本文内容来源于【测绘学报】2024年第
4
期(
审图号GS京(2024)0714
号)
结合SAM大模型和数学形态学的历史地图水系信息提取方法
赵飞 ,1,2 , 李兆正 3 , 甘泉 4 , 高祖瑜 3 , 王湛初 3 , 杜清运 5 , 王振声 6 , 沈洋 4 , 潘威 ,7
1. 云南大学地球科学学院,云南 昆明 650500
2. 云南省中老孟缅自然资源遥感监测国际联合实验室,云南 昆明 650051
3. 云南大学国际河流与生态安全研究院,云南 昆明 650500
4. 自然资源部第三大地测量队,四川 成都 610100
5. 武汉大学资源与环境科学学院,湖北 武汉 430079
6. 鹏城实验室战略与交叉前沿研究部,广东 深圳 518055
7. 云南大学历史与档案学院,云南 昆明 650091
第一作者简介: 赵飞(1986—),男,博士,副教授,研究方向为地图学理论与应用、时空大数据分析。E-mail:[email protected]
通信作者: 潘威 E-mail:[email protected];[email protected]
基金项目: 国家社科基金重大项目(22&ZD225);国家自然科学基金(41961064);四川省测绘地理信息局2023年新型基础测绘技术研究补助计划(2023KJ001);鹏城实验室重大项目(PCL2023AS6-1)

摘要: 历史地图记载着丰富的历史地理信息,能够帮助了解历史规律,为当代发展提供借鉴。不同于现代地图、遥感影像等数据,历史地图保存时间久,存在留存数量少、图像精度低等问题,地图符号也与现代有所差异,因此信息难以被高效提取。针对该问题,本文以历史地图【宁夏省境黄河沿岸沟渠水道地形图】为试验数据,提出一种智能化历史地图水系信息提取方法。首先,结合符号句法,运用聚类与数学形态学方法构建数据集;然后,改进通用大模型(SAM)结构并进行迁移学习优化权重;最后,借助改进SAM自动提取历史地图水系信息。将试验结果与其他模型作对比,显示本文方法提取结果边界清晰,轮廓完整,准确率、精度等指标均为最高。同时,将提取结果与该区域水系现状作对比,发现历史上的河流沟渠如今大多改道、偏移或消失,湖泊面积大大减小。本文方法基于SAM通用大模型进行改进,验证了大模型在地图领域的可用性,为地图信息提取提供了思路。
关键词:
本文引用格式
赵飞, 李兆正, 甘泉, 高祖瑜, 王湛初, 杜清运, 王振声, 沈洋, 潘威. 结合SAM大模型和数学形态学的历史地图水系信息提取方法[J] . 测绘学报, 2024, 53(4): 761-772 doi:10.11947/j.AGCS.2024.20230308
ZHAO Fei.
全文阅读
http://xb.chinasmp.com/article/2024/1001-1595/1001-1595-2024-04-0761.shtml
历史地图借助符号实现信息承载和空间显示的功能,记载的历史地理信息能够帮助学者更好地了解地理要素时空演变,从古至今都是人们认知生存环境的重要工具[1-3] 。历史地图不同于普通地图,其信息提取主要面临以下困难:①历史地图本身留存数量少,属于小样本数据;②图像精度低,颜色失真;③历史地图与现代地图在符号句法方面存在差异[4] 。上述3点使得普通地图的信息提取方法在历史地图上效果欠佳,需要在考虑历史地图特点的基础上进行优化。
