
概述
这篇论文提出了一种名为视觉模块插件多模态检索模型(MARVEL),它学习了一个嵌入空间,用于对查询和多模态文档进行检索。MARVEL使用统一的编码器模型对查询和多模态文档进行编码,这有助于减少图像和文本之间的模态差异。具体来说,我们通过将视觉模块编码的图像特征作为输入,增强了训练有素的密集检索器T5-ANCE的图像理解能力。为了促进多模态检索任务,我们基于ClueWeb22数据集构建了ClueWeb22-MM数据集,该数据集将锚文本视为查询,并从锚链接的网页中提取相关的文本和图像文档。我们的实验表明,MARVEL在多模态检索数据集WebQA和ClueWeb22-MM上显著优于最先进的方法。MARVEL提供了一个机会,将文本检索的优势扩展到多模态场景。此外,我们还展示了语言模型具有提取图像语义的能力,并能将部分图像特征映射到输入词嵌入空间。
论文地址:
https://arxiv.org/pdf/2310.14037
代码地址:
https://github. com/OpenMatch/MARVEL
01
Multi-Modal Retrival
随着互联网和多模态内容的增长,越来越多的浏览器或应用程序能够更轻松地返回相关内容给用户。
多模态检索任务的目标是根据用户查询从多模态源(如图像和文本)中检索文档。它侧重于查询和多模态文档之间的相关性建模,而不是文本-图像匹配。在某些场景中,使用图像来回答查询可能更为合适,如左图所示。
例如,对于「谁是图灵」的查询,它不仅返回文本,还可能提供图像。主要检索方法有两种:第一种是「分而治之」,就是分别进行图片和文本检索,然后采用某种方式如视觉语言模型合并检索结果;第二种是使用统一的视觉-语言模型进行综合检索。

现有的通用视觉-语言密集检索模型学习了一个用于多模态文档的通用嵌入空间,允许它在不同模态之间搜索候选项。然而,在编码过程中,文本和图像使用不同的编码器。为了缩小模态差异,UNIVL-DR将图像特征转化为文本,以增强原始文本空间中的图像文档。
本文中,作者旨在解决这样一个问题:能否建立一个统一的多模态的编码模型,将多模态信息映射到统一的三维空间中,以缓解不同编码器带来的模态差异。

02
Multi-modAl Retrieval model with MARVEL
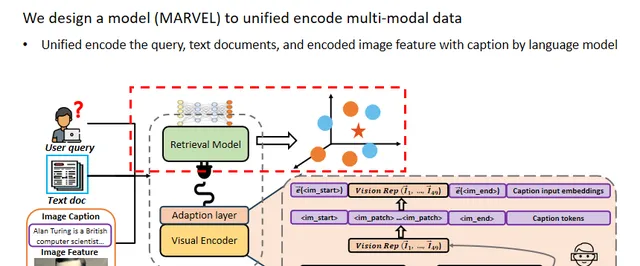
在这篇工作中,作者设计了一个多模态检索模型MARVEL,通过视觉模块插件,统一编码图像和文本文档以及查询,以减轻图像和文本之间的模态差异。
文中使用插件视觉模块对图像特征进行编码并映射到语言模型空间。具体来说,使用CLIP的视觉编码器来编码图像特征,并使用一个适配层将视觉表示投影到密集检索模型的词嵌入空间,然后将视觉表示和图像标题词嵌入进行拼接。
此外,本文使用两个特殊标记和来指示图像特征的开始和结束。
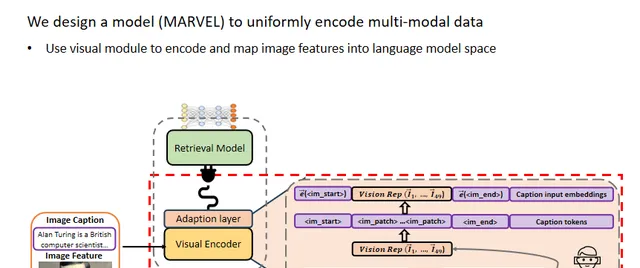
随后,将图像特征和标题的联合嵌入输入到语言模型中,以获得图像文档的表示。
对于查询和文本文档,作者直接使用语言模型对它们进行编码。最终,查询、图像文档和文本文档都被映射到一个通用的嵌入空间中,以进行多模态密集检索。
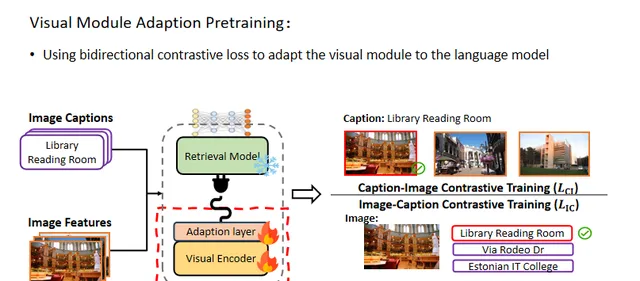
在预训练阶段,本文遵循先前的工作,将图像和标题都视为查询,以计算双向对比学习损失,这有助于通过联合损失对齐图像和文本的模态。在整个过程中,仅更新视觉编码器和适配层的参数,以使视觉模块适应语言模型。
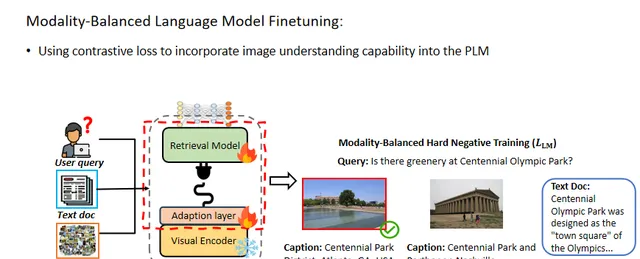
在微调阶段,作者冻结视觉编码器的参数并更新其他参数。为了减轻模态歧视问题并将图像理解能力整合到语言模型中,本文采用了模态平衡的硬负样本训练方法,以对齐查询与正样本候选项,并引导模型选择正确的模态,并保证嵌入空间的统一。
03
ClueWeb22-MM Dataset
此外,为了促进多模态检索任务,作者基于ClueWeb22构建了ClueWeb22-MM数据集,其规模与现有的开源数据集WebQA相匹配。
文中将锚文本视为查询,并将链接网页中的相应图像或文本文档视为其最佳的相关文档。
本文使用ClueWeb22-MM和WebQA数据集进行微调和推理,并使用从ClueWeb22数据集中提取的图像-标题对进行预训练。相应的统计数据在右侧的表格中展示。

