这项目研究应用机器学习(ML)技术,特别是深度聚类,来自动识别和分析罗斯冰架上部署的34站宽带地震阵列(2014-2017年)观测到的地震信号。
西南极洲的冰盖和冰架正在经历快速变化,这对于预测未来海平面上升和相关社会环境影响至关重要。冰架的地震活动,如冰震,可以提供冰架崩解速率和冰架完整性变化的指示。使用深度聚类技术,通过自动编码器将频谱图编码为低维潜在表示,然后应用高斯混合模型(GMM)和深度嵌入聚类(DEC)两种聚类方法来分析潜在数据。研究识别了八类主导地震信号,并将其与环境数据(如温度、风速、潮汐和海冰浓度)进行比较。
发现了在2016年厄尔尼诺夏季,罗斯冰架前缘的地震活动水平最高。在部署期间,靠近前缘的接地区域附近的地震活动也较为频繁。某些地震信号类别与季节变化和罗斯岛潮汐驱动的地震活动有空间和时间上的关联。
研究中讨论了深度聚类在数据处理、模型设计、数据预处理和后处理方面的灵活性,以及如何通过调整自动编码器的架构和聚类算法来进一步优化聚类性能。
说明了深度聚类技术能够自动识别不同类型的地震信号,结合环境数据,有助于识别特定环境因素与地震活动类别之间的关联。这为大规模地震数据集的探索提供了一种有效工具,并可能成为现有地震数据处理和分析流程的补充。
也说明了深度聚类是一种探索大型地震数据集的有效方法,尤其是在识别主导地震类型方面。结合非地震环境数据,深度聚类可以帮助识别或关联地震源机制。随着地震数据集的不断增长,新的机器学习技术将对充分利用这些数据至关重要。
此外,本文提供了如何获取和处理罗斯冰架的地震数据,文章引用自SCI1区期刊,加入了作者观点,具体引用连接已放在文末,受制于头条限制,公式不能完美还原,如不满,请查阅英文原文。
以下是研究具体内容,「无监督深度聚类在地震数据中的应用:监测南极罗斯冰架」,原文作者:William F. Jenkins II, Peter Gerstoft, Michael J. Bianco, Peter D. Bromirski 机构:加州大学圣地亚哥分校斯克里普斯海洋研究所
摘要: 机器学习(ML)技术和计算能力的进步已经产生了处理、分类和分析大型地震数据集的最新方法。在这项研究中,我们考虑了ML在自动识别2014至2017年在南极罗斯冰架(RIS)部署的34站宽带地震阵列观测到的主导脉冲地震活动类型的应用。RIS地震数据包含了许多冰川过程产生的信号和噪声,这些对于监测冰架的完整性和动力学非常有用。深度聚类被用来高效地研究这些信号。深度聚类自动将信号分组为假设的类别,无需手动标记,允许比较它们的信号特征以及与潜在源机制的空间和时间分布。该方法使用频谱图作为输入,通过自编码器(一种深度神经网络)将它们的重要特征编码到低维潜在表示中。
为了比较,我们在潜在数据上应用了两种聚类方法:高斯混合模型(GMM)和深度嵌入聚类(DEC)。我们识别出了八类主导地震信号,并将其与环境数据(如温度、风速、潮汐和海冰浓度)进行了比较。在2016年厄尔尼诺夏季,RIS前缘的地震活动水平最高,整个部署期间,前缘附近的接地区域也出现了较高的地震活动。我们展示了某些类别的地震活动与RIS前缘的季节变化以及与罗斯岛潮汐驱动地震活动的时空关联。
关键词: 深度聚类;地震数据;罗斯冰架;机器学习;无监督学习
1. 引言
西南极洲的冰盖和冰架正在经历快速变化。在2003年至2019年间,西南极冰盖(WAIS)每年净冰量损失1690亿吨,导致海平面上升7.5毫米。温暖的海洋正在增强冰架底部的融化,这减少了接地冰盖的支撑,导致冰流入海洋的增加和海平面上升。随着西南极洲单独含有5.6米的海平面上升潜力,监测冰架的损失在预测未来海平面上升及其对海岸线和环境的社会影响方面起着关键作用。
增加的地震活动,如由断裂产生的冰震,可以提供冰山崩解速率和冰架完整性变化的指示。然而,广泛的连续记录地震观测系统的普及导致了数据量的激增,这使得使用传统信号处理方法分析变得越来越困难。与此同时,计算能力和机器学习算法的进步使得研究自然过程和现象的更高效、数据驱动的方法成为可能。为了更高效地分析大型地震数据集,我们将当代ML技术应用于现有的信号处理和数据分析技术。
地震学是一个数据密集型的领域,拥有完善的信号处理和分析方法。ML技术的最近引入导致了开发出补充工具,为地震学家提供了传统分析的新方法,如地震检测和预警、相位拾取、地面运动预测、层析成像和大地测量。在这项研究中,我们展示了聚类,一种无监督ML的形式,用于在数据集中发现相似信号的类别(Bishop, 2006; Holtzman et al., 2018; Johnson et al., 2020),它通常用作大型、未标记数据集的探索工具。
