ChatGPT的爆火带动了AIGC相关产业链的发展。也激发了大众研究探索AI的热情。本文主要介绍AI领域的一些基础概念及技术。
AI :人工智能 (artificial intelligence) 。属于计算机科学领域,致力于解决与人类智慧相关的常见认知问题,例如学习、创造和图像识别等。AI的目标是建立能从资料中取得有用知识的自学习系统。
AIGC :生成式人工智能 (Adversarial Generative Intelligence) 。属于机器学习的一个分支。是一种可以创造新内容和想法的人工智能,包括创造对话、故事、图片、视频和音乐。ChatGPT和Sora等都是AIGC技术的一种应用。
AGI :通用人工智能 (Artificial general intelligence) 。是指具有自主自控能力、合理的自我理解能力以及能够学习新技能的AI系统。它可以处理人类未曾训练过它的复杂问题。它可以在存在不确定性因素时进行推理,甚至使用策略来解决问题。同时具有制定决策的能力。也就是说它的智力水平是和人类相当甚至高于人类的。具有人类能力的AGI目前仍处于理论研究阶段。
算法 :算法是一组明确的、有序的步骤或规则,用于解决特定问题或执行某项任务。它是计算机科学的核心概念之一,也是许多其他学科的基础。算法可以用来处理各种类型的数据和任务,从简单的算术运算到复杂的数据分析和机器学习。
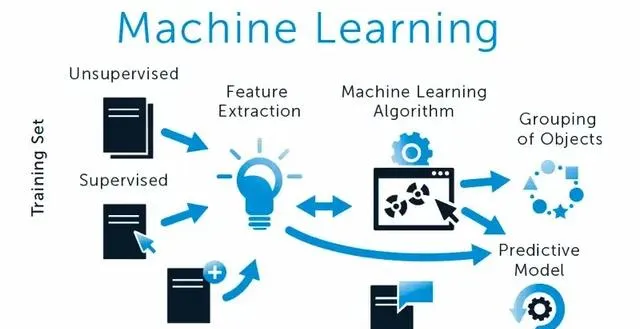
机器学习 :机器学习(Machine Learning,ML)是人工智能(AI)的一个重要分支,它通过数据和算法使计算机系统能够自主学习和改进,而无需人为编程。机器学习的核心是开发能够从数据中提取特征并做出预测或决策的算法。机器学习又分为监督机器学习和无监督机器学习两种。 两者的区别即给出的用于学习的数据是否存在标签。
常用的机器学习算法有神经网络、线性回归、逻辑回归、聚类、决策树、随机森林等。目前用于开发机器学习相关算法的机器学习框架主要有TensorFlow、PyTorch、Keras、PaddlePaddle等。
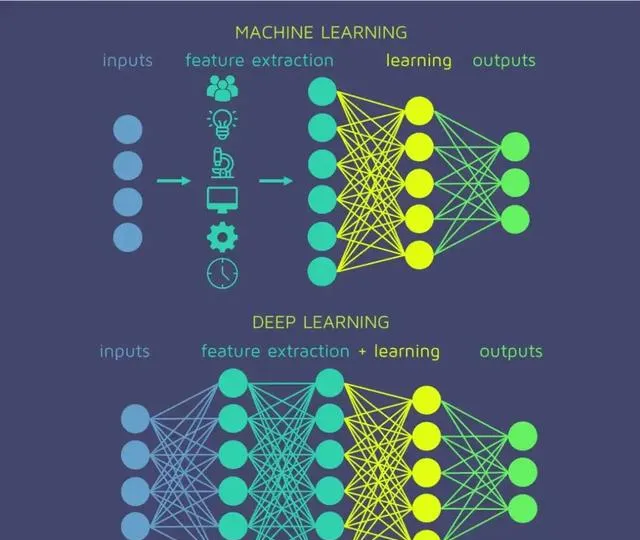
深度学习 :深度学习是机器学习的一个分支。许多传统机器学习算法学习能力有限,知识是从数据中获取的,但是只是增加数据量并不能持续增加学到的知识总量。深度学习系统可以通过访问更多数据来提升性能,即「更多经验」的机器代名词。机器通过深度学习获得足够经验后,即可用于特定的任务,如驾驶汽车、识别田地作物间的杂草、确诊疾病、检测机器故障等。
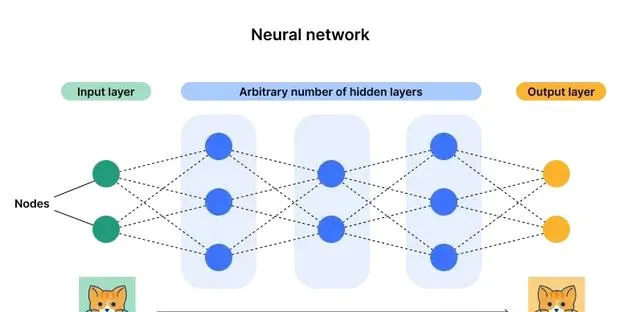
神经网络 :神经网络是一种机器学习程序或模型,它以类似于人脑的方式做出决策,通过使用模仿生物神经元协同工作方式的过程来识别现象、权衡利弊并得出结论。
每个神经网络都由多个节点层或人工神经元组成 , 一个输入层、一个或多个隐藏层和一个输出层。每个节点都与其他节点相连,具有一个关联的权重和阈值。如果任何单个节点的输出高于指定的阈值,那么该节点将被激活,并将数据发送到网络的下一层。否则,不会将数据传递到网络的下一层。神经网络依靠训练数据来学习并随着时间的推移提高其准确性。一旦对其准确性进行微调,它们就会成为计算机科学和人工智能领域的强大工具,使我们能够高速对数据进行分类和聚类。与人类专家的人工识别相比,人工智能进行语音识别或图像识别只需几分钟,而人工识别则需要几小时。神经网络最著名的例子之一就是 Google 的搜索算法。
神经网络有时被称为人工神经网络 (ANN) 或模拟神经网络 (SNN)。它们是机器学习的一个子集,是深度学习模型的核心。
NLP :自然语言处理(Natural Language Processing,NLP)是计算机科学和人工智能的一个重要领域,旨在使计算机能够理解、解释、生成和响应人类自然语言。NLP结合了语言学、计算机科学和统计学的知识,以处理和分析大量自然语言数据,从而实现人机交互、文本分析等任务。

