北大陈宝权教授:从图形计算到世界模型

近日,北京大学的陈宝权教授在第九届计算机图形学与混合现实研讨会(GAMES 2024)上,发表了主题演讲【从图形计算到世界模型】,分享了他在图形仿真与世界模型关系上的独特见解。文章将整理陈教授的报告,期待启发大家的思考与讨论。当今,世界模型成为炙手可热的话题,本次演讲以「图形计算到世界模型」为出发点,探讨二者可能形成的深厚联系。借助GAMES这一平台,陈教授希望大家能够大胆分享观点,启发更深入的交流。

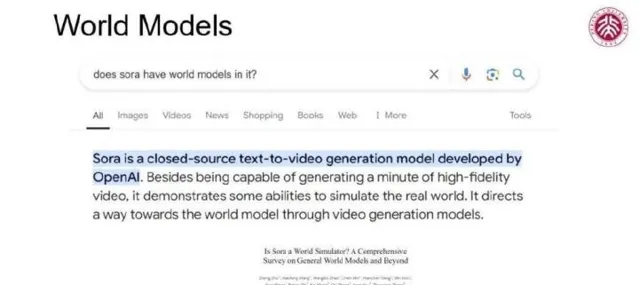
随着近年来AIGC领域的迅猛发展,大型模型备受瞩目。尤其是通过简单的文字输入,模型能够生成连贯且逻辑性强的场景。这引发了一个自然的思考:这些模型是否背后隐藏着某种世界模型?这个问题的核心直接关系到AI技术的根本,在这个领域内,行业内正展开对模型机制与能力的深入探讨。笔者特意在Google上查找「Sora是否具有世界模型」,结果显示,Sora确实展现了模拟真实世界的能力,这一发现与在场的Jiwen老师的相关研究不谋而合。该研究探讨了多种生成模型,指出Sora等模型的视觉元素与世界模型特性之间的联系。
那么,世界模型究竟是什么?如今,学界与业界对其并没有达成严格的定义。回顾历史,LSTM的开创者Schmidhuber及其学生在论文中探讨了这一概念,强调其在预测与规划决策的核心地位。换句话说,具备通过当前信息预测未来状态并进行相应决策能力的模型,那便可视为拥有世界模型特征。这一观点虽然并未提供细致的结构性描述,却为理解世界模型提供了实用视角。

在人工智能领域的重要人物Yann LeCun也严格分析了世界模型的概念,尽管他并没有给出明确的定义,主要能力如预测、推理、决策及规划等,与我们目前所讨论的内容完全一致。值得注意的是,LeCun的观点甚至将世界模型的功能与人类大脑的运作进行了类比。GPT-4o的回答也给出了类似的描述:世界模型是一种具备模拟、预测、规划和决策能力的系统。这种系统通过对大量数据的学习、理解,构建现实世界的内部模型,从而模拟不同情境下的结果,并制定最佳决策。

通过简明的示意图,我们能直观理解世界模型。真实场景作为输入,经由具有分析、评估及模拟能力的世界模型,最终实现符合实际情况的未来预测与决策推理。这一模型展现了人工智能技术处理复杂信息的能力,让我们看到它在多种应用中的潜力。如今,各大型AI模型已在复杂场景中展现优异性能,尤其是在无人驾驶领域,有着显著的进展。
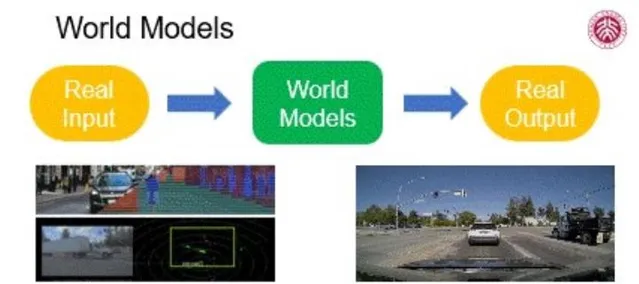
在无人驾驶技术中,高度真实的仿真系统能够模拟多种传感器,如激光雷达、摄像头、声音传感器等,生成丰富的多模态数据,借此构建庞大的训练数据集。后续,该模型能够在全新的场景中精确感知环境,完成动态预测和判断决策。比如,有些项目如nuScenes超越了传统的KITTI数据集,为模型提供了更全面的学习资料。此外,英伟达等科技巨头在无人驾驶的仿真方面投入了巨资,加速了相关技术的发展和应用。总体看来,人工智能技术已经实现了从真实场景输入到适应输出的完整链条,表明其正在朝着成熟的方向发展,实际应用也将迅速推广。