为了测试聚类相似信号组以监测冰架的适用性,我们特别关注南极的罗斯冰架(RIS),在那里从2014年11月到2017年1月部署了一个34站的被动地震阵列,以观察RIS对海洋重力波冲击的反应并研究冰架的结构动力学(Bromirski et al., 2015)。
该阵列连续记录了长周期和短周期地震信号,这些信号表现出与冰架与海洋、大气和地壳耦合相关的季节性和空间变化(Baker et al., 2019)。RIS上的信号和环境噪声包括Whillans冰流的潮汐驱动粘滑地震活动(Bindschadler, King, et al., 2003; Bindschadler, Vornberger, et al., 2003; Wiens et al., 2008);基底微地震和颤动(Barcheck et al., 2018);潮汐和热驱动的裂隙(Olinger et al., 2019);
与地下融化相关的日间地震活动(MacAyeal et al., 2019);风产生的冰共振(Chaput et al., 2018);由海洋波动、次重力波和海啸产生的弯曲和板块波(Bromirski & Stephen, 2012; Bromirski et al., 2017; Chen et al., 2018);区域和远程地震(Baker et al., 2020);以及由海洋重力波产生的冰震(Chen et al., 2019)。环境地震噪声,可以用来估计RIS结构(Diez et al., 2016),也包含了海洋重力波的频谱,其色散可以用来识别它们的源距离和起源(Bromirski et al., 2015; Hell et al., 2019)。
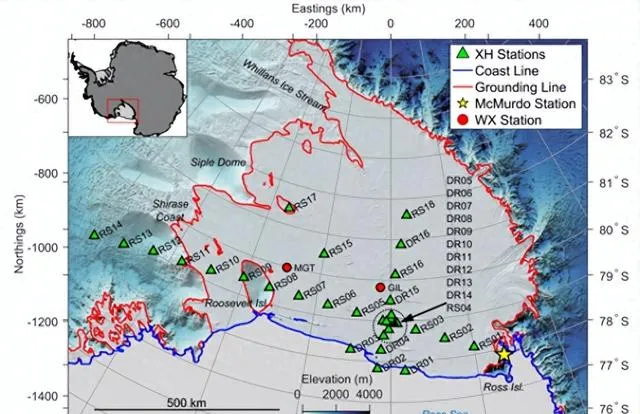
图1. 无源宽带地震阵列由34个地震站组成(罗斯冰架(RIS)对波浪诱导振动项目动态响应)。
RIS记录的地震数据多样,涵盖了具有广泛时空变异性的众多源机制。在这项研究中,我们应用了两种无监督聚类方法来识别具有相似时间和光谱特征的地震事件类别。这些信号类别的出现和分布提供了关于影响冰架演化的冰川过程的信息。
2. 背景
具有相似特征的地震信号分组(聚类)允许研究与环境强迫相关的冰川过程的空间和时间变异性。
2.1. 聚类
有许多方法可以对数据进行聚类(Aggarwal & Reddy, 2014),其中许多方法已被改编用于地震学和地球物理学(Kong et al., 2019)。基于稀疏建模的相关方法,称为字典学习,已被应用于正则化地震反问题(Bianco & Gerstoft, 2018; Bianco et al., 2019)。层次聚类已被Mousavi et al. (2016)用于自动区分浅层和深层地震,Trugman和Shearer (2017)用于更精确地定位地震。图形聚类已被Riahi和Gerstoft (2017)用于在密集地震阵列中定位源,Telesca和Chelidze (2018)用于在时间上聚类地震事件。
基于距离的聚类,如流行的k-means算法(Hartigan & Wong, 1979; MacQueen, 1967),已被Chamarczuk et al. (2020)用于基于从地震数据提取的特征聚类地震活动。Perol et al. (2018)使用k-means来定义作为其卷积神经网络(CNN)检测和定位技术的一部分的概率地震位置。Wallet和Hardisty (2019)使用高斯混合模型(GMM)聚类,该模型假设数据中存在可以表示为线性叠加的高斯分布的聚类,从而识别地震相。Seydoux et al. (2020)使用深度散射神经网络和GMM来检测和聚类地震信号和背景噪声。
并非所有的聚类方法都涉及ML。模板匹配:其中从模板波形构建匹配滤波器,用于扫描连续记录以定位相似信号(Beaucé et al., 2018; Chamberlain et al., 2018; Gibbons & Ringdal, 2006)。Yoon et al. (2015)和Bergen和Beroza (2018)提出了计算效率高的技术,其中局部敏感哈希用于将地震信号映射到哈希表中,允许通过表项识别相似信号。Hotovec-Ellis和Jeffries (2016)开发了一种方法,使用基于相关性的相似性搜索自动检测和聚类连续数据中的重复火山地震。Cole (2020)采用了Hotovec-Ellis和Jeffries (2016)的方法,对RIS阵列数据在RS09、RS10和RS11站进行聚类,以表征这些站的潮汐强迫地震活动。
2.2. 维度
