倒茶、疊衣服、整理書籍、丟垃圾,現在的家務機器人幹活真是越來越熟練了。
不過,也不是每個家務機器人都能做到像動圖裏那麽流暢的。
熟練家務的背後,是李飛飛團隊琢磨出來的一種新辦法。
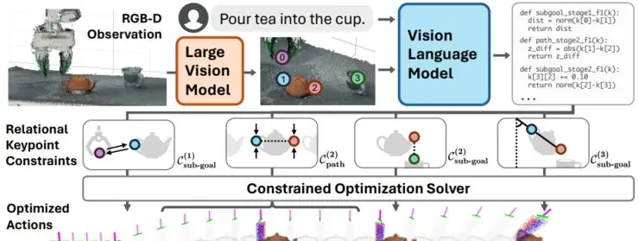
他們把任務動作拆解後標記出幾個關鍵點,再給到具體規則讓機器人知道這些點之間有什麽聯系,要怎麽操作比較好。除此之外,機器人還能自主學習,越練習越厲害。
以倒茶這個動作為例,機器人會先用網路攝影機確定茶杯茶壺等的位置、形狀等要素,再辨識出關鍵點,比如茶杯的中心點和把手的中心點,ReKep 會給機器人編寫出一系列規則,告訴它要用什麽角度、怎麽拿怎麽傾倒、用多大力氣等,機器人只要按照規則行動就能成功倒茶了。


不得不說,這麽一個簡單的動作想讓機器人做好是真的是太難了。要是沒有 ReKep 技術,想看到機器人熟練地幹各種家務活還不知道要等到猴年馬月。
畢竟今年三月份的時候,李飛飛團隊的家務機器人還是這樣的,只會擦擦桌子切個水果:
而半年後的今天,就已經前進演化成全能選手了:

目前,李飛飛團隊關於 ReKep 技術的論文已在 arXiv 公開,程式碼也已開源。
論文標題:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
計畫程式碼:github.com/huangwl18/ReKep
論文概述
研究問題和動機
李飛飛團隊旨在解決與機器人操作任務相關的挑戰,這些任務涉及多個空間關系和時間依賴階段,需要對復雜的空間和時間關系進行編碼。
他們希望開發一個廣泛適用的框架,能夠適應需要多階段、野外環境、雙手操作和反應行為的任務,透過基礎模型的進展在獲取約束方面具有可延伸性,並能夠即時最佳化以產生復雜的操作行為。
難點與挑戰
現有的使用剛體變換表示操作任務約束的方法缺乏幾何細節,要求預定義的物體模型,並且無法處理可變形物體。
在視覺空間中直接學習約束的數據驅動方法也在收集訓練數據時面臨挑戰,因為約束的數量在物體和任務方面呈組合增長。
技術創新
李飛飛團隊提出了一種名為關系關鍵點約束(ReKep)的方法,用於機器人操作。
ReKep 將操作任務編碼為約束,連線機器人與其環境,而無需手動標註。該方法利用Python函式將一組語意上有意義的三維關鍵點對映為數值成本,從而能夠表示復雜的空間和時間關系。
該框架旨在透過大型視覺模型和視覺-語言模型自動生成約束,實作從自然語言指令和RGB-D觀測中高效地指定任務。
他們還提出了一種演算法例項,可以即時高效地解決最佳化問題。
真實實驗
實驗涉及多個任務,包括倒茶、回收罐、整理書籍、打包盒子、折疊衣物、裝鞋盒和協作折疊等。這些任務被設計來測試系統在不同方面的效能,如空間和時間依賴性、對環境的適應力、雙手協調和與人類的互動。
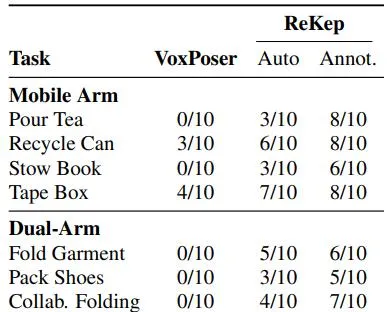
輪式單臂平台和固定式雙臂平台的成功率
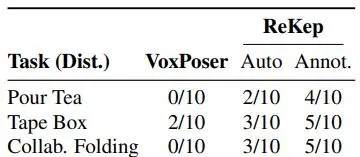
兩個機器人平台在外部幹擾下的成功率
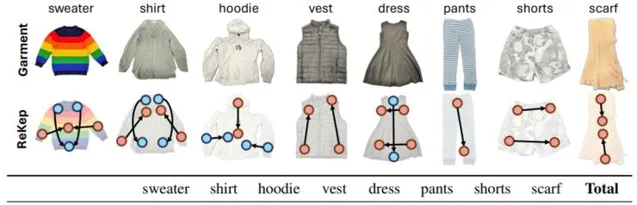
ReKep 用於折疊不同類別服裝的新型雙臂策略及其成功率
實驗結果顯示,ReKep在多種任務上的成功率較高,證明了其在自動化操控任務中的潛力。成功率根據任務的不同而有所差異,但總體上表現良好。
技術解讀
關系關鍵點約束(ReKep)
首先,他們定義了單個ReKep例項,並且假設已經指定了一組 ? 個關鍵點。每個關鍵點 ??∈ℝ3 指的是場景表面上的一個 3D 點,其座標依賴於任務語意和環境(例如,手柄上的抓取點,壺嘴)。
本質上來說,一個 ReKep 例項編碼了關鍵點之間的一個期望的空間關系,這些關系可能屬於機器人手臂、物體部份或其他代理。
然而,一個操作任務通常涉及多個空間關系,並且可能具有多個時間上依賴的階段,每個階段都涉及不同的空間關系。為此,他們將任務分解為 ? 個階段,並為每個階段 ?∈{1,…,?} 使用 ReKep 來指定兩類約束:
子目標約束
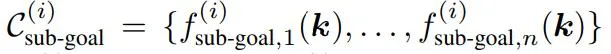
路徑約束
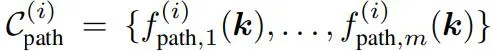
其中 ?sub-goal (?) 編碼階段 ? 結束時需要達到的關鍵點關系,而 ?path (?) 編碼階段 ? 內部需要滿足的關鍵點關系。
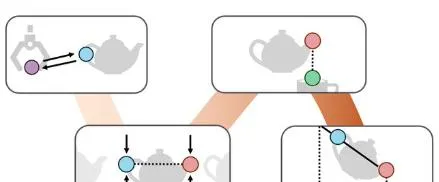
如下圖所示的傾倒任務由三個階段組成:抓取、對齊和傾倒。
階段 1 的子目標約束拉動末端執行器向茶壺手柄靠近。階段 2 的子目標約束指定壺嘴需要位於杯口上方,階段 2 的路徑約束確保茶壺直立,以避免傾倒時溢位。最後,階段 3 的子目標約束指定傾倒角度。
操縱任務作為ReKep約束最佳化問題
他們將末端執行器姿態表示為 e∈ SE(3),將操控任務表述為一個最佳化問題,目標是找到一系列滿足ReKep約束的末端執行器(end-effector)姿態,並將控制問題表述如下:
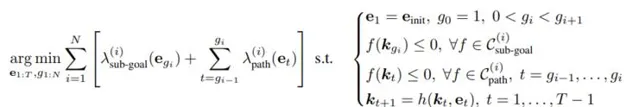
對於每個階段,最佳化演算法需要找到滿足子目標約束的末端執行器姿態,以及實作這些子目標的路徑。
分解與演算法即時例項化
為了即時求解最佳化問題,他們采用了分解方法,僅最佳化下一個子目標及其對應的路徑。
子目標問題:首先解決子目標問題,確定當前階段的末端執行器目標姿態。
路徑問題:在獲得子目標姿態後,解決路徑問題,規劃從當前姿態到子目標姿態的軌跡。
回溯:如果發現任何子目標約束不再滿足,系統可以回溯到之前的階段進行重新規劃。
關鍵點提議和ReKep生成
為了使系統能夠在給定自由形式任務指令的情況下執行野外任務,他們設計了一個使用大型視覺模型和視覺語言模型進行關鍵點提議和ReKep生成的管道,並分成了兩個部份:
關鍵點提議
使用大型視覺模型(LVM),如DINOv2,來提取場景中的特征,並利用這些特征來辨識潛在的關鍵點。這些關鍵點通常是場景中具有語意意義的3D點,例如物體的邊緣、角落或特定物體部份的中心。
ReKep生成
結合關鍵點和任務指令,使用視覺-語言模型(VLM)來生成ReKep,這些約束將用於指導機器人的動作規劃和執行。這一步驟利用了視覺模型對場景的理解以及語言模型對指令的解釋能力。