地图信息提取方法可分为传统方法和深度学习方法。传统方法包括特征聚类[5-14] 和基于灰度值的元素提取[15-19] 。在使用聚类方法的研究中,文献[6]通过分析图像的彩色空间,确定特征数目并通过聚类进行地图要素提取。文献[10]将图像的空间与颜色信息组合成特征向量,输入聚类算法中进行颜色分割与要素提取。文献[13]基于分层减法聚类提出了一种快速模糊聚类方法,在聚类数目很多的情况下能够明显提高聚类速度。在基于灰度值的提取研究中,文献[15]通过分析地图符号在灰度图像中的灰度值表面模型,提出基于灰度变换的线段跟踪方法提取地图要素。文献[19]基于灰度值提出能量密度的概念,依靠线状与面状要素的能量密度差异区分线状与面状符号,再借助Shear变换进行提取。传统方法精度尚可,但操作烦琐,参数设置复杂,只适用于少量地图信息提取。深度学习方法一般应用卷积神经网络(convolutional neural network,CNN)对地图进行识别。CNN具有多层非线性映射的深层结构,可以实现复杂的函数逼近,在图像特征提取领域十分有效,经过简单训练便可进行要素提取和地图识别[20-21] 。文献[22]将CNN与特征金字塔网络结合进行地图要素多尺度检测。文献[23]在CNN基础上加入卷积注意力模块,进行地图注记识别和文字要素提取。文献[24]手动标注图例数据集,借助小样本学习模型Keras-Oneshot进行地图图例识别。文献[25]利用地物图片构建小样本数据集,使用VGG16在ImageNet数据集上的预训练模型进行迁移学习,实现地图要素匹配。应用于地图信息提取的深度学习方法普遍面临地图数据集搜集困难、自主构建数据集成本过高的问题,大多使用与地图符号相似的其他数据集进行训练,这导致模型泛用性差,难以应用到其他地图任务中。
近年来,大模型成为深度学习的热点[26] 。相较于普通深度学习模型,通用大模型参数量更多,能够处理更为复杂的图像,虽然目前还未应用于地图领域,不过凭借出色的性能和泛用性,在与地图相似的遥感领域已有所建树[27] 。其中参数量达到千万的JointSAREO模型[28] 和参数量上亿的Scale-MAE模型[29] 使得遥感视觉任务的精度越来越高,不过相对应的所需软硬件条件也越来越严苛。为降低大模型的使用门槛,Meta公司建立了Segment Anything项目[30] 。使用超大规模数据集训练的通用大模型SAM(segment anything model)不仅可以处理多种类型的图片,还能够借助提示在小样本情况下准确地进行图像分割,目前在医学与遥感图像上均取得很好的效果[31] 。
综上所述,为了建立一种针对历史地图的信息提取方法,同时避免样本的高制作成本并且提高泛用性,本文提出将传统地图信息提取方法与深度学习大模型相结合的思路。首先,改良传统算法构建小样本数据集;然后,引入通用大模型SAM,根据数据集特点改进模型结构并进行迁移学习;最后,利用改进的SAM模型实现历史地图水系信息的智能化提取。相比单一方法,本文思路降低了数据集的构建成本,减少数据集构建中的人为误差,保证了数据标签的精度。应用到地图信息提取领域的通用大模型SAM既支持小样本学习,又具有较强的图像特征表达能力,很适合处理复杂地图数据。SAM的引入能够验证当前备受关注的大模型在地图领域的可用性,为地图信息提取提供一种思路。
1 历史地图水系信息提取
本文主要流程如图1所示。以历史地图【宁夏省境黄河沿岸沟渠水道地形图】为试验数据,首先,在历史地图上裁剪出作为数据集的原图像,在考虑水系符号句法的基础上,运用模糊C均值聚类(fuzzy C-means,FCM)对原图像进行颜色聚类,并借助改良卷积核的数学形态学方法优化聚类结果,构建数据集;然后,针对水系符号数据集特点改进编码器结构与损失函数,以数据标签为提示进行迁移学习,更新权重得到改进SAM;最后,只需在地图上给定提示便可利用改进SAM提取水系信息。
图1
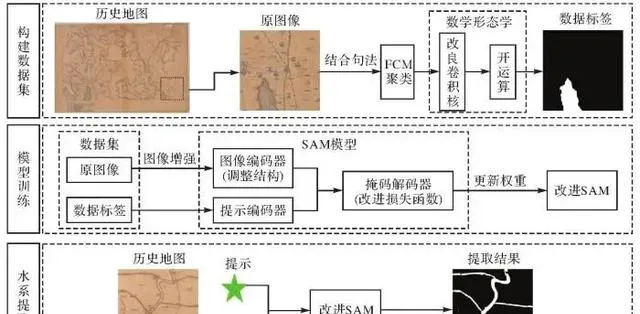
图1 历史地图水系提取流程
Fig. 1 Flowchart of hydrological information extraction from historical maps
1.1 结合符号句法的模糊C均值聚类