随着维度的增加,聚类误差指标可能会给出较少有意义的结果。由于高维数据聚类困难(Aggarwal et al., 2001; Steinbach et al., 2004),降维一直是开发的重点(Yang et al., 2017)。通常希望将输入数据转换为由较少、更显著的特征描述的低维表示。一种流行的方法是使用主成分分析(PCA),它通过一系列非线性变换将高维数据投影到低维空间(Goodfellow et al., 2016),并被Reddy et al. (2012)用于压缩地震数据以最大化特征方差。
在这项研究中,我们采用自编码器来降低数据的维度。自编码器是一种模型,其输出旨在通过一系列非线性变换(使用深度神经网络(DNN))来复制其输入(Hinton, 2006; Murphy, 2012; Yang et al., 2017)。这些非线性变换提供了更大的降维能力,并且能够比PCA更好地建模具有低维表示的数据。自编码器首先将输入数据(例如,频谱图)编码为潜在特征向量。接下来,自编码器解码潜在特征并重构原始图像。由于自编码器提供了数据的非线性变换,因此必须使用梯度下降进行训练。在这种迭代训练中,输入和输出之间的误差被最小化。通过这样做,网络权重学习了数据的显著特征。通过在潜在特征空间中降低输入数据的维度,可以在数据的潜在特征空间中应用聚类算法。
2.3. 深度嵌入聚类
在深度聚类中,使用DNN(如自编码器)来降低数据的维度。Xie et al. (2016)开发了一种新的深度聚类方法,称为深度嵌入聚类(DEC),它由两个过程组成:(a)训练自编码器来表示数据的显著特征;(b)联合优化编码层和聚类层。Yang et al. (2017)通过联合优化整个自编码器(不仅仅是编码器层)来扩展DEC方法。DEC的其他变体也被提出:Xie et al. (2016)在他们最初的实现中使用了堆叠去噪自编码器(Vincent et al., 2010),但Min et al. (2018)采用了由CNN层和其他架构组成的自编码器。最近,Chazan et al. (2019)开发了一种方法,其中联合聚类是与表示每个聚类的混合自编码器一起执行的,而Boubekki et al. (2021)展示了一种与自编码器嵌入联合优化的聚类算法的性能提升。
Mousavi et al. (2019)使用DEC来预测地震检测是局部的还是远程的,SnoVer et al. (2021)展示了DEC聚类人为产生的地震噪声的能力。在与我们类似的信号处理和聚类工作流程中,Ozanich et al. (2021)比较了DEC和GMM在珊瑚礁上收集的声学数据的频谱图上的性能,但在他们的情况下发现GMM的性能优于DEC。
在这项研究中,我们在RIS地震数据的潜在特征空间中实现了GMM聚类,并将其性能与DEC进行了比较。使用2014年12月至2016年11月的RIS地震数据,我们识别了几种不同类型的信号,并进一步展示了深度聚类作为大型真实世界地震数据集探索工具的实用性,通过将聚类结果与观察到的环境因素相关联。
3. 罗斯冰架地震阵列和数据
RIS地震阵列的每个站点都由三个分量的Nanometrics Trillium 120 PHQ地震计组成,这些地震计被放置在冰面下1米处,在南半球夏季由太阳能板供电,在南半球冬季由锂离子电池供电。阵列由两个子阵列组成。较大的子阵列由18个站点组成,这些站点大约相距80公里(前缀RS),主要沿着RIS前缘平行排列。RS站点以100 Hz的采样率采样短周期正交分量地面速度,除了两个站点以200 Hz采样。较小的子阵列由16个站点组成(前缀DR),沿国际日期线大致垂直于冰架前缘排列,以200 Hz的采样率采样地面速度。在这项研究中,我们主要关注检测和分类冰震和局部/区域地震,使用频率在3至20 Hz之间的垂直分量观测。这个频带被选中是为了保留脉冲信号,消除低频处普遍存在的高能噪声,并排除风在20 Hz以上频率产生的共振。
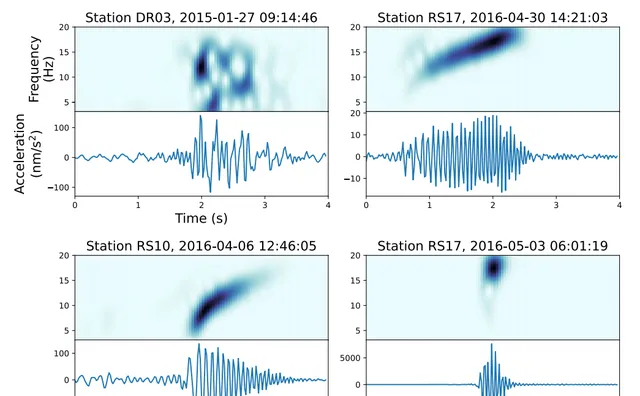
图2. 显示了检测到的典型信号类型
4. 深度聚类实现
深度聚类模型的目标是首先将输入数据(在这种情况下是地震信号的频谱图)编码到一个包含潜在(低维)特征的层中,称为嵌入层,然后在该潜在特征空间中应用聚类算法。在接下来的实现中,输入频谱图的8700个特征被一个卷积自编码器减少到只有9个嵌入特征。然后我们描述了在聚类分析中使用的GMM和DEC聚类算法。
4.1. 使用卷积自编码器进行降维
自编码器提供了一种通过一系列非线性变换使用低维表示进行数据近似的方法。自编码器模型由三个部分组成:编码器、瓶颈和解码器(Murphy, 2012)。首先,编码器将输入数据从数据空间E_X映射到潜在特征空间E_Z,这个空间包含在模型的瓶颈部分。接下来,解码器试图从E_Z重构E_X。这个过程是迭代进行的,目标是最小化E_X和解码器输出E_X'之间的误差。在最小化误差的过程中,自编码器学习了E_X的显著特征,并准确地将它们编码到E_Z中,从而降低了聚类任务的维度。