04
Overall Performance
本文首先评估了MARVEL和现有模型的整体检索性能。
与主要基线UniVL-DR相比,MARVEL在两个数据集上的检索效率都有显著提高,证明了使用通用模型缓解模态差异的有效性。
此外,如图中所示,当用户询问「在‘和平与繁荣’中可以找到哪两种动物?」时,MARVEL可以直接提供一幅名为「和平与繁荣」的画作,帮助用户回答这个问题。

05
Effectiveness of Fusion Strategies
关于视觉-语言模型的融合方法,作者测试了三种不同的模态融合策略:插件式(plugin)、拼接(concatenation)和求和(sum)。
拼接和求和方法分别对图像和标题进行编码,然后将嵌入向量进行拼接或求和,以获得最终的表示。
本文实验表明,插件式方法可以通过联合建模文本和图像来缓解模态差异,并通过语言模型的注意力头促进图像和文本之间的更深层次交互,从而实现最佳的检索结果。
06
Effectiveness of Visual Module Adaption Pretraining
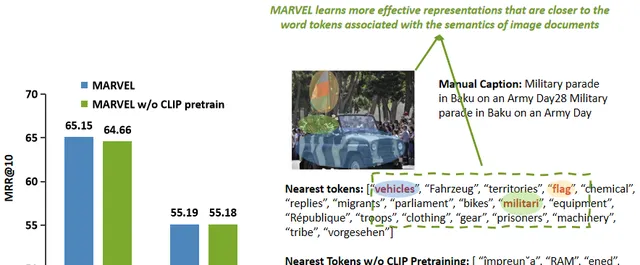
为了验证视觉模块适配预训练的有效性,本文在两个数据集上测试了模型的检索性能。
通过视觉模块预训练,MARVEL的检索能力得到了显著增强,这为将视觉模块适配到语言模型提供了一些机会。

然后,取视觉模块编码的图像向量,并使用余弦相似度来找到它们最接近的词元。
如图中所示,通过视觉模块预训练,MARVEL学习了更有效的表示,这些表示更接近图像的语义。它从图像中捕获了更细粒度的语义信息,例如车辆、旗帜和军事。
相比之下,未经预训练的模型只能捕获图像中描绘的国家的信息。
07
Effectiveness of Finetuning Strategies
然后,作者在文本/图像/多模态检索任务上进行了实验,以展示四种不同微调策略的有效性。在这四种策略中,适配层始终会被更新。
当仅微调T5的参数时,MARVEL在图像和多模态检索任务上取得了显著的改进,特别是与其他模型相比,这证明了MARVEL在将视觉模块适配到密集检索模型上的强能力。

01
Conclusion
本文提出了一个多模态检索模型MARVEL。通过使用视觉模块插件,作者通过通用建模减轻了图像和文本之间的模态差异,将文本检索模型的优势引入到了多模态检索任务,并在两个数据集ClueWeb22-MM和WebQA上都达到了最佳水平
本文的预训练和微调方法使语言模型能够有效地提取图像语义,并将图像特征部分映射到语言词嵌入空间。
此外,作者构建了一个多模态检索基准ClueWeb22-MM,以进一步推进多模态检索领域的发展。











