微软推出iPhone能跑的ChatGPT级模型,网友:OpenAI得把3.5淘汰了
人工智能的发展如同一场永不停歇的马拉松,各大科技巨头争相角逐,你追我赶。就在Llama 3刚刚露出水面之际,微软却悄然抛出了一记重磅炸弹,让整个AI圈为之震动。
这场AI军备竞赛的最新战报来自微软研究院。他们刚刚发布的Phi-3系列小模型技术报告,犹如一阵清风,吹散了人们对大模型霸权的迷思。其中,仅有3.8B参数的Phi-3-mini模型,在多项基准测试中竟然超越了参数量高达8B的Llama 3。这一惊人成果,无疑为小模型阵营注入了一剂强心针。

更令人瞩目的是,微软此次打出了"手机就能直接跑的小模型"王牌。经过4bit量化后的Phi-3-mini,在iPhone 14 pro和iPhone 15使用的苹果A16芯片上,能够达到每秒12 token的处理速度。这意味着,现在我们的掌上设备也能运行媲美ChatGPT水平的开源模型了。想象一下,在地铁上、咖啡厅里,随时随地都能与智能助手进行高质量对话,这样的未来已经悄然来临。
为了让开源社区更好地使用这一成果,微软还特意将Phi-3系列设计成与Llama系列兼容的结构。这一举措无疑会加速AI技术的普及,让更多开发者能够站在巨人的肩膀上继续创新。
微软的野心并不止步于此。除了迷你版的Phi-3-mini,他们还同时推出了小杯和中杯版本。Phi-3-small拥有7B参数,为了支持多语言,特意换用了tiktoken分词器,并额外增加了10%的多语种数据。而14B参数的Phi-3-medium更是在更多数据上进行了训练,在多数测试中已经超越了GPT-3.5和Mixtral 8x7b MoE这样的强劲对手。

有趣的是,微软在技术报告中还玩了一个小花招。他们让Phi-3-mini自己解释为什么构建小到手机能跑的模型如此令人惊叹。这种自解释的能力,不禁让人联想到人工智能是否已经开始具备某种程度的自我意识。
然而,真正令人惊叹的并非模型的大小,而是其背后的技术创新。微软研究团队发现,单纯增加参数量并不是提升模型性能的唯一途径。相反,精心设计的训练数据才是关键所在。他们利用大语言模型本身去生成合成数据,再配合严格筛选的高质量数据,让中小模型的能力实现了质的飞跃。
这种"科书级别"据策略,让Phi-3系列在训练阶段就接触到了最精华的知识。为此,微软团队可谓下了血本,投喂了多达3.3万亿token的训练数据,其中Phi-3-medium更是达到了4.8万亿token。他们不仅大幅强化了数据的"教育水平"过滤,还增加了更多样化的合成数据,涵盖逻辑推理、知识问答等多种技能。

