color='crimson', symbol='square')),fig.update_traces(diagonal_visible=False)fig.update_layout( title='电池数据集', width=900, height=1200,)fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white', font=dict(size=7))fig.show()
创建散点矩阵图
展示 DataFrame 中各个变量之间的关系,通过散点矩阵图可以一次性地看到多个变量之间的散点关系和分布情况,有助于数据探索和分析

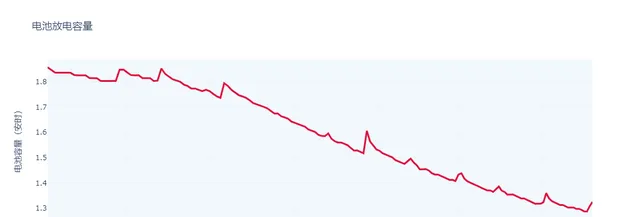
fig = go.Figure()fig.add_trace(go.Scatter(x=dfb['Cumulated_T']/3600, y=dfb['Capacity'], mode='lines', name='Capacity', marker_size=3, line=dict(color='crimson', width=3)))fig.update_layout( title="电池放电容量", xaxis_title="工作时间 [小时]", yaxis_title=f"电池容量(安时)")fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white')
3、定义物理模型
根据参考文献 [1],物理模型的基本方程如下:
L =1−(1− L ′) e − fd
其中, L 表示电池的寿命, L ′ 表示初始电池寿命。 fd 是单位时间和循环的线性降解率。它可以描述为:
fd = fd ( t , δ , σ , Tc )
其中, t 表示充电时间, δ 表示循环放电深度, σ 表示循环平均充电状态, Tc 表示电池温度。电池容量的方程可以写为:
C = C 0 efd
经验上发现, fd 可以近似表示为:
fd = tkTci
其中, k =0.13 , i 表示循环数, t 表示每个循环的充电时间。
# 用来计算电池的寿命(L)和电池容量的变化from math import e# 计算电池寿命L = (dfb['Capacity']-dfb['Capacity'].iloc[0:1].values[0])/-dfb['Capacity'].iloc[0:1].values[0]K = 0.13# 来计算电池的寿命 L_1 = 1-e**(-K*dfb.index*dfb['Temperature_measured']/(dfb['Time']))dfb['C. Capacity'] = -(L_1*dfb['Capacity'].iloc[0:1].values[0]) + dfb['Capacity'].iloc[0:1].values[0]
比较了一个物理模型(Physical model)预测的电池容量变化和 NASA 数据集中记录的实际电池容量
fig = go.Figure()fig.add_trace(go.Scatter(x=dfb.index, y=dfb['C. Capacity'], mode='lines', name='物理模型', line=dict(color='navy', width=2.5,)))fig.add_trace(go.Scatter(x=dfb.index, y=dfb['Capacity'], mode='markers', marker=dict( size=4, color='grey', symbol='cross'), name='NASA 数据集', line_color='navy'))fig.update_layout( title="物理模型比较", xaxis_title="循环数", yaxis_title=", 容量 [安时]")fig.update_layout(legend=dict( yanchor="top", y=0.9, xanchor="left", x=0.8))fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white')