模糊C均值聚类是一种基于特征向量划分的无监督聚类算法,能够有效提取目标符号,适用于数据标签的制作。其主要思想是通过优化目标函数得到每个样本点对所有类中心的隶属度,并根据隶属度决定样本点的类属,从而实现数据分类。
FCM通过最小化目标函数 J (式(1))与其约束条件(式(2))来实现聚类

(1)
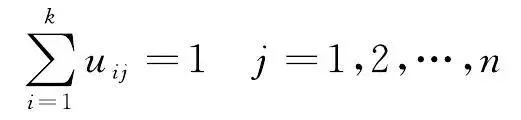
(2)
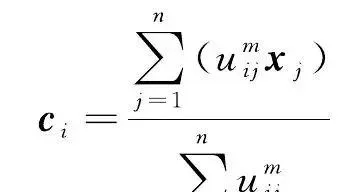
(3)
式中, u ij 表示样本点 x j 对于类 i 的隶属度; k 是类别数; n 为样本个数; m 是一个模糊系数,用来表示样本属于某类的重要程度; c i 表示聚类中心。目标函数 J 由相应样本的隶属度与该样本到各类中心的距离的乘积组成,约束条件则限定每个样本对各个类的隶属度之和为1。
聚类开始前需要确定模糊系数 m 和类别数 k 。模糊系数 m 一般按经验取[1.5,2.5][32] ,类别数 k 与地图符号句法的语音维有关。符号的句法结构可以抽象成语音、语义和句法3个维度[4,33] ,其中语音维包括符号形状、尺寸、色彩等6个要素。历史地图会出现地图折痕磨损符号,褪色改变符号颜色,地图印章与底图混合等情况,因此需要划分更多类别。在综合考虑语音维与各类情况后,选定类别数为12,分别是地图底色、折痕、地图印章、文字注记、水系(湖泊河流水渠)、褪色水系、河堤、等高线、褪色等高线、公路铁路、居民地和其他类。前11类出现频繁、尺寸较大,其中水系包括水系类和褪色水系类,其他类则是孤立点的总和。
确定 m 和 k 后,在满足约束条件的情况下随机初始化隶属度矩阵 u ,根据已知数据更新聚类中心 c i 和隶属度矩阵 u ,并判断 J 是否收敛。若收敛则方法结束,不收敛则重复更新 c i 和 u 直到目标函数 J 收敛或者达到最大迭代次数。令 m 分别取1.5、2、2.5进行多次试验,试验结果只保留水系。最终发现 m 取2时提取效果最佳(图2)。
图2

图2 FCM聚类结果
Fig. 2 Results of FCM clustering
由于历史地图精度有限且褪色严重,FCM算法虽能得到大致结果,但是断点多,边界不清晰,受颜色相似的非水系信息影响大,存在大量噪点与错误像素点,无法作为数据标签使用,需要借助其他方法做进一步优化。
1.2 改良卷积核的数学形态学方法
为进一步优化聚类得到的结果,需要使用数学形态学方法[34-35] 。数学形态学包含膨胀、腐蚀等多种方法,能够改变物体形状,连接断点并去除孤立点,适用于数据标签的优化。
在进行膨胀腐蚀操作时,首先,定义具有锚点的卷积核,锚点一般为卷积核的中心点;然后,将卷积核与目标图像进行卷积,计算卷积核覆盖区域的像素点的最大值或最小值,并将该值赋给锚点所在的像素。具体公式为
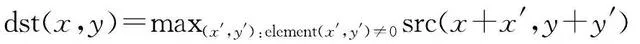
(4)
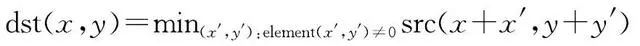
(5)
式中,( x , y )是图像的像素点坐标;( x ′, y ′)是卷积核中的坐标;max表示求最大值;min表示求最小值;dst为更改后的像素值;src为原始的像素值;element表示坐标( x ′, y ′)的像素值。在( x ′, y ′)≠0的前提下,取卷积核中的极值进行像素替换,以此类推直到卷积核遍历完成整张图像,最终完成膨胀腐蚀操作。
在实际处理图像时,经常会将膨胀腐蚀操作混合使用,称之为开运算和闭运算。普通开运算是使用值为1的卷积核先腐蚀后膨胀,主要用于消除图像噪点。不过在实际应用中开运算常因无法准确判断噪点的孤立程度而错误消除像素点。本文为提升开运算消除噪点的能力,将值为1的传统卷积核改良为均值滤波卷积核。均值滤波卷积核的值为卷积核元素个数的倒数,能够使每个输出像素为其周围像素的均值。相比传统卷积核,均值滤波卷积核可以通过平滑处理图像更好地孤立出噪点,提高消除精度。
