在這個金秋,「日日新·商量」又拿了金牌!
今日,中文多模態大模型測評基準SuperCLUE-V釋出10月榜單:
商湯日日新·商量多模態大模型(SenseChat-Vision5.5)憑借多個任務上的出色表現,總得分位列國內大模型第一梯隊,智奪金牌。
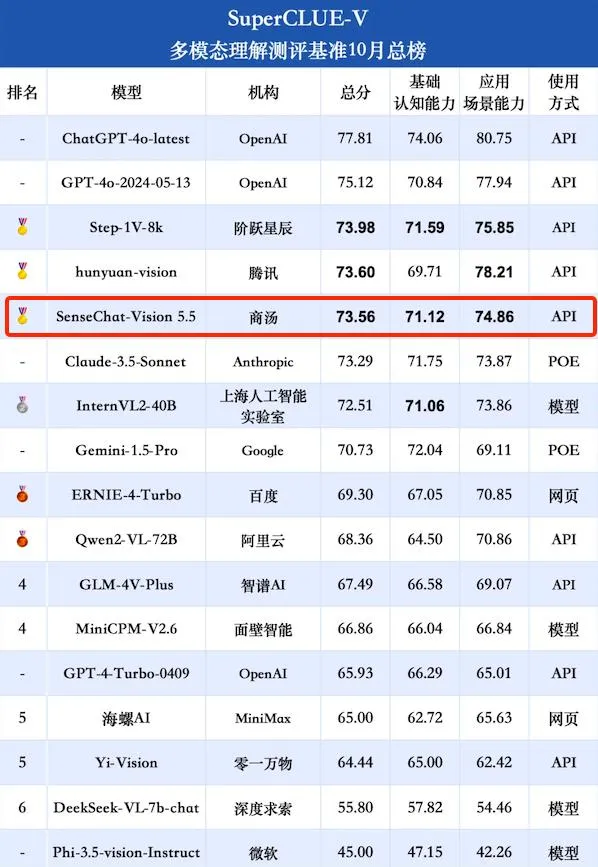
憑借卓越的多模態基礎能力和出色的套用能力,商湯SenseChat-Vision 5.5榮獲了總分73.56的高分,並在數理邏輯維度取得第一,體現其強大的推理能力。
SenseChat-Vision5.5基礎能力突出,
數理邏輯維度超越GPT-4o
本次SuperCLUE-V涵蓋了國內外最具代表性的11個開源/閉源多模態理解大模型,聚焦多維度能力評估,包括基礎能力和套用能力兩個大方向,以開放式問題形式對多模態大模型進行評估,涵蓋了8個一級維度30個二級維度。
報告稱SenseChat-Vision 5.5在基礎能力-數理邏輯推理任務如圖表推理、場景推理方面具備領先優勢。榜單顯示,在數理邏輯分析能力中,SenseChat-Vision 5.5超越國內外所有參評模型包括GPT-4o的最新版本,位列第一。
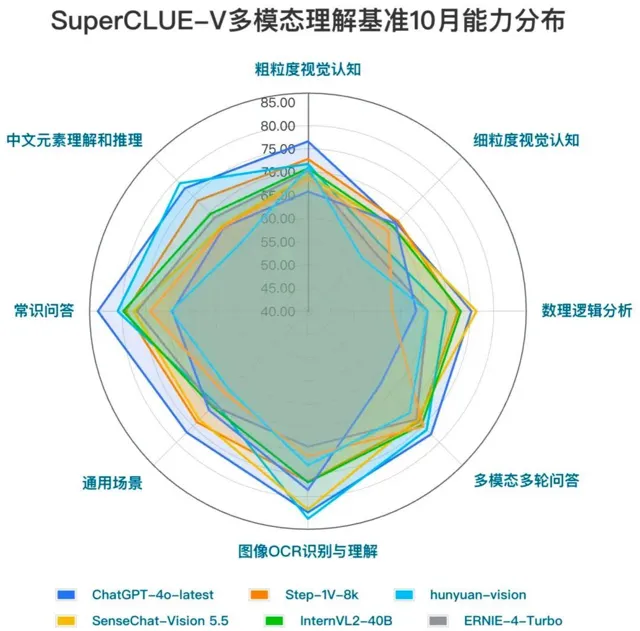
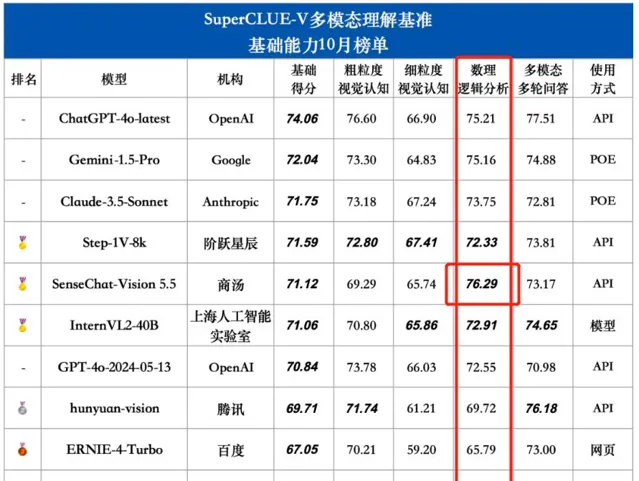
SuperCLUE-V采用細粒度評估方式,構建專用測評集,每個維度進行細粒度的評估並可以提供詳細的反饋資訊,以下為SenseChat-Vision 5.5測試案例部份呈現:
