随着全球能源需求的不断增长和环保要求的日益严格,催化剂的设计和开发成为科学与工业界的热点。催化剂在能源转换、环境修复和化工生产中起着至关重要的作用。然而,传统催化剂的开发往往依赖于反复试验的「试错法」,这一过程不仅耗时且成本高昂。因此,如何加速催化剂的开发和优化,成为了当今科研和技术领域的重大挑战。随着人工智能(AI)和机器学习(ML)技术的发展,数字化工具在催化研究中的应用逐渐显现出巨大潜力。
本次综述【Catalysis in the digital age: Unlocking the power of data with machine learning】深入探讨了机器学习如何与实验数据及理论计算相结合,用于催化剂设计和优化。作者详细分析了当前机器学习在催化研究中的应用现状、挑战以及未来发展方向。
机器学习与催化研究的结合:
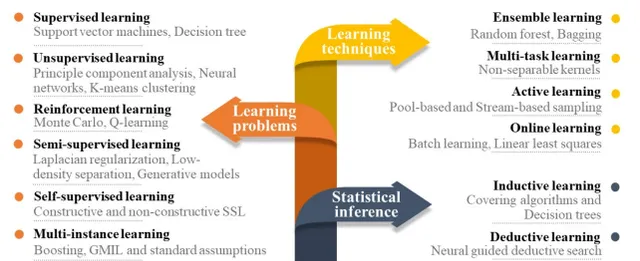
机器学习是一种能够从数据中学习并作出预测的技术,已广泛应用于图像识别、语言处理等领域。近年来,随着计算能力的提升和数据存储技术的发展,机器学习在催化研究中逐渐展现出其独特的优势。通过对实验和计算数据的处理,机器学习能够识别出催化剂性能与其组成、结构之间的关系,帮助科学家发现更具活性的催化剂。
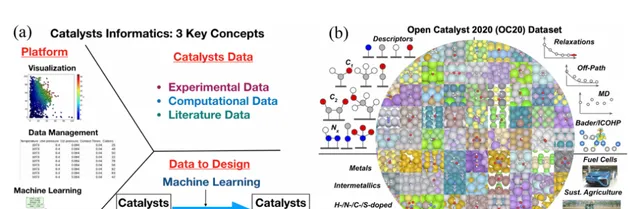
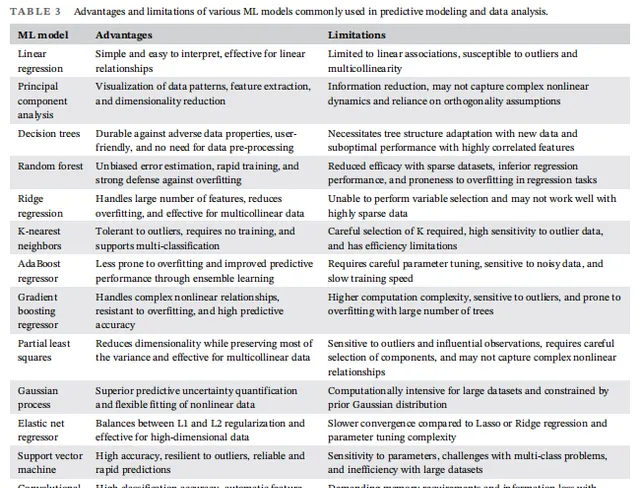
在该综述中,作者们指出了机器学习在催化研究中的几种关键应用,包括反应预测、材料特性分析和结构优化等。例如,机器学习能够通过已有的催化剂数据,快速筛选出潜在的高效催化剂,并预测其活性、稳定性和选择性。此外,机器学习还能通过大数据挖掘和分析,发现催化剂反应中的关键描述符,为催化剂设计提供理论指导。
数据驱动的催化剂开发:
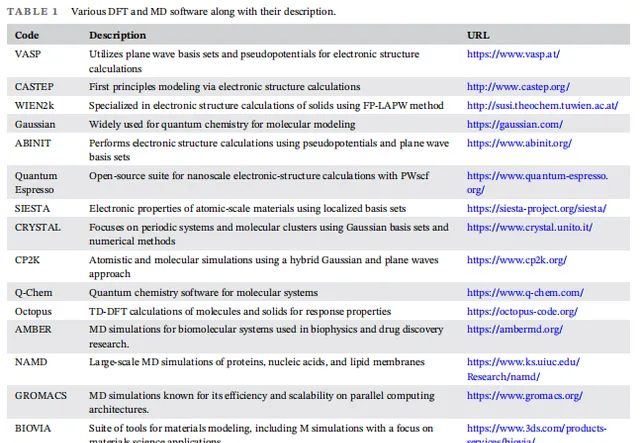
在催化剂开发过程中,数据的质量和数量是决定机器学习模型性能的关键因素。通过大规模的高通量实验、密度泛函理论(DFT)计算以及文献数据挖掘,研究人员可以构建催化剂特性数据库,利用这些数据训练机器学习模型,从而预测催化剂的性能。在本文中,作者列举了多个材料科学中的著名数据库,例如NOMAD、Materials Project等,这些数据库包含了大量催化剂的结构、热力学和电子性质,为机器学习模型的开发提供了坚实的数据基础。
挑战与机遇:
尽管机器学习在催化研究中展现出巨大的潜力,但其应用也面临诸多挑战。首先,催化剂本身的复杂性对机器学习模型的构建提出了严峻考验。由于催化剂的反应机制涉及多尺度、多维度的动态过程,如何从有限的实验和计算数据中提取出能反映催化性能的有效描述符,仍然是一个开放的研究问题。
其次,机器学习在催化研究中的应用仍处于起步阶段,数据的质量和模型的可靠性是影响研究结果的关键因素。为了提高模型的准确性,研究人员需要对数据进行清洗、预处理,并使用交叉验证等技术来评估模型的性能。此外,催化剂设计中的「黑箱」问题,即机器学习模型难以解释的预测结果,也是未来亟待解决的挑战之一。
尽管面临挑战,本文的作者们对机器学习在催化研究中的前景持乐观态度。他们认为,随着算法的不断发展、数据集的不断扩展,以及计算成本的逐步降低,机器学习将成为催化剂设计和优化中的核心工具之一。
未来展望:
本文总结了机器学习在催化研究中的应用现状,并提出了未来的发展方向。首先,作者指出,未来的催化剂设计将更加依赖于数据驱动的科学发现,尤其是在开发高效、低成本的催化剂方面。其次,机器学习将与其他计算工具(如量子力学计算、分子动力学模拟)紧密结合,形成一种多尺度、多物理场的研究框架,从而更好地描述催化反应中的复杂现象。
此外,作者还强调了可解释性机器学习的重要性。未来的研究应致力于开发更加透明的模型,以帮助研究人员理解催化剂性能与其微观结构之间的关系。这将为催化剂的设计提供更加直观和有效的指导。