考虑一个由M个特征的光谱图组成的数据集E_X,其中每个光谱图E_x是数据集N个光谱图中的第n个。在编码阶段,E_X到E_Z的映射由以下公式描述:
E_f(X) → Z = θ
其中θ是通过网络训练学习的参数。解码阶段是编码器的镜像操作,试图将潜在特征空间E_Z映射回重构E_X':
E_g(Z) → X' = θ'
自编码器的整体映射可以描述为:
E_F(X) → Z → X' = f(g(θ), θ')
其中F_g(θ) = θ ∘ θ'。输入频谱图E_x映射到它们对应的潜在特征向量Z,以及它们的重构X',由以下公式描述:
D(Z) = f(θ) ∈ Z, X' = F(θ) ∈ X
由于自编码器由卷积和转置卷积层组成,E_Fθ是一个非线性映射,必须适当参数化。这是通过迭代学习参数θ来实现的,以便最小化输入和重构数据之间的误差。输入频谱图E_x和其重构E_x'之间的均方误差(MSE)定义为:
λ(X, X') = 1/M ∑_m (X_m - X_m')^2
MSE在数据集N的样本上平均,以获得自编码器损失函数:
L_AE(θ, θ') = 1/N ∑_n λ(X_n, X_n')
在数据集上一次性执行此计算在计算上昂贵,内存密集,且可能导致收敛不良。相反,损失是在数据空间的迷你批次子集上计算的。对于每个迷你批次损失,使用随机梯度下降(Goodfellow et al., 2016)来更新权重。当所有迷你批次都被处理后,下一个训练周期开始,过程重复。在每个周期后,使用与训练数据分开的子集来验证模型的性能,而不更新权重,从而产生验证MSE。训练在达到指定的最大周期数或验证MSE在10个周期内未能降至其最小值后提前停止。早期停止标准防止自编码器过度拟合训练数据。
自编码器架构的设计选择可以由数据集的先验知识和其特征以及可用的计算资源等实际考虑因素来指导。我们的DNN架构在表1中详细说明,旨在在计算上高效,易于构建,并且足够强大以从嘈杂的地震数据集中学习显著特征。在这个DNN架构下,θ包含218,250个可训练参数。
4.2. 聚类方法
在我们的深度聚类框架中,聚类是在潜在特征空间E_Z中进行的,以在数据中找到K个不同的信号类别。我们假设数据形成聚类,这些聚类在E_Z空间中是可分离的,并且这些聚类围绕唯一的位置μ_k聚集,即其他相似信号可能被发现的质心。我们使用欧几里得距离来衡量质心和潜在特征向量之间的相似性:
d_k,n = ||z_n - μ_k||^2
其中d_k,n是特征索引为n和k的向量之间的相似性度量。
4.2.1. 高斯混合模型(续)
线性叠加的高斯分布的混合物,每个高斯模型都有自己的质心μ_k和协方差Σ_k。我们遵循Bishop (2006, p. 430)和Murphy (2012, p. 339)的方法。混合模型的整体分布在潜在空间E_Z中由它们的分布的凸组合给出:
p(z) = ∑_k π_k N(z | μ_k, Σ_k)
其中,N(z | μ_k, Σ_k)表示以μ_k为均值,Σ_k为协方差矩阵的高斯分布。为了估计每个高斯分布的参数,我们使用期望最大化(EM)算法来最大化关于参数μ_k, Σ_k和π_k的高斯混合模型的似然函数。
对于每个样本z_n,引入一个二元随机变量ξ_k ∈ {0,1}^K,其中只有一个元素等于1,其余为0。ξ_k的边缘分布为:
p(ξ_k) = ∏_(j ≠ k) π_j
混合系数π_k满足0 ≤ π_k ≤ 1且∑_k π_k = 1,以确保为有效概率。由于ξ_k是一个1-of-K(分类)表示,这个分布可以写成:
p(ξ | z) = ∏_k π_k δ(ξ_k, argmax_k p(z | ξ_k))
其中,δ是狄拉克δ函数。然后,我们重写方程4,用因子联合分布表示:
p(ξ, z) = p(ξ | z) p(z)
对于每个样本z_n,我们有:
p(ξ | z) = p(ξ, z) / p(z)
其中,p(z)是边缘概率,可以表示为:
p(z) = ∑_k p(ξ_k) p(z | ξ_k)
使用贝叶斯定理和方程4和8,我们得到给定z_n的ξ_k的条件概率:
p(ξ_k | z_n) = p(ξ_k, z_n) / p(z_n)
这可以进一步重写为:
p(ξ_k | z_n) = p(z_n | ξ_k) p(ξ_k) / p(z_n)
其中,p(ξ_k)是先验概率,p(z_n | ξ_k)是后验概率,给定观察到z_n。
方程4现在被重写为:
p(z_n | ξ_k) = p(z_n | μ_k, Σ_k) p(ξ_k) / p(z_n)
使用贝叶斯定理和方程4和8,我们得到给定z_n的ξ_k的条件概率:
p(ξ_k | z_n) = p(ξ_k, z_n) / p(z_n)
这可以进一步重写为:
p(ξ_k | z_n) = p(z_n | ξ_k) p(ξ_k) / p(z_n)