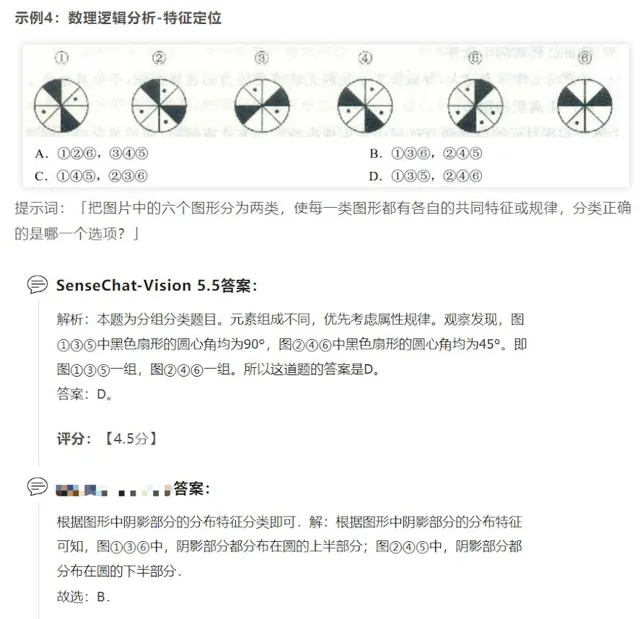


目前,多模態大模型能力顯著提升,可提供純語言、多圖理解、語音、文生圖、擬人、端側模擬、行業模型等多模態、多版本、強場景Agent形態。
前瞻構造高階思維邏輯數據,
用推理能力增強AI大模型智慧
如今,復雜推理成為各模型之間的重要能力壁壘。對於大模型能力的分層,商湯科技董事長兼CEO徐立此前就提出三層架構(KRE)理論,即:
第一層知識(Knowledge),世界知識的全面灌註;
第二層推理(Reasoning),理性思維的質變提升;
第三層執行(Execution),世界內容的互動變革。
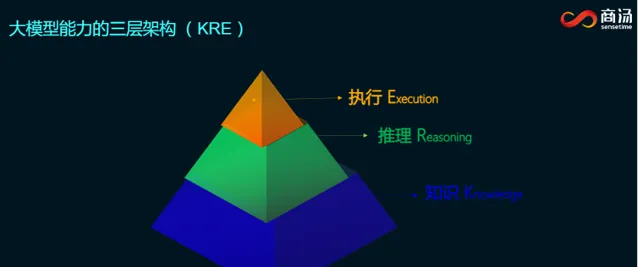
這三層可以組成一個對於世界提供生產力工具模型的完備能力,其中提升基礎模型的推理能力是目前人工智慧發展的大方向。徐立還提出在垂直行業裏如何構造高階思維邏輯的合成數據,也是制勝關鍵。
今年7月釋出的「日日新5.5」大模型體系就創新使用大量使用合成高階思維鏈數據,提升推理思維能力,在數理邏輯、英文、指令跟隨等方面能力增強明顯,2個多月的時間把基模型的能力提升了30%。
未來,商湯科技將繼續堅持基礎大模型的持續研發與投入,前瞻探索最先進的大模型技術,突破數據與算力的限制,引領大模型的創新與落地。
目前,SenseChat5.5已經套用在商量網頁版(WEB)——一款擅長高效搜尋、整理、輸出資訊的智慧套用,工作、學習、生活中的任何問題,問問商量,都能解決。