團隊成員
李飛飛

李飛飛博士是史丹佛大學電腦科學系首任紅杉教授,也是史丹佛以人為本的人工智慧研究所的聯席主任,曾擔任擔任谷歌副總裁和首席科學家,在多家上市公司或私營公司擔任董事會成員或顧問。
李飛飛主導的史丹佛AI實驗室、史丹佛視覺與學習實驗室(SVL)和史丹佛以人為本人工智慧研究院湧現出大量優秀人才,包括 OpenAI 聯合創始人 Andrej Karpathy、國努內第一個堅探索具身智慧的盧策吾、前Google AI中國中心總裁李佳、前阿裏自動駕駛掌舵人王剛等。
她目前的研究興趣包括認知啟發式人工智慧、機器學習、深度學習、電腦視覺、機器人學習和人工智慧+醫療,尤其是用於醫療保健的環境智慧系統。
Wenlong Huang

Wenlong Huang 是史丹佛大學電腦科學專業的博士生,由李飛飛指導,也是史丹佛視覺與學習實驗室 (SVL)的成員。他於 2018 年獲得加州大學柏克萊分校電腦科學學士學位,指導老師是 Deepak Pathak、Igor Mordatch 和 Pieter Abbeel。
他的研究目標是賦予機器人廣泛的泛化能力,使其能夠執行開放世界操控任務,尤其是在家庭環境中。研究興趣包括:
開發能夠充分利用互聯網規模數據或基於這些數據進行訓練的模型的抽象概念
開發能夠表現出廣泛泛化行為的運動技能
Chen Wang(王辰)

Chen Wang是史丹佛電腦科學學院的博士生,導師是李飛飛和 C. Karen Liu。他本科就讀於上海交通大學電腦科學專業,是第一批加入盧策吾團隊研究機器人具身智慧的學生之一。
他的研究目標是制造出具有與人類一樣的靈活性和處理日常任務能力的機器人,因此專註於機器人學習,以實作靈巧操作、模仿人類動作以及長期規劃和控制。
Yunzhu Li

Yunzhu Li現在是哥倫比亞大學電腦科學助理教授,曾是史丹佛視覺與學習實驗室 (SVL)的博士後,與李飛飛、Jiajun Wu 一起工作。北京大學本科畢業後,他在麻省理工學院電腦科學與人工智慧實驗室(CSAIL)獲得博士學位,導師是 Antonio Torralba 和 Russ Tedrake。
目前他在機器人感知、互動和學習實驗室(RoboPIL)進行機器人技術、電腦視覺和機器學習的交叉研究,專註於機器人學習,特別是直觀物理學、具身智慧、多模式感知三個方向,旨在顯著擴充套件機器人的感知和物理互動能力。
Ruohan Zhang

Ruohan Zhang是史丹佛視覺與學習實驗室 (SVL)的研究員,和李飛飛、Jiajun Wu、Silvio Savarese 一起工作。他曾在在德克薩斯大學奧斯丁分校獲得博士學位,指導教授是 Dana Ballard 和 Mary Hayhoe。
他的長期研究興趣是以人為本的人工智慧:理解人類智慧以開發受生物啟發的人工智慧演算法,以及使人工智慧與人類更加相容。最近專註於以人為本的機器人技術:透過數據驅動的方法開發可增強人類福祉的機器人解決方案(系統和演算法)。 雷峰網雷峰網