4、将实验数据与物理模型进行比较
评估物理模型预测的电池容量 (dfb['C. Capacity']) 与实际观测数据 (dfb['Capacity']) 之间的平均绝对误差。MAE 越小表示物理模型预测的精度越高。
# 平均绝对误差M = pd.DataFrame()S = pd.DataFrame()def MAE(M,S): return np.sum(S-M)/len(S)print(f'平均绝对误差 =', round(MAE(dfb['Capacity'], dfb['C. Capacity']), 3))
输出:
平均绝对误差 = 0.004
5、混合数字孪生模型
# 输入(X_in)和输出(X_out)的定义,并将它们分割为训练集和测试集。# 准备数据,以便将其用于训练和测试混合数字孪生模型或其他预测模型,然后评估模型的预测能力X_in = dfb['C. Capacity'] # input: the simulation time seriesX_out = dfb['Capacity'] - dfb['C. Capacity'] # output: difference between measurement and simulationX_in_train, X_in_test, X_out_train, X_out_test = train_test_split(X_in, X_out, test_size=0.33)
# 在Keras中,Dense函数构建一个全连接的神经网络层,自动初始化权重和偏差。# 第一个隐藏层model = Sequential()model.add(Dense(64, activation='relu'))model.add(Dense(64, activation='relu'))model.add(Dense(1))
开始训练
# 使用 Keras 训练神经网络模型,具体涉及模型的编译和训练过程。epochs =100loss ="mse"model.compile(optimizer='adam', loss=loss, metrics=['mae'],#Mean Absolute Error)history = model.fit(X_in_train, X_out_train, shuffle=True, epochs=epochs, batch_size=20, validation_data=(X_in_test, X_out_test), verbose=1)

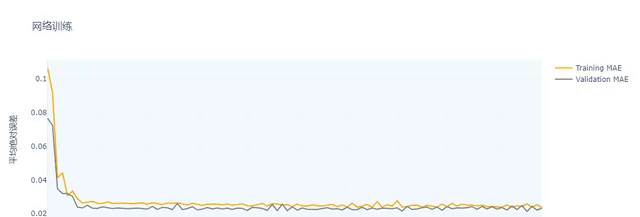
创建了一个图表,展示了神经网络模型训练过程中训练集和验证集的平均绝对误差(MAE)随着 epochs 的变化情况
fig = go.Figure()fig.add_trace(go.Scatter(x=np.arange(0, epochs,1), y=history.history['mae'], mode='lines', name=f'Training MAE', marker_size=3, line_color='orange'))fig.add_trace(go.Scatter(x=np.arange(0, epochs,1), y=history.history['val_mae'], mode='lines', name=f'Validation MAE', line_color='grey'))fig.update_layout( title="网络训练", xaxis_title="训练轮数", yaxis_title=f"平均绝对误差")fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white')
6、编译混合数字孪生模型
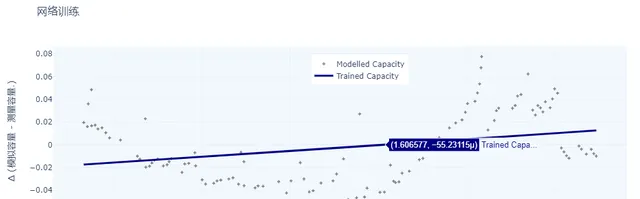
fig = go.Figure()fig.add_trace(go.Scatter(x=X_in_train, y=X_out_train, mode='markers', name=f'Modelled Capacity', marker=dict( size=4, color='grey', symbol='cross'), line_color='crimson'))fig.add_trace(go.Scatter(x = X_in_train, y=model.predict(X_in_train).reshape(-1), mode='lines', name=f'Trained Capacity', line=dict(color='navy', width=3)))fig.update_layout( title="网络训练", xaxis_title="模拟容量", yaxis_title="Δ (模拟容量 - 测量容量.)")fig.update_layout(legend=dict( yanchor="top", y=0.95, xanchor="left", x=0.45))fig.update_layout({'plot_bgcolor':'#f2f8fd',#or azure'paper_bgcolor':'white',},template='plotly_white')
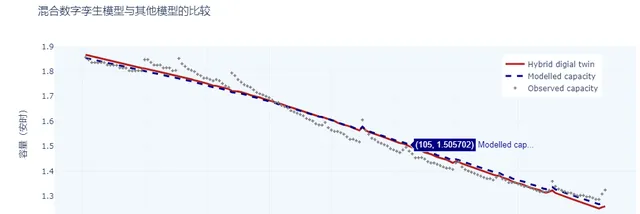
X_twin = X_in + model.predict(X_in).reshape(-1)fig = go.Figure()fig.add_trace(go.Scatter(x=dfb.index, y=X_twin, mode='lines', name=f'Hybrid digial twin', line=dict(color='firebrick', width=3)))fig.add_trace(go.Scatter(x=dfb.index, y=dfb['C. Capacity'], mode='lines', name=f'Modelled capacity', line=dict(color='navy', width=3, dash='dash')))fig.add_trace(go.Scatter(x=dfb.index, y=dfb['Capacity'], mode='markers', marker=dict( size=4, color='grey', symbol='cross'), name=f'Observed capacity', line_color='navy'))fig.update_layout( title="混合数字孪生模型与其他模型的比较", xaxis_title="循环数", yaxis_title="容量(安时)")fig.update_layout(legend=dict( yanchor="top", y=0.95, xanchor="left", x=0.77))fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white')
7、使用混合数字孪生模型进行预测
import numpy as npfrom math import e# 定义循环数和温度cycles = np.arange(168,500,1)temperature = dfb['Temperature_measured'].iloc[167]time = dfb['Time'].iloc[167]# 计算 L_eK =0.13L_e =1- np.exp(-K * cycles * temperature / time)# 计算模拟的初始容量X_in_e =-(L_e * dfb['Capacity'].iloc[0:1].values[0])+ dfb['Capacity'].iloc[0:1].values[0]# 转换 X_in_e 的形状和类型以符合模型的输入要求X_in_e = X_in_e.reshape(-1,1).astype(np.float32)# 进行预测predicted_values = model.predict(X_in_e).reshape(-1)# 计算混合数字孪生模型的预测容量C_twin_e = X_in_e + predicted_values# 打印结果,调试用print(f"Cycles: {cycles}")print(f"Temperature: {temperature}")print(f"Time: {time}")print(f"L_e shape: {L_e.shape}, X_in_e shape: {X_in_e.shape}, predicted_values shape: {predicted_values.shape}")print(f"C_twin_e: {C_twin_e}")