为确定最优参数,进行多组试验。首先将聚类结果二值化来提高图像质量。观察聚类结果发现断点大多为2~5个像素,因此卷积核大小分别设置为3×3、5×5,开运算迭代次数分别设为10、20、30,进行6次试验取最优结果,最终确定卷积核大小为3×3,迭代次数为20次。图3表示普通开运算和改良开运算的结果对比。可以看出使用均值滤波卷积核的改良开运算提取结果更加准确连贯,噪点和多余像素点都被去除,能够作为数据标签使用。
图3
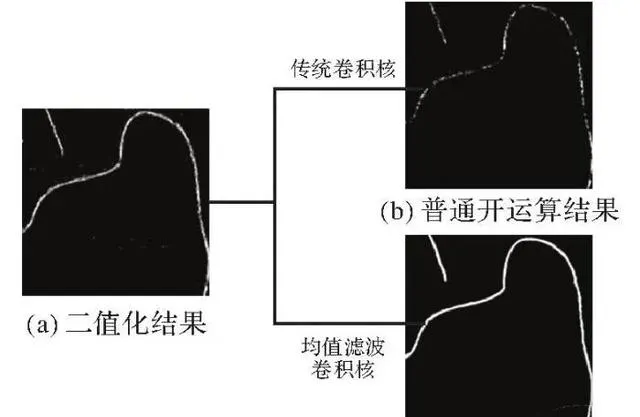
图3 开运算结果对比
Fig. 3 Comparison of open operation results
1.3 针对水系符号数据集的改进SAM
SAM设计的成功取决于3大要素:可提示的分割、庞大的数据集和出色的模型架构[30] 。可提示的分割使得模型能够在不改变模型权重的基础上,通过输入相关提示词来获取想要的输出结果。庞大的数据集则是借助数据引擎生成的迄今为止最大的标记分割数据集。本文重点关注模型架构。
SAM分为图像编码器(image encoder)、提示编码器(prompt encoder)和掩码解码器(mask decoder)3部分。图像编码器使用了掩码自编码器(masked autoencoders,MAE)方法预训练的VIT(vision Transformer)模型[36] 。MAE是一种自监督学习方法,能够将输入的图片分块,并随机进行遮盖,之后借助编码器和解码器重构这些被遮盖的像素。VIT模型是Transformer模型在CV领域的应用[37] ,用于把图像映射到特征空间,具体结构如图4所示。将图片输入图像编码器后,首先使用卷积分块缩小尺寸,之后借助Flatten函数将分块的图像转换成向量,并与位置信息(position embedding)相加,相加结果经过Transformer Encoder处理生成特征图,最后再通过两层卷积对特征图进行降维,得到图像嵌入(image embedding)。位置信息是初始为0的参数矩阵,用于后续位置更新。SAM默认的输入尺寸为1024×1024像素,本文试验数据集图像为512×512像素,若直接输入默认图像编码器后会存在大量无意义的填充,为提高模型效率将Transformer Encoder调整为8个Transformer Block,其中6个应用局部注意力机制,剩余2个为全局注意力机制。内部的Transformer Block由一个注意力机制模块和多个全连接层组成。
图4
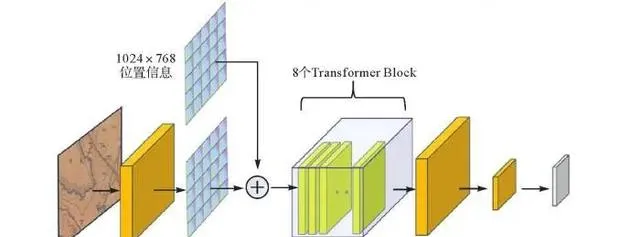
图4 图像编码器结构
Fig. 4 Structure of image encoder
提示编码器的作用是将提示映射到特征空间中,具体结构如图5所示。其内部包含两类提示:稀疏提示(点、框、文本)和密集提示(掩码)。本文输入的掩码为密集提示,使用卷积处理,在输入提示编码器前首先使用下采样缩小尺寸,之后经过3层卷积使提示嵌入(prompt embedding)与图像嵌入的尺寸相同。
图5
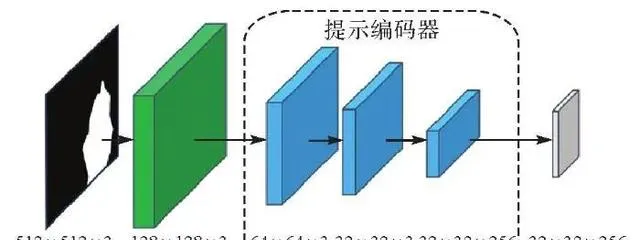
图5 提示编码器结构
Fig. 5 Structure of prompt encoder
编码器得到提示嵌入和图像嵌入,最终逐元素求和并输入掩码解码器中。掩码解码器由多个反卷积层和上采样层组成,用于将图像嵌入、提示嵌入和输出标记映射到掩码,基于掩码更新模型权重,最终生成原始图像大小的分割结果。输出标记为参数矩阵,用于后续预测分类。反卷积层包括反卷积核、激活函数和批归一化等操作,用于对嵌入与特征图进行特征融合。上采样层用于恢复图像大小。在更新权重时,掩码解码器会根据损失函数的值输出3个掩码,由于迁移学习过程中已有明确的数据标签作为掩码,因此需要更改结构使其只输出1个掩码,提高权重优化效率。