接下来的讨论将围绕如何构建更完整的世界模型展开。尽管如今在语言与视频等大模型展现出强大能力,这一切仅是构建世界模型征途的起点。大模型由海量数据「喂养」,取得显著成效,但我们所能产生的数据远未触及边界,可能的训练方式也仍有许多。我将从几个核心维度讨论:数据丰富性、训练模式、增强的监督机制,以及这些要素的有机融合,推动世界模型的构建。

simulation在这一过程中扮演着关键角色。图形计算的独特目标便是模拟现实世界,因此我将其视作simulation。在模拟真实世界方面,通过simulation来训练模型、加速其迭代、验证等展现出巨大价值。我们应首先观察现有大模型训练中的基本原则与局限性。在这个过程中,一个显著的观察是数据量与模型损失之间的关系。尽管常以线性方式描述,实际联系更接近于对数关系,这意味着模型对数据的需求呈指数增长。随着训练深入,数据需求迅猛增加,数据资源亦在迅速枯竭,尤其是在涉及更高维度的数据处理时。二维领域的数据需求庞大,如德国的LAION项目展现的5TB数据量,尽管衍生版本经清理发布,但数据量依然可观,然而在三维数据领域却相对匮乏。

这一点正展示出三维数据的极度稀缺,成为当前人工智能与计算机视觉研究的挑战。因此,simulation的价值愈加突出。鉴于数据的有限性,如何系统性地生成更多的高质量、有标签数据成为关键,而simulation恰好满足这一需求。如今,计算机图形技术已经远不止特效制作和图像编辑,它的力量在于构建simulation系统,生成海量数据,扩展数据集规模,为大模型训练提供了重要支持。

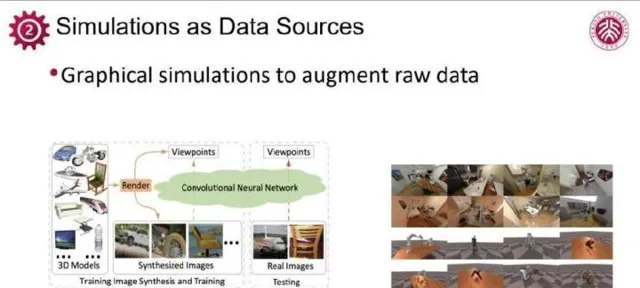
许多关于数据生成的初步探索已经取得了成功,如UCSD苏昊团队早期在图像姿态估计任务上的研究。他们基于带有pose标注的图像进行卷积神经网络的训练。由于现实世界图像中pose标注数量有限,不足以训练出有效的模型,苏昊团队利用ShapeNet等三维数据集,经过3D渲染生成了大量带有姿态信息的图像数据,显著丰富了训练样本。这种生成数据的方法有助于解决现实数据标注匮乏的问题。