其中,p(ξ_k)是先验概率,p(z_n | ξ_k)是后验概率,给定观察到z_n。
对于每个潜在特征向量z_n,我们将其分配给一个高斯分布,通过argmax[γ_k(ξ_k)]来确定:
γ_k(ξ_k) = p(ξ_k | z_n) / p(ξ_k)
在实践中,每个潜在特征向量z_n被分配给一个高斯分布,通过argmax[γ_k(ξ_k)]来确定。
使用上标t表示迭代索引,GMM的EM算法如下:
1. 初始化参数μ_k^(1), Σ_k^(1), 和π_k^(1)。
2. 期望步骤。这一步通过评估责任(γ_k(ξ_k))来编码样本分配到每个高斯分布的概率,使用μ_k^(t-1), Σ_k^(t-1), 和π_k^(t-1)(方程9)。
3. 最大化步骤。使用责任(γ_k(ξ_k)),这一步更新潜在空间E_Z中每个分布的质心位置(μ_k^(t)),形状(Σ_k^(t)),和归一化(π_k^(t)):
μ_k^(t) = ∑_n γ_k(ξ_n) z_n / ∑_n γ_k(ξ_n)
Σ_k^(t) = ∑_n γ_k(ξ_n) (z_n - μ_k^(t))^T (z_n - μ_k^(t)) / ∑_n γ_k(ξ_n)
π_k^(t) = ∑_n γ_k(ξ_n) / N
4. 收敛检查。使用方程5评估E_Z的对数似然,并检查参数μ_k^(t), Σ_k^(t), 和π_k^(t)是否收敛。如果对数似然或参数发生收敛,EM算法达到局部最大值并终止;否则,算法返回步骤2。
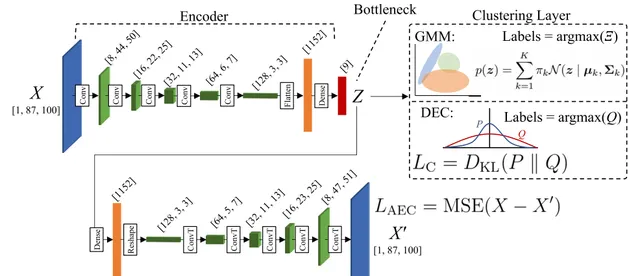
图3.深度聚类框架使用卷积自动编码器和解码
为了加速EM收敛,使用k-means聚类来初始化GMM聚类算法(Bishop, 2006, p. 438)。EM在1000次迭代后停止,或者当方程5的对数似然变化小于0.001时停止。为了避免收敛到局部最大值,初始化运行100次,并保留具有最佳对数似然的初始化。
4.2.2. 深度嵌入聚类
在DEC中,聚类与自编码器的继续训练相结合,聚类层连接到瓶颈,提供额外的损失函数,该函数通过自编码器层进行反向传播。
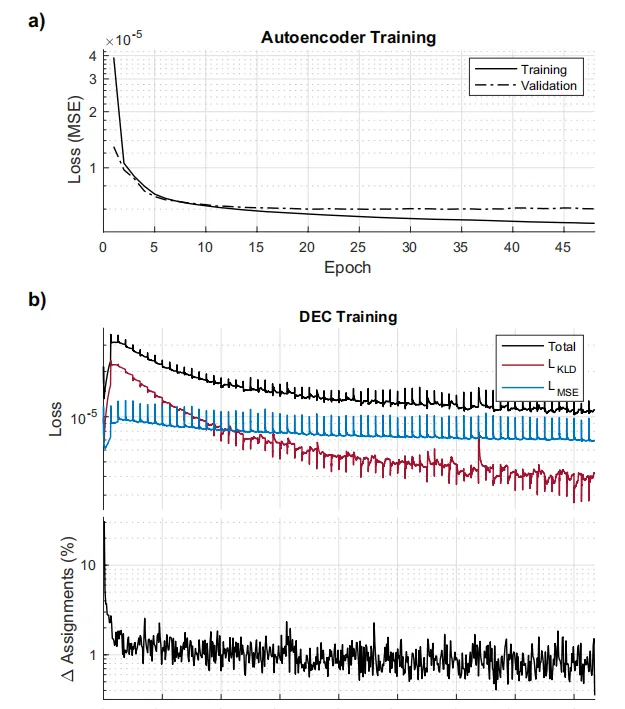
图4.(a) 自动编码器培训期间的培训和验证损失(b)深度嵌入聚类(DEC)的损失曲线
DEC模型DNN参数使用训练好的自编码器的参数进行初始化,聚类层参数使用GMM聚类的质心进行初始化。DEC旨在通过使用嵌入频谱图和聚类质心之间的欧几里得距离(方程3)作为额外的损失函数来改进GMM聚类。由于输入数据是未标记的,需要一种自监督方法。我们实现了Xie et al. (2016)开发的方法,他们从t-分布随机邻域嵌入(t-SNE)算法(van der Maaten & Hinton, 2008)中汲取灵感,提出测量潜在特征向量z和辅助目标分布之间的差异。简化的学生t分布用于测量嵌入频谱图z_n和聚类质心μ_k之间的相似性:
q_k(z_n) = (1 + ||z_n - μ_k||^2)^(-1)
这导致了一组软类别分配,即嵌入频谱图z_n被分配到类别k的概率。潜在特征向量z_n被分配到一个类别k,通过arg max[q_k(z_n)]确定。然后,使用软类别分配来计算辅助目标分布p_k,其形式旨在提高聚类性能,强调具有高置信度分配的嵌入,并使每个聚类质心对损失函数的贡献标准化,以便大聚类最小程度地扭曲E_Z:
p_k(z_n) = (q_k(z_n))^2 / ∑_k' (q_k'(z_n))^2
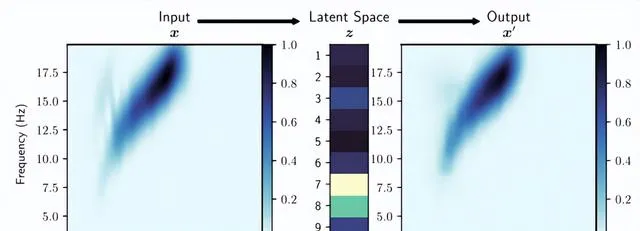
图5.经过训练的自动编码器获取输入谱图EX并将其编码为九维潜在特征向量EZ
使用以上方程,我们得到聚类层的损失函数:
L_C = ∑_k ∑_n C_k(z_n) log(p_k(z_n) / Q_k(z_n))
其中,C_k(z_n)是Kullback-Leibler散度,用于测量分布p_k(z_n)和Q_k(z_n)之间的差异。在DEC中,将方程2和13的损失函数组合成总损失函数:
L_total = L_AE + λ L_C
其中,λ是一个超参数,用于平衡两个损失的贡献,因为它们的量级不同。λ必须进行调整:如果λ太大,聚类损失会导致模型不稳定并导致潜在空间的扭曲,此时潜在空间将不再代表数据的显著特征。如果λ太小,对聚类性能的影响将很小。我们发现λ = 10^(-4)对于模型训练和聚类性能是最优的。
在DEC模型训练期间,同时发生两个组成过程。首先,通过DEC模型参数(包括自编码器和聚类质心)反向传播整个损失函数。其次,为了考虑训练过程中聚类质心的变化,更新分布q_k(z_n)和p_k(z_n)。更新间隔是一个超参数,必须进行调整。通过超参数调整,发现每10个训练周期更新一次是聚类性能最优的,最小化DEC损失,并在合理的时间内完成训练。训练在每个更新间隔后样本更改分配的次数少于总训练样本数的0.4%时停止。