此外,微软还采用了独特的指令微调和RLHF训练方法,大幅提升了模型的对话能力和安全性。这意味着,Phi-3系列不仅聪明,还更懂得如何与人类进行有意义的交流。
随着Phi-3系列的问世,AI领域的竞争格局似乎又要重新洗牌。不少网友已经开始呼吁OpenAI尽快推出GPT-3.5的继任者,以应对这来势汹汹的挑战。然而,无论竞争如何激烈,最终受益的必将是我们这些普通用户。当AI技术变得更加亲民,我们的生活也将随之变得更加智能、便捷。
在这场AI革命中,我们见证了技术的飞速进步,也看到了科技巨头们的雄心壮志。但最令人期待的,或许是这些智能助手将如何改变我们的工作方式、学习方式,乃至思考方式。让我们拭目以待,看看这场由微软掀起的小模型风暴,将如何重塑我们的数字未来。
然而,正如硬币总有两面,Phi-3系列虽然闪耀夺目,却也并非完美无缺。微软坦诚地指出,小模型毕竟受限于其参数规模,无法在模型本身存储太多事实和知识。这一点从TriviaQA测试分数偏低可见一斑。为了弥补这一短板,微软提出了一个聪明的解决方案——联网接入搜索引擎来增强模型的知识储备。这种做法不禁让人联想到人类的学习过程,我们也常常需要借助外部资源来扩充自己的知识库。
微软研究院团队显然已经在小模型与数据工程这条道路上找到了自己的节奏。他们铁了心要在这个方向上继续深耕,未来还计划进一步增强小模型的多语言能力和安全性等关键指标。这种执着与专注,无疑将为AI领域带来更多突破性的创新。
值得一提的是,Phi-3系列的诞生并非偶然。从技术报告的作者阵容中,我们可以看到微软亚洲研究院(MSRA)和微软研究院雷蒙德团队都投入了大量人力。这种跨地域、跨团队的协作,充分展现了微软在AI领域的全球化布局和雄厚实力。
Phi-3系列的核心秘诀,用一句话来概括,就是"数据为王"年,研究团队就发现,单纯增加参数量并不能保证模型性能的线性提升。相反,精心设计的训练数据才是提升模型能力的关键所在。这种洞见引导他们走上了一条与众不同的道路。
他们的方法可以说是别出心裁。比如,在筛选训练数据时,他们会删除那些仅仅增加知识量而不能提高推理能力的数据。举个例子,某一天的足球比赛结果对于提升模型的整体能力可能并不那么重要,因此这类信息就会被剔除,留下更多能够锻炼模型推理能力的高质量数据。
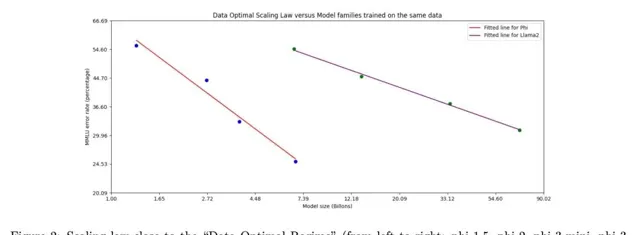
这种近乎苛刻的数据筛选策略,使得Phi-3系列能够以更小的参数量在MMLU测试中获得比Llama-2系列更高的分数。这无疑是一个重要突破,证明了在AI领域,巧妙的策略有时候比单纯的规模更加重要。
Phi-3系列的训练过程也颇具特色。他们不仅使用了大量的高质量数据,还采用了独特的指令微调和RLHF(基于人类反馈的强化学习)训练方法。这些技术的运用大大提升了模型的对话能力和安全性,使得Phi-3系列不仅能够理解和执行复杂的指令,还能够更好地遵循道德和伦理准则。
然而,正如每个新技术都会面临挑战一样,Phi-3系列也存在一些待解决的问题。比如,如何在保持模型小巧的同时,进一步提升其知识储备能力?如何在不增加模型规模的情况下,持续改善多语言处理能力?这些都是微软研究团队未来需要攻克的难题。
尽管如此,Phi-3系列的出现无疑为AI领域注入了新的活力。它向我们展示了,在追求更强大AI的道路上,不仅有参数规模的竞赛,还有数据质量和训练方法的较量。这种多元化的竞争格局,必将推动整个行业向更高水平迈进。
随着Phi-3系列的发布,我们似乎看到了一个新时代的曙光。在这个时代里,强大的AI不再局限于大型数据中心,而是可以被装进每个人的口袋。这意味着,AI技术的民主化进程正在加速,普通用户也将很快能够享受到顶尖AI带来的便利。
随着Phi-3系列的横空出世,AI领域的格局似乎正在悄然改变。这个能在iPhone上流畅运行的ChatGPT级模型,不仅是技术实力的展现,更是对未来AI应用场景的一次大胆探索。
对于普通用户而言,Phi-3的意义可能远超我们的想象。试想一下,当每个人的智能手机都能运行一个媲美ChatGPT的AI助手时,我们的日常生活将会发生怎样的变革?也许在不久的将来,我们可以随时随地获得高质量的语言翻译、个性化的学习辅导,甚至是深度的情感交流。这不仅仅是技术的进步,更是人机交互方式的一次重大飞跃。
然而,机遇与挑战总是并存的。随着AI技术的普及,我们也需要警惕可能出现的问题。比如,如何保护用户的隐私安全?如何确保AI不会被滥用?如何在享受AI带来便利的同时,保持人类的独立思考能力?这些都是我们需要认真面对和解决的问题。
对于整个AI行业来说,Phi-3的出现无疑是一记响亮的警钟。它证明了,在追求更强大AI的道路上,参数规模并不是唯一的决定因素。精心设计的数据策略、创新的训练方法,以及对实际应用场景的深入思考,才是推动AI技术进步的关键。这或许会引发整个行业对AI研发方向的重新思考。
有趣的是,就在Phi-3引发热议的同时,不少网友开始呼吁OpenAI尽快推出GPT-3.5的继任者。这种反应生动地反映了AI领域竞争的激烈程度。然而,我们也应该看到,良性的竞争最终将推动整个行业向更高水平迈进,受益的终将是所有用户。
展望未来,我们有理由相信,像Phi-3这样的小型高效模型将会得到更广泛的应用。它们不仅能够在智能手机上运行,还可能被集成到各种智能家居设备、可穿戴设备,甚至是日常使用的各种电子产品中。这意味着,AI技术将以一种更加无处不在、更加自然的方式融入我们的生活。
当然,技术的发展永远不会停止。微软已经表示,他们将继续在小模型领域深耕,进一步提升多语言能力、安全性等关键指标。我们可以期待,在不久的将来,会有更加强大、更加智能的小型AI模型问世。
最后,让我们回到标题中网友的那句话:"OpenAI得把3.5淘汰了。"句话背后,折射出的是整个AI行业日新月异的发展速度。在这个快速变化的时代,唯有不断创新,才能始终立于不败之地。对于我们普通用户来说,最重要的或许是保持开放和好奇的心态,拥抱这些新技术带来的变革,同时也要理性地看待它们的局限性。
毕竟,无论AI如何发展,它始终是为了服务人类,而不是取代人类。在这场AI革命中,我们既是见证者,也是参与者。让我们携手同行,共同探索AI带来的无限可能,创造一个更加智能、更加美好的未来。