水系要素在地图中占比很小,非水系要素占据大量地图空间,因此本文构建的水系符号数据集存在正负样本数量不平衡的问题。大量非水系要素会增加训练时间,影响模型效果。为解决这一问题本文选择Focal Loss(FL)损失函数。Focal Loss基于二分类交叉熵损失函数做出改进,是一个能够动态缩放的交叉熵损失函数,公式为
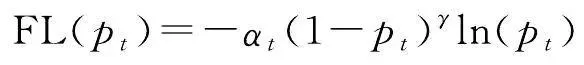
(6)
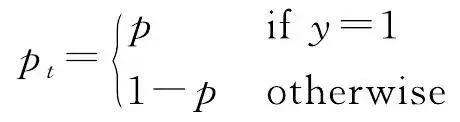
(7)
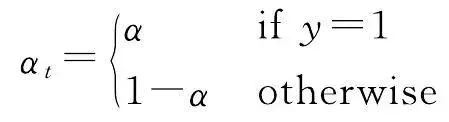
(8)
式中,(1- p t ) γ 为调制因子, γ 的取值范围为[0,5], p t 和 α t 与 y 的取值相关(见式(7)、式(8)); y 的取值为1和-1,分别代表前景和背景; p 的取值范围为[0,1],是模型预测属于前景的概率; α 是权重因子,取值范围为[0,1]。
Focal Loss通过 α t 抑制正负样本的数量失衡,通过 γ 抑制难、易样本的数量失衡。经试验证明 α 取[0.5,1]能够增大正样本权重, γ 取[1,5]能够增大难样本的权重,当 γ 增大时减小 α 才能够取得更好的效果[38] 。因此本文设置两组超参数,第1组 α =0.5, γ =0.5;第2组 α =0.25, γ =2,其他参数均一致,分别进行迁移学习,训练过程中损失函数的变化趋势如图6所示。
图6
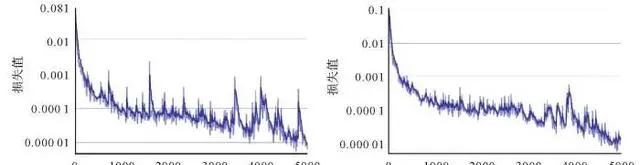
图6 不同超参数的损失函数曲线
Fig. 6 Loss function curves of different hyperparameters
第1组超参数在第1200个iter(1个iter是网络跑完一次batchsize数量的样本)得到最佳权重,第2组超参数在第2800个iter得到最佳权重。随着迭代的进行,第1组超参数出现震荡现象,而第2组超参数的收敛过程更加平稳,因此,选择第2组超参数 α =0.25, γ =2。
2 试验与分析
2.1 试验环境与数据
试验在Windows环境下进行,使用Pytorch深度学习框架,编程语言为Python,硬件条件CPU为AMD Ryzen 7 7745HX 16 GB内存,GPU为NVIDIA GeForce RTX 4060 8 GB显存。本文试验数据来源于1933—1935年间绘制的【宁夏省境黄河沿岸沟渠水道地形图】。该图以地形图形式详细记录了当时宁夏黄河沿岸的地理情况,包含河流、湖泊、道路、沟渠、房屋等各类地理要素。本文研究主要关注水系要素。
试验历史地图中河流沟渠与现代地图类似,均采用线状符号表示;湖泊则不同于现代地图中的蓝色面状符号,水域范围内采用等高线详细表示内部地形变化(图7)。
图7
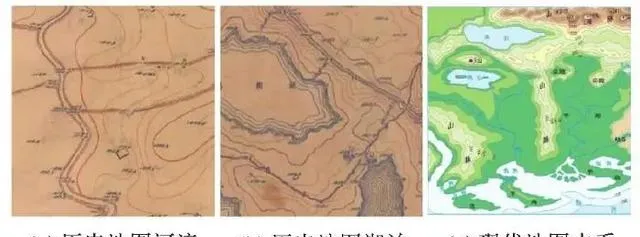
图7 历史与现代地图水系对比
Fig. 7 The comparison of hydrological representation between historical maps and modern maps
水系提取的本质是二分类语义分割,因此在构建数据集时应考虑地图符号的语义维。语义维强调符号的语义信息与组成关系,下面结合实例进行分析。