与自编码器和DEC模型训练相同的迷你批次大小和初始学习率(表2)。图4b显示了DEC训练过程中损失随时间的下降以及每个迷你批次训练迭代中类别重新分配的百分比变化。尽管损失曲线的整体趋势呈指数衰减,但在每个更新间隔时,当q_k(z_n)和p_k(z_n)被重新计算时,会出现周期性峰值,并且由于损失是在每个迷你批次而不是每个周期后记录的,因此这些峰值是可见的。
4.3. 选择最佳聚类数量
在无监督机器学习中,确定最佳聚类数量K是一个主要挑战。在本研究中,我们将K视为一个超参数,通过迭代深度聚类工作流程,对一系列K值进行评估,以选择最佳值。结果通过定量和定性评估进行评估。
定量评估是通过检查每个类别的累积分布函数和概率密度函数作为到每个类别质心的距离的函数(方程3)来执行的。此外,还参考了选择最佳聚类数量的传统统计方法,如间隙统计量(Tibshirani et al., 2001)和轮廓系数(Rousseeuw, 1987)。
定性方法是通过视觉检查潜在特征向量z_n与各自类别质心μ_k的相似性,以及检查分配给每个类别的频谱图和地震图是否表现出相似性。一般来说,如果两个或多个相似的类别形成,可能表明初始化了太多类别,这些类别中的数据可以在后处理中合并为一个类别。类别内频谱图之间的变异性过大可能表明需要一个或多个额外的类别。我们发现,对于RIS数据集,K = 8是最佳类别数量。
5. 结果
以下分析重点在于GMM和DEC性能如何影响潜在空间E_Z,以及这些方法是否在数据空间E_X中产生有意义的结果。由于数据集中的样本未标记,没有「真实」结果可以与结果进行比较,因此检查了频谱图和潜在特征向量之间的类内相似性。我们得出结论,GMM和DEC在聚类性能上没有明显优势。因此,我们建议在深度聚类RIS地震数据时实施GMM。GMM的统计和数学基础被充分理解,而在没有显著性能提升的情况下,DEC的实现和解释复杂性难以证明。此外,在实践中,GMM聚类在图形处理单元上对整个数据集进行聚类大约需要1分钟,而一次DEC超参数调整运行可能需要几个小时。
在接下来的分析中,我们呈现了包括训练和验证数据子集在内的531,407个频谱图的整个数据集的结果。我们通过使用不到10%的数据集进行训练和验证,并随机无替换地抽取训练样本,以实现训练子集代表整个数据集,来减轻DEC模型在训练数据上过拟合的风险(Murphy, 2012, p. 23)。
5.1. 聚类性能
通过比较质心与其分配的潜在数据样本来定性检查深度聚类性能。GMM的结果如图6所示。每个类别k由图6中的列表示,每个质心μ_k及其重建(g(θ)μ_k)沿顶行绘制。虽然质心不是数据集的成员,但由于质心代表了其类别的显著特征,其重建应类似于分配给其类别的频谱图。随后的行显示了分配给各自类别的数据样本的潜在特征向量z_n、频谱图x_n和相关的地震图。为了检查随着距离质心的增加(即随着d_n,k的增加),类内相似性如何保持,显示了{1,1000,5000,10000,15000,20000,25000}_n的样本。
在质心附近,潜在特征向量z_n通常具有与其类别质心μ_k相似的值,表明GMM已成功将相似的潜在数据样本分组到类别中,并且质心代表了其类别中的数据。每个类别中的频谱图也彼此相似,类似于质心重建(g(θ)μ_k),这证实了嵌入在质心中的潜在特征代表了类别中的频谱图。最后,潜在空间和时频域中的相似性扩展到时域,其中每个类别中的地震图彼此相似。随着距离的增加(即随着d_n,k的增加),开始出现不相似的情况,因为样本与相邻类别重叠。
除了检查聚类的效力外,结果直观地指示了是否选择了合适数量的类别。例如,类别4和8在时间和频率上表现出相似的特征,主要在峰值振幅上有所不同。如果这种区分没有用处,或者相似性是多余的,类别可以在后处理中合并。如果选择的类别太少,类别可能包含差异很大的信号,表明需要增加类别数量。
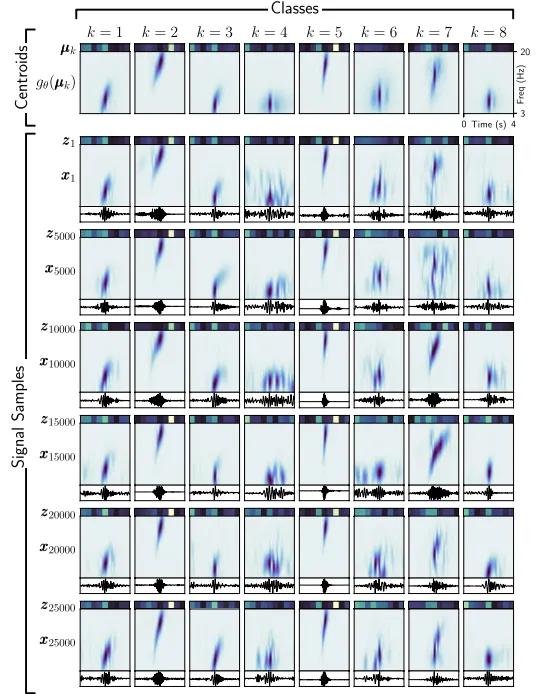
图6.高斯混合模型(GMM)的聚类结果
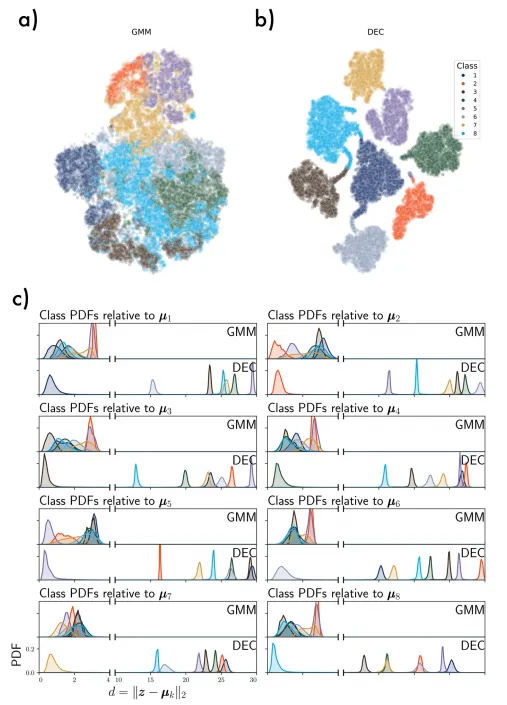
图7. (a)t分布随机潜在数据空间可视化 高斯混合模型聚类。(b) 深度t-SNE图 嵌入式聚类(c) DEC潜在特征作用
5.2. 深度聚类方法考虑
本研究中深度聚类实现的一个关键优势是使用自编码器来降低输入数据的维度,以获得更有效的聚类性能。通过降低数据空间的复杂性,聚类问题也相应降低,距离度量变得相关。自编码器能够快速学习数据的显著特征并将其嵌入到潜在空间中,使该技术适用于新的数据集。虽然本研究中的自编码器设计选择足够健壮,但自编码器设计提供了进一步实验和改进的机会。设计变量包括层的数量和类型、潜在特征空间的维度、激活函数类型、最大池化和dropout层的结合以及过滤器的大小、深度和步长。