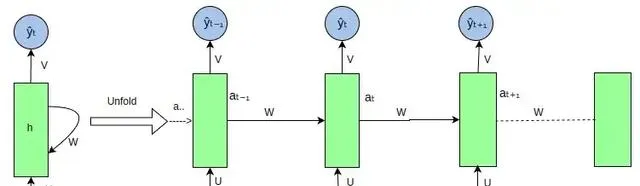
RNN :循环神经网络 (RNN) 是一种使用序列数据或时序数据的人工神经网络。这些深度学习算法常用于顺序或时间问题,如语言翻译、自然语言处理 (nlp)、语音识别、图像字幕等;它们包含在一些流行的应用中,比如 Siri、语音搜索和 Google Translate。与前馈神经网络和卷积神经网络 (CNN) 一样,循环神经网络利用训练数据进行学习。区别在于「记忆」,因为它从先前的输入中获取信息,以影响当前的输入和输出。虽然传统的深度神经网络假设输入和输出相互独立的,但循环神经网络的输出依赖于序列中先前的元素。尽管未来的活动也可能有助于确定特定序列的输出,但是单向循环神经网络无法在预测中说明这些事件。
大模型 :大模型 (large model) ,泛指参数很多的机器学习模型,大模型可以看作是数据转换问题,即输入 序列,输出 序列,其中 = ,这里的W矩阵就可以看作大模型必不可少的参数,这些参数可以影响模型的训练效果和预测能力。根据场景不同,大部分大模型公司把大模型分为大语言模型、计算机视觉(包含图像和视频)、音频、多模态大模型四大类。
LLM :大语言模型(large language model)。是一种利用机器学习技术来理解和生成人类语言的人工智能模型。LLM 使用基于神经网络的模型,通常运用自然语言处理(NLP)技术来处理和计算其输出。目前比较知名的大语言模型有GPT-4、文心一言、通义千问等。

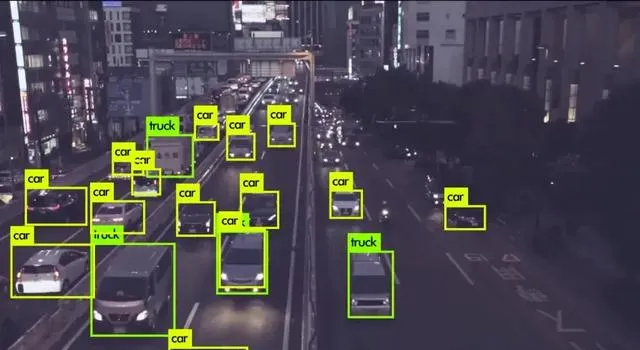
CV :计算机视觉 (Computer vision) 是指让计算机和系统能够从图像、视频和其他视觉输入中获取有意义的信息,并根据该信息采取行动或提供建议。如果说人工智能赋予计算机思考的能力,那么计算机视觉就是赋予发现、观察和理解的能力。

模型库 :可以下载大模型的地方。如国外的Huggingface和国内的ModelScope
模型训练 :模型训练是机器学习中的一个重要步骤,它的作用是从给定的数据集中学习出一个模型,使得该模型能够对新的数据进行准确的预测和分类。
模型推理 :模型推理是指使用训练好的模型来进行预测、分类或回归的过程。模型推理是机器学习的基础,它允许我们使用模型来生成预测结果,给出对未知数据的估计值。在模型推理过程中,我们将训练好的模型输入新的数据,并使用模型产生预测结果。例如,在图像分类中,我们可以使用训练好的卷积神经网络模型来对一张新的图像进行分类。
数据集 :又称为资料集、数据集合或资料集合,是一种由数据所组成的集合。数据反映了真实世界的状况。数据集作为深度学习和机器学习的输入,对AI开发有至关重要的意义。
数据标注 :在机器学习中,数据标注流程用于识别原始数据(图片、文本文件、视频等)并添加一个或多个有意义的信息标签以提供下文,从而使机器学习模型能够从它进行学习。例如,标签可指示相片是否包含鸟或汽车、录音中有哪些词发音,或者 X 影像是否包含肿瘤。各种使用案例都需要用到数据标记,包括计算机视觉、自然语言处理和语音识别。数据标注常用的工具有label-studio等。
pre-training :预训练是一种无监督学习方法,模型通过大量无标签数据进行训练,以捕捉数据的底层结构和模式。在自然语言处理领域,预训练模型通常会学习词汇、语法和句子结构等基本特征。预训练的目的是让模型学会一定程度的通用知识,为后续的微调阶段打下基础。
微调 :微调是一种有监督学习方法,通过在有标签数据上对预训练模型进行进一步训练,以适应特定的任务。这个过程使得模型能够利用预训练阶段学到的通用知识,结合新数据的标签信息,使模型在特定任务上表现更好。
参考资料:https://www.ibm.com/cn-zh/topics?