根据符号的语义表达,水系类要素可以进一步划分为河流、沟渠与湖泊。河流由两条平行的蓝色细线组成,外侧用红色的虚线表示河堤;沟渠为单条蓝色细线,外侧也为红色虚线河堤。二者在地图中都呈线状且不具备高程信息,根据语义其标签形式应为表示河流或沟渠轮廓的线条。湖泊统一用蓝色等高线表示,等高线的疏密能够反映湖泊深度。浅湖内部的等高线细而密集,且集中在湖泊边缘;随着湖泊深度变大,等高线会逐渐向湖泊内部延伸,最终布满整个湖泊。不同深度的湖泊组成关系不同,表示的语义也不同,如果统一用面状符号表示,既破坏了符号的语义与组成关系,又影响训练质量和预测精度,同时也无法体现历史地图水系符号与现代地形图的差异。因此在参考语义维后,将湖泊的标签形式分为等高线未布满湖泊的环状符号与等高线布满湖泊的面状符号,分别对应现实中的浅水湖和深水湖。
非水系类要素在聚类时已根据语音维初步划分,接下来结合语义维再进行分析。考虑到地图底色、折痕和各类褪色现象不具备地图语义信息,将非水系整理为地图印章、文字注记、等高线、道路和居民地5类并依次做好标签。具体标签分类如图8所示。
图8
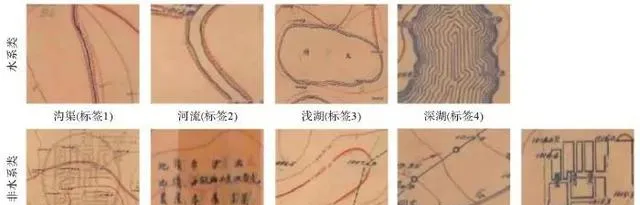
图8 标签分类
Fig. 8 Tag classification
运用模糊C均值聚类和改良的数学形态学方法得到水系的数据标签,借助水平镜像、高斯模糊等数据增强操作增加样本多样性,最终完成数据集构建。数据集共有210张512×512像素的地图图像及对应的标签,单张图像可以对应多种标签类别,不同类别标签数量情况见表1,部分样本图像如图9所示。其中白色表示水系信息,黑色为非水系信息。为验证本文模型有效性,选取语义分割常用网络U-Net、原始SAM目标分割模型和本文改进的SAM目标分割模型进行多模型对比试验。
表1 不同类别标签数量情况
Tab. 1 Number of tags in different categories
| 标签类别 | 数量 | 占比/(%) |
|---|---|---|
| 沟渠 | 186 | 88.57 |
| 河流 | 59 | 28.10 |
| 浅湖 | 151 | 71.90 |
| 深湖 | 33 | 15.71 |
| 地图印章 | 15 | 7.14 |
| 文字注记 | 210 | 100.00 |
| 等高线 | 210 | 100.00 |
| 道路 | 91 | 43.30 |
| 居民地 | 118 | 56.19 |
新窗口打开| 下载CSV
图9
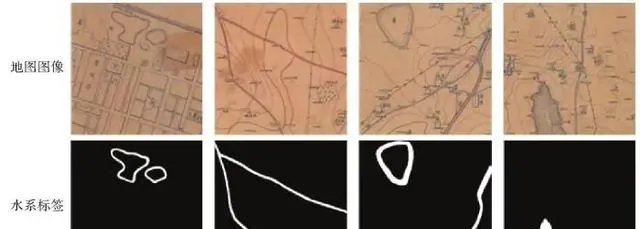
图9 数据集示例
Fig. 9 Dataset example
2.2 评价指标
本文从像素精度评价水系提取效果,评价指标采用语义分割问题中常见的准确率(accuracy, A )、交并比(IoU)、精度(precision, P )和 F 1 值。准确率表示网络的预测结果的整体准确性,即预测正确的像素个数占总像素个数的比例;交并比是像素的真实值与预测值的交集与并集的比值;精度是预测正确的像素个数与预测为正类的像素个数的比值; F 1 值是查准率与查全率的平衡。上述各评价指标的具体公式为
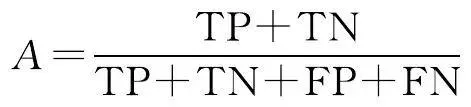
(9)
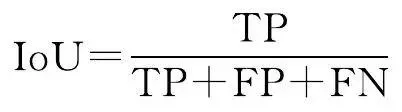
(10)
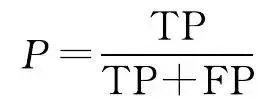
(11)
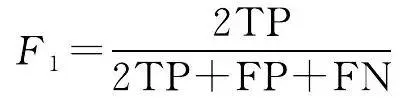
(12)
式中,TP为水系符号被正确预测的像素数量;TN为非水系符号被正确预测的像素数量;FP为非水系符号被预测为水系的像素数量;FN为水系符号被预测为非水系的像素数量。
2.3 试验结果
预测前,首先基于上文构建的水系符号数据集进行模型训练。U-Net网络采用监督训练方法,由于样本数量较少,采用批量梯度下降算法,初始学习率为0.000 1,最低学习率为0.000 001,batchsize为8,共训练200个epoch;改进SAM在预训练模型参数的基础上进行迁移学习[39] ,损失函数的超参数设置为 α =0.25, γ =2。原始SAM使用预训练模型进行预测。最终试验结果从可视化和定量研究两方面来对比,可视化结果如图10所示。根据不同的水系类别和干扰因素具体分析每个模型的提取效果。