选择聚类层的适当算法在很大程度上取决于数据集的类型和属性。尽管在本研究中我们使用了GMM和DEC,如第2节所述,还有许多聚类算法可能适用于深度聚类工作流程。无论选择哪种聚类算法,都必须仔细考虑聚类在潜在空间中的映射是否在数据空间中产生有意义的结果。
深度聚类的灵活性不仅体现在模型设计上,还体现在数据预处理和后处理上。模型设计主要关注如何学习数据的显著特征,而数据预处理则关注提供给模型的信息。这取决于信号处理参数的选择,特别是信号持续时间、滤波器截止频率和地震事件检测算法。此外,用于表征地震波形的各种数据变换通常可以用作深度聚类工作流程的输入(Mousavi et al., 2016)。在我们的情况下,我们使用了频谱图,但其他变换,如连续小波变换尺度图,也可以轻松用作输入。在后处理中,可以合并冗余或相似的结果。
6. 讨论:冰川学意义
从识别的八类信号的空间和时间分布中,我们获得了关于RIS对各种气候强迫(包括海洋和大气变异性)响应的信息。重要的是,两年的连续地震监测允许识别季节性和年际变化模式,特别是通过与2015年水平的比较,检查2016年强厄尔尼诺对RIS地震活动的影响。
RIS阵列数据集包含531,407个地震检测。数据集统计和类别特征的摘要(表4)显示了每个类别的总检测次数,以及在南半球夏季(1月、2月和3月)与冬季(6月、7月和8月)发生的检测百分比。类别2、4、5、6和8在夏季与冬季的检测次数差异明显(超过10%),而类别1、3和7的差异较小(在5%和10%之间)。每个季节的年际比较显示,类别5、6和7在2016年南半球夏季的活动增加,其中类别5和7的变化最大。
6.1. RIS前缘的季节性地震活动
在新冰山附近的RIS前缘约2公里处,DR02站表现出与罗斯海海冰覆盖和温度变化相关的季节性地震活动模式。在南半球冬季,海冰覆盖(图11a)接近100%,抑制了海洋波动。在南半球夏季,海冰浓度降至约25%,允许海洋重力波直接冲击冰架前缘并导致冰山崩解。此外,较暖的空气温度(图11b)可能通过促进崩解来增加冰震活动(Chen et al., 2019)。
观察到所有类别的地震活动增加,除了类别2和5。类别4、6和8在2016年南半球夏季特别活跃,当时强烈的厄尔尼诺条件导致整个西南极洲异常持续高温(Nicolas et al., 2017),海洋-冰架相互作用增强。在DR01和DR03站也观察到了类似DR02的地震活动模式,这些站也位于RIS前缘附近,如图10a所示。在2016年1月10日至21日之间,RIS上观察到了广泛的表面融化(Chaput et al., 2018; Nicolas et al., 2017),这影响了雪层特性并通过冻融循环影响地震活动(MacAyeal et al., 2019)。
尽管类别6在夏季活动增加,但它在冬季月份也保持活动,这表明重力波活动不是主导强迫。类别1信号的持续存在,通常由脉冲序列组成,表明它们可能是由冰架本身运动引起的冰震(Klein et al., 2020),因为DR02附近的冰流速度是RIS上观测到的最高速度之一。类别5(图11h)在一年中最冷的时期(4月至9月)更活跃,这表明这些信号可能与极低温度或强风事件有关。在冰架前缘约140公里处的一个裂缝附近发生了冷天气增强的地震活动(Olinger et al., 2019)。或者,从表4来看,这些类别的振幅低于在南半球夏季最活跃的类别,这表明这些检测可能被其他类别的更高振幅信号掩盖。在所有类别中,不对应环境强迫 的高地震活动离散事件也会出现。这些事件可能表明发生了冰裂(冰震)或与裂缝扩展相关的事件。
6.2. 罗斯岛的日间地震活动
位于罗斯岛东侧的RS09站在整个阵列中检测到的事件最多,占整个数据集的22%。在图12中,将潜在的环境地震源与每个类别的地震活动进行了比较。温度和风速(图12a和12b)是在RS09西南约122公里的Margaret自动气象站记录的。潮汐(图12c)是根据CATS2008模型(Padman et al., 2002)在RS10站实现的,该站位于浮冰上,近似于罗斯岛和白濑海岸之间的盆地中的潮汐信号。RS09的类别1(图12d)在全年都占主导地位,占检测的52.8%。类别3、4、6和8(图12f、12g、12i和12k)也在全年活跃。类别5和7(图12h和12j)相对较少,地震活动似乎仅限于可能是与大裂缝或冰裂事件相关的离散信号。尽管在2016年冬季类别5的地震活动增加,但在RS09没有记录到类别2(图12e)的信号。