cycles = np.arange(168,500,1)temperature = dfb['Temperature_measured'].iloc[167]time = dfb['Time'].iloc[167]# 计算 L_eK =0.13L_e =1- np.exp(-K * cycles * temperature / time)# 计算模拟的初始容量X_in_e =-(L_e * dfb['Capacity'].iloc[0:1].values[0])+ dfb['Capacity'].iloc[0:1].values[0]# 转换 X_in_e 的形状和类型以符合模型的输入要求X_in_e = X_in_e.reshape(-1,1).astype(np.float32)# 进行预测predicted_values = model.predict(X_in_e).reshape(-1)# 计算混合数字孪生模型的预测容量C_twin_e = X_in_e + predicted_valuesprint(C_twin_e)
X_twin = X_in + model.predict(X_in).reshape(-1)fig = go.Figure()fig.add_trace(go.Scatter(x=cycles, y=X_in_e, mode='lines', name=f'C modelled (predicted)', line=dict(color='navy', width=3, dash='dash')))fig.add_trace(go.Scatter(x=cycles, y=C_twin_e, mode='lines', name=f'C Digital twin (predicted)', line=dict(color='crimson', width=3, dash='dash')))fig.add_trace(go.Scatter(x=dfb.index, y=X_twin, mode='lines', name=f'C Digital twin', line=dict(color='crimson', width=2)))fig.add_trace(go.Scatter(x=dfb.index, y=dfb['C. Capacity'], mode='lines', name=f'C modelled', line=dict(color='navy', width=2)))fig.update_layout( title="电池容量预测", xaxis_title="循环数", yaxis_title="电池容量 [安时]")fig.update_layout(legend=dict( yanchor="top", y=0.95, xanchor="left", x=0.72))fig.update_layout({'plot_bgcolor':'#f2f8fd','paper_bgcolor':'white',},template='plotly_white')

参考:
https://towardsdatascience.com/how-to-build-a-digital-twin-b31058fd5d3e











