第五部份 核心子系統功能詳述

1、故障短語抽取子系統
2.1 文本預處理
文本預處理是文本挖掘過程中必不可少的首要工作,預處理的結果直接影響到後續步驟處理的效果。因此,本系統透過文本預處理對語料庫的數據進行清洗,以提高之後的故障特征提取的效果。文本預處理主要步驟包括分詞、停用詞過濾和詞性過濾等。具體步驟如下:
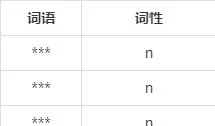
第一步,分詞。本系統首先對語料庫進行了中文分詞,利用「jieba」分詞工具,其主要使用了基於詞典以及基於統計的分詞演算法:對於「jieba」內建詞典中已用的詞語可以最大機率的進行切分組合,分詞效果好;對於未登陸的詞語采用隱馬可夫模型(HMM)進行辨識切分,分詞效果差。由於「jieba」內建詞典中主要都是通用詞匯,對於****領域的專業詞匯並未記錄,導致語料中如「***」、「***」、「***」等專業詞匯不能有效辨識,進而造成語料庫的分詞結果較差。因此,系統透過對「jieba」分詞工具引入專業詞典來確保分詞結果的準確性。專業詞典中主要記錄了**故障相關的專業詞匯,記錄格式為「詞語 詞性」,如下表所示:
表3 部份專業詞匯
第二步,停用詞過濾。本系統過濾的停用詞主要包括以下兩部份:
1)特殊符號、標點符號以及單個字。
2)故障文本中特有的如***、***、***等幹擾詞。
第三步,詞性過濾。透過上述分析可知故障關鍵詞主要是名詞、動詞和動名詞,因此,系統透過詞性過濾將非以上詞性的單詞過濾掉,以提高關鍵詞在分詞結果中的出現機率,使得關鍵詞提取演算法的準確率有所提升。
經過以上三步的文本預處理後,由語料庫中的故障文本得到候選關鍵詞集合,之後將透過關鍵詞提取演算法提取出故障文本中的關鍵詞。
2.2 基於改進TextRank的關鍵詞提取
系統透過對**故障數據進行觀察分析,提出了基於改進TextRank的關鍵詞提取方法,以故障現象文本:「******」為例。將由共現關系得到的候選關鍵詞詞圖中的邊上權值改為改進後的轉移機率。之後,基於第五部份的公示進行叠代計算,直到各詞項的分值收斂,停止計算。按分值大小排序,取前5個詞語作為關鍵詞提取的結果:[('****',1.0),('故障',*****),('重新開機',****),('不成功',*****),('***',0.7798)]。
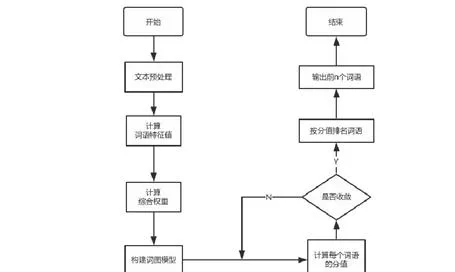
為驗證改進TextRank關鍵詞提取演算法提取效果是否優異,探索不同詞語特征對TextRank演算法提取結果的影響,系統設計四組對照實驗,都是以200篇故障現象文本為測試集,分別提取3個、5個和7個關鍵詞。使用準確率P(precision)、召回率R(recall)、F值(F-score)進行效果評價。

其中,P和R的取值都在0到1之間,結果越接近於1,說明演算法的查準率和查全率越高,效果越好;F值則是綜合考慮了準確率和召回率。正確關鍵詞由人工標註所得。
在TFIDF、LDA、TextRank和改進TextRank的結果比較的對照實驗中,主要比較基於統計的TFIDF演算法、基於主題模型的LDA演算法、基於圖的TextRank演算法以及本文改進的TextRank演算法的結果。其中LDA模型設定的主題個數為10個。
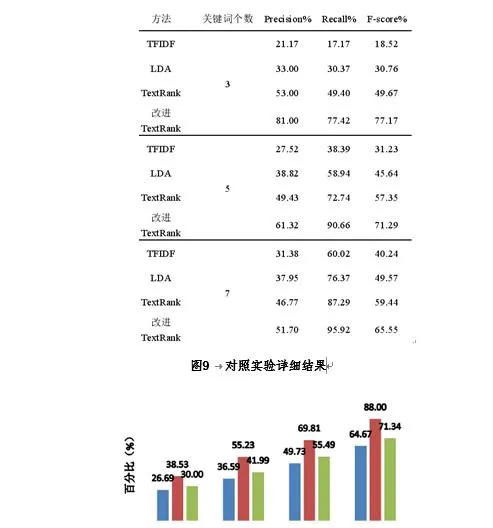
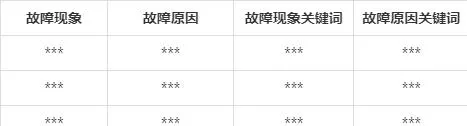
透過對照實驗結果,可知系統提出的改進TextRank在提取故障文本關鍵詞的效果上比傳統演算法有所提升。由此經過關鍵詞提取演算法得到的**故障文本關鍵詞的部份結果如下表所示。提取的關鍵詞是由分值從高到低排名的前5個。可以看到雖然絕大多數的故障關鍵詞出現在分值排名前五中,但還是有如「***」、「***」、「***」和「***」等關鍵詞分值排名在前五之後。所以單純以關鍵詞排名來抽取故障短語並不合適,而且分開的詞語也不能很好的表示故障現象和故障原因,需要進行後續處理。
表4 部份數據的關鍵詞提取結果
2.3 基於文本相似度的故障短語抽取