RS09特别有趣的是与日潮汐相关的地震活动证据(图12)。在年际时间尺度上,类别4和8表现出与春潮相关的周期性地震活动调制。在2016年3月15日至4月15日之间的两周时间尺度上,类别1和3与日潮汐相关。甚至一些相对不活跃的类别(4、6和8)也显示出日间地震活动的迹象。这些结果与之前的研究一致,该研究发现RS09超过95%的检测来自全年发生的由潮汐引起的冰震群(Cole, 2020)。每周时间尺度还揭示了类别5和7冬季地震活动的突然开始和结束,这表明与冰架事件(如裂缝扩展或主要冰裂)有关。这种开始与2016年初在RIS阵列中可见的地震活动大幅增加一致(图10)。
位于接地区域的其他站点也显示出类似的地震活动模式,尽管程度较RS09轻。位于RS09东侧的Shirase海岸的RS11站显示出与RS09相似的地震活动模式。这些相似性表明,接地区域的冰架地震活动与相似的冰架过程有关。位于罗斯岛西侧的RS08站和位于Steershead冰上升的RS17站也显示出日间地震活动,表明接地区域存在动态的日间过程。这些地震活动模式表明,冰架与固体地球在接地区域的相互作用受到潮汐的调节。在四个接地区域站点中,类别1、4和8是最常见的信号,其中类别8信号在这些站点中发生最频繁。类别8信号的平均峰值频率为6.3 Hz,平均振幅为210 nm/s²,是整个阵列中检测到的最强信号之一。
7. 结论
使用GMM对RIS地震阵列数据集进行深度聚类,识别出八类脉冲信号,其中至少两类与接地区域附近的潮汐变异有关。与2015年相比,2016年厄尔尼诺南半球夏季,RIS前缘附近的站点显示出增加的冰震活动。在2016年南半球冬季过渡期间,整个阵列也观察到了地震活动的突然增加。最高地震活动发生在接地区域,特别是在罗斯岛东侧。深度聚类是探索大型地震数据集的有效方法,特别是在识别主导地震类型方面。当与非地震环境数据相结合时,深度聚类的结果可以帮助识别或关联地震源机制,如与RIS环境数据所示。此外,深度聚类可以轻松定制以调查相同或新数据集的不同方面。结合其在聚类地震检测方面的有效性,这种灵活性表明深度聚类可以纳入现有的地震工作流程,以加快探索性数据分析。
随着地震数据集不断增长,新的机器学习技术将对充分利用这些数据至关重要。深度聚类有潜力成为探索这些大型数据集的重要工具,并补充其他基于ML的工具以及传统的信号处理方法。将这些工具纳入将使地球物理研究对快速变化的地球需求做出更全面和及时的响应。
数据可用性声明
地震数据通过IRIS Web Services(https://service.iris.edu/irisws/)下载。地震数据使用ObsPy软件(Beyreuther et al., 2010)进行处理。图形在MATLAB(https://www.mathworks.com)和Matplotlib(https://matplotlib.org)中生成。DEC模型使用PyTorch(https://pytorch.org)生成。南极洲高程数据、接地线和海岸线来自Bedmachine(Morlighem et al., 2017),并使用Antarctic Mapping Tools for MATLAB(Greene et al., 2017)绘制。表面温度数据来自AMRC, SSEC, University of Wisconsin–Madison(https://amrc.ssec.wisc.edu)。潮汐数据由CATS2008模型(Padman et al., 2002)生成。罗斯海冰覆盖数据来自NASA NSIDC(Cavalieri et al., 1996,每年更新)。工作流程的代码可在https://github.com/NeptuneProjects/RISWorkflow获取。
引用:
GB:Jenkins W F, Gerstoft P, Bianco M J, et al. Unsupervised deep clustering of seismic data: Monitoring the Ross Ice Shelf, Antarctica[J]. Journal of Geophysical Research: Solid Earth, 2021, 126(9): e2021JB021716.
APA:Jenkins, W. F., Gerstoft, P., Bianco, M. J., & Bromirski, P. D. (2021). Unsupervised deep clustering of seismic data: Monitoring the Ross Ice Shelf, Antarctica. Journal of Geophysical Research: Solid Earth , 126 (9), e2021JB021716.