图10

图10 多模型水系提取效果可视化对比
Fig. 10 Visual comparison of multi-model hydrological information extraction effects
(1)针对河流沟渠。U-Net虽然能够得到河流沟渠的大致轮廓,但是不能与地图中的其他线性符号形成有效区分,并且提取结果宽度变粗,效果较差;原始SAM能够提取河流沟渠轮廓,但结果不连贯,存在断点和突出点;改进SAM的提取结果整体连贯性最佳,几乎没有断点与突出点。
(2)针对浅水湖。由于浅水湖的标签形式为环状符号,因此U-Net的提取结果依旧存在轮廓加粗、错误提取非水系符号的问题;原始SAM提取出湖泊大致轮廓,不足之处在于湖泊边界部分存在变细和缺失的问题;改进SAM效果最佳,但也存在提取结果与标签相比更细的问题。
(3)针对深水湖。U-Net可以较好地提取出面积较大的湖泊,不过在湖泊边缘处精度较低,对于面积较小的湖泊只提取到湖泊边界;原始SAM提取效果一般,在湖泊边界处错误较多,存在多提错提的问题;改进SAM与标签最为相似,不过在湖泊内部存在提取遗漏。
(4)针对受其他因素干扰的水系。地图符号用于描述环境要素,具有特定的空间性特征,更易受其他因素的干扰。例如,河流沟渠与颜色相似的居民地位置很近;湖泊受地形影响与外侧的等高线形状类似;显示高程与湖泊名称的文字注记会直接和水系符号重合等。对于这类水系,U-Net的提取效果极差,完全无法进行区分;原始SAM能够区分水系、等高线和居民地,不过无法处理颜色相似的文字注记;改进SAM除少部分位置重叠的文字注记无法处理外,能够区分绝大多数干扰因素与水系符号。
总体来说,U-Net由于训练数据集规模小,样本数量不足,使得模型对于地图抽象特征的表达能力不足,无法区分水系与其他符号,提取结果中除水系符号外还包含等高线、房屋、道路等干扰符号,整体与标签差异最大,提取效果最差。原始SAM在提取线状水系符号时提取效果较好,但针对面状湖泊时,受颜色和文字注记等因素的影响较大,难以提取出较高精度的湖泊信息;改进SAM模型通过迁移学习优化参数,提取效果最好,提取结果边界清晰,轮廓连贯,受其他地图符号干扰最小,错提少提现象少。通过结果可视化和计算模型精度的各项评价指标(表2)对比,验证了本模型的有效性。
表2 多模型水系提取精度对比
Tab. 2 Comparison of multi-model water system extraction accuracy
| 模型 | 准确率 | IoU | 精度 | F 1 值 |
|---|---|---|---|---|
| U-Net | 84.31 | 61.62 | 62.32 | 76.48 |
| 原始SAM | 89.68 | 76.65 | 84.70 | 84.40 |
| 改进SAM | 94.13 | 83.25 | 91.18 | 90.86 |
新窗口打开| 下载CSV
由表2可知,本文的改进SAM模型在水系提取方面准确率最高,达到94.13%,比原始SAM要高出4.45%,比U-Net高出18.81%;在其他评价指标方面,改进SAM依然为最高,IoU、精度、 F 1 值分别为83.25%,91.18%、90.86%,比原始SAM高出6.6%、6.48%、6.46%,比U-Net高出28.26%、26.14%、24.58%。通过定量结果对比,证明了本文的模型可以高精度提取历史地图水系信息,相比传统深度学习方法有很大的进步。