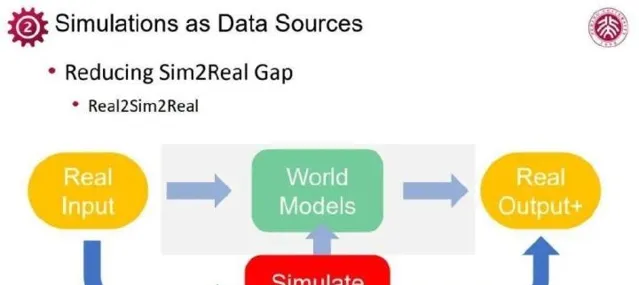
此外,苏昊团队及其他研究者还探索了复杂场景交互功能,如柜门开启、物体抓取等,更贴近真实世界交互,为机器人训练等应用提供支持。可见,通过图形计算提供的simulation能力,已经成为生成高质量、多功能教学数据的核心手段。虽然模拟与真实现象之间仍有差距,然而为了更好地生成贴近现实的数据,在具身智能等智能应用上,可以运用「real to sim」与「sim to real」的策略,前者是通过获取真实世界传感数据搭建相应的仿真环境,后者是通过改变模拟参数,生成更多样的场景。
如若在这方面真正获得进展,simulation取自真实世界的物理原理,需保证在各类动态、交互上的真实性,通过simulation来实现令人信服的「as-real-as-possible」。尽管「sim to real」不断追求真实,但完全消除二者间的异同仍是难题。通常,在部署阶段,往往还需「real to real」微调,获取真实环境中的输入输出数据,进一步增强模型性能。
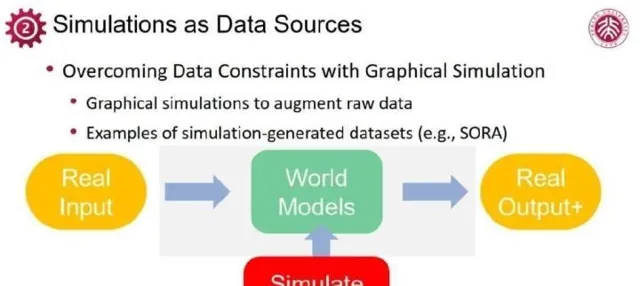
对众多复杂应用场景,Real2Real数据十分有限,完全依赖于这类数据实现具身智能恐怕不够。通过结合真实数据的simulation,展现出高真实数据生成的潜力,Real2Sim2Real框架便成为推动具身智能发展的重要路径。在工业界迅速发展的无人驾驶领域,现实到模拟与模拟到现实的双向转换已取得初步成效。仅局限在数据生成的领域显然低估了simulation的潜力,图形仿真不再止于充当数据提供者,而是变成了训练环境的构建者。
通过深度强化学习等先进技术,图形仿真为训练过程提供环境支持,使智能体得以学习、优化决策能力。而这正是构建世界模型的重要职能,涉及理解、预测、策略与执行等多个方面。作为计算机图形领域的研究者,陈教授为图形学在未来人工智能的发展中发挥越来越重要的作用感到自豪。

在不同领域,数字人和机器人的运动控制,无人车行为调整等都在利用深度强化学习作为有效训练方式。这一方法利用simulation环境中丰富的交互场景,通过深度强化学习决策背后的策略,获得更有效的预测能力。北京大学刘利斌教授关于数字人体运动控制的研究,结合了仿真环境等多个方向,取得了显著成果。在这些强化学习研究中,物理仿真环境的有效互动极大地提升了模型的鲁棒性和泛化能力。

如同上述,基于训练过程中捕获的真实人体动作,刘教授的团队通过模拟环境与深度强化学习紧密结合,成功掌握了一些复杂的运动策略,如滑滑板、使用筷子等。模拟的精准性至关重要——越精准,学习质量越高,越接近现实。比如,近期研究中的肌肉模型不仅超越了传统的关节动画,更贴近人体真实运动机制,模拟诸多细节,比如长时间跑步后的疲惫与动作变化。

在机器人领域,一些较新的研究利用英伟达的Omniverse平台等高效仿真框架,推进了仿真技术的进步与创新。因此,现实世界中物体变化与动态现象的复杂性与多样性,需要我们不断探索更精确与全面的仿真环境,模拟这些丰富的物理现象。

可微模拟的重要性在于通过可微分性原则,实现精细的梯度回传机制,构建出监督学习的闭环,优化学习过程。转变依赖于simulation全面实现可微分,保证有效的梯度传递与策略优化。虽然可微模拟领域已有初步探索,整体研究仍显薄弱,但越来越受到重视。在这方面的一个亮点便是与模型的逆向软体仿真结合。

通过捕捉真实荷叶在外力下晃动的数据,结合物理模型与参数,建立可微模拟系统,前向模拟荷叶运动,并通过优化实现准确拟合,使我们能够准确模拟荷叶在不同条件下的响应。同样,针对流体,基于可微性的技术也在实现真实流体重建上发挥潜力。可微模拟赋予了我们设计软体机器人的形状与物理参数能力,带来了广泛应用的可能性。

当前,尽管在全部可微模拟中已取得重要进展,实际应用场景仍面临局限与资源需求高等挑战,部分复杂现象非平滑性捆绑了技术的提升。但整体而言,探索这一领域的潜力无可置疑。总结来说,图形仿真在世界模型训练中发挥着关键作用,潜在的发展路径宽广且充满机遇。希望大家能够继续挖掘这些强大潜能,为未来建立更深入的讨论。期待与各位的热烈交流!












