IT之家 2 月 17 日訊息,Meta 首席 AI 科學家 Yann LeCun 在 2022 年推出了 JEPA(Joint Embedding Predictive Architectures)模型架構,次年基於 JEPA 架構開發了一款「I-JEPA」圖片預測模型,目前又推出了一款名為「V-JEPA」的視訊預測模型。

據介紹,相關 JEPA 架構及 I-JEPA / V-JPA 模型主打「預測能力」,號稱可以以「人類理解」的方式,利用抽象性高效預測生成圖片 / 視訊中被遮蔽的部份。
IT之家註意到,研究人員使用一系列經過遮蔽處理的特定視訊訓練 I-JEPA / V-JEPA 模型,研究人員要求模型利用「抽象方式」填充視訊中缺失的內容,從而讓模型在填充間學習場景,進一步預測未來的事件或動作,進而達到對世界更深層次的理解。

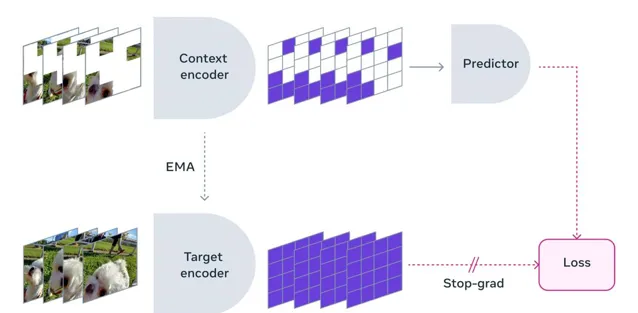
研究人員表示,這種訓練方法能夠讓模型專註於影片的高層次概念,而「不會鉆牛角尖處理下遊任務不重要的細節」,研究人員舉例「人類觀看內含樹木的影片時,不會特別關心樹葉的運動方式」,因此采用這種抽象概念的模型,相對於業界競品效率更佳。
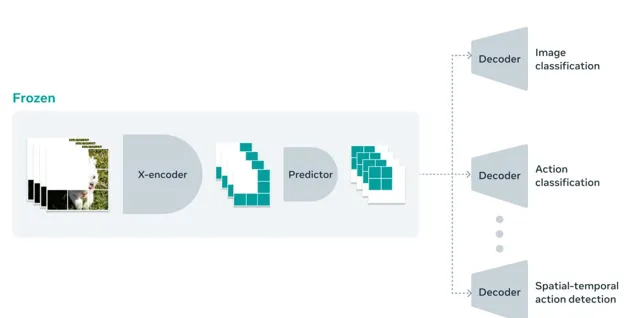
研究人員同時提到,V-JEPA 采用一種名為「Frozen Evaluations」的設計結構,即「模型在預訓練之後,核心部份不會再改變」,因此只需要在模型之上添加小型專門層即可適應新任務,具有更高普適性。