综上所述,本方法能够区分并处理历史地图中各类复杂信息,标准化、自动化的提取流程可以用于提取其他类型地图信息,或是应用到其他类别地图中,具有泛用性。
2.4 讨论
上述结果证明,本文提出的智能化历史地图水系信息提取方法十分有效,提取效果优于传统语义分割网络U-Net和原始SAM,这与SAM在水系符号数据集上的迁移学习是分不开的。
U-Net作为常用的语义分割网络,大部分情况下处理对象为高精度图像或遥感影像,对物体的大小、颜色、位置、方向等具体特征会更敏感,适合处理具有较低语义信息的医疗图像等。历史地图本身精度较低,同时还具有地图符号特有的句法信息与符号间逻辑关系[3-4] 。例如等高线作为不同海拔高度的水平面与实际地面的交线,其大多是闭合且互相平行的;由于地势关系使得河流与等高线的切线近似垂直;由于坡度关系交通运输线路和人工水渠大多与等高线平行;房屋村落等人类聚集地大多位于等高线稀疏的地方等。上述这些抽象特征使得普通深度学习网络无法很好地理解水系符号与其他地图符号间的差异,进而导致在水系提取中受其他符号影响大,无法分辨河流、水渠、道路与等高线。SAM通用大模型的大规模预训练数据集使得模型具有分割不同复杂度图像的能力,因此原始SAM的水系提取效果尚可。不过其设计初衷是通用性和使用广度,模型结构也是为泛用性服务,这就使得SAM在具体分割任务中仍具有较大的提升空间。结合符号句法构建水系符号数据集,并根据数据集特点改进模型进行迁移学习后,改进SAM可以更好地理解历史地图符号,最终提取效果更佳。
研究同时发现,改进SAM的结果与标签仍存在一定差异,主要表现在3个方面:①会被颜色相近的非水系符号影响,具体体现在提取结果将文字与河流混淆,出现断点或是突出点,整体比标签更细或更粗。②在湖泊内部存在提取遗漏,无法精准地提取湖泊面状符号。③当水系符号间距离过近时,会出现无法准确区分不同水系的问题。发生上述问题的主要原因是历史地图精度过低,模糊了文字或是其他符号,使其与河流差异过小;褪色严重使得湖泊内部与地图底色混合,最终导致模型无法区分水系与其他符号。这些不足需要后续的研究进行改进。
将历史水系提取结果与1979年和2022年的水系遥感影像作对比(图11),结果显示80多年来各类水系发生了巨大的变化。河流水渠除唐徕渠、新开渠等历史名渠外,大多发生改道或偏移,部分沟渠因地势平坦、有施工基础变成了交通道路。湖泊面积变小,大部分区域变成湿地,土地肥沃处变为田地,平坦处变为城市建设用地。通过古今水系形态对比能够清楚地了解黄河沿岸各类水系时空演变格局,为今后的水资源规划与治理提供参考。
图11
图11 水系提取结果与近现代水系遥感图像对比
Fig. 11 Comparison of hydrological information extraction results with modern remote sensing images
3 结论
针对历史地图信息难以有效被利用的问题,本文将传统算法与通用大模型SAM相结合,借助模糊C均值聚类和改良的数学形态学方法自动构建数据集,根据数据集特点改进SAM结构与损失函数并进行迁移学习,最终实现了高精度提取历史地图水系信息。试验结果证明,本文方法相比其他方法具有更高的提取精度,通用大模型SAM的引入验证了大模型在地图领域的可用性,为未来地图信息提取提供一种思路。得益于改良算法的高精度和大模型优秀的泛用性,本文方法还能够应用到现代地形图或是其他类型地图信息提取任务中。
后续工作将在以下几个方面展开:①对历史图像做超分辨率处理,提高图像精度,修复褪色以增大各类特征差异。②将本文方法应用到房屋、文字注记、河流道路等其他类型的地图符号,更全面地检验方法的泛用性,寻找不足。③针对不同任务构建专门的地图符号数据集,提高数据集规模,增大样本数量。④优化模型参数与网络结构,降低运行时间,提高提取精度。
初审:侯 琳
复审:宋启凡
终审:金 君
资讯
○
○
○
○











