對於專註於構建專業人工智慧(AI)模型的開發人員來說,他們面臨的長期挑戰是獲取高品質的訓練數據。較小的專家模型(參數規模在10億~100億)通常利用「蒸餾技術」,需要利用較大模型的輸出來增強其訓練數據集,然而,使用來自OpenAI等閉源巨頭的此類數據受到嚴格限制,因此大大限制了商業套用。
而就在台北時間7月23日(周二)晚間,全球AI領域的開發人員期待已久的開源大模型「ChatGPT時刻」終於到來——Meta釋出最新AI模型Llama 3.1,其中參數規模最大的是Llama 3.1-405B版本。
祖克柏將Llama 3.1稱為「藝術的起點」,將對標OpenAI和谷歌公司的大模型。測試數據顯示,Meta Llama 3.1-405B在GSM8K等多項AI基準測試中超越了當下最先進的閉源模型OpenAI GPT-4o。這意味著,開源模型首次擊敗目前最先進的閉源大模型。
而且,Llama 3.1-405B的推出意味著開發人員可以自由使用其「蒸餾」輸出來訓練小眾模型,從而大大加快專業領域的創新和部署周期。
開源社群的「裏程碑」:Llama 3.1-405B在多項測試中超越GPT-4o
2024年4月,Meta推出開源大型語言模型Llama 3。其中,Llama 3-8B和Llama 3-70B為同等規模的大模型樹立了新的基準,然而,在短短三個月內,隨著AI的功能叠代,其他大模型很快將其超越。
在你追我趕的競爭環境下,Meta最新釋出了AI模型Llama 3.1,一共有三款,分別是 Llama 3.1-8B、Llama 3.1-70B和Llama 3.1-405B。其中,前兩個是4月釋出的Llama 3-8B和Llama 3-70B模型的更新版本。而Llama 3.1- 405B版本擁有4050億個參數,是Meta迄今為止最大的開源模型之一。
而在釋出當天的淩晨(台北時間),「美國貼吧」reddit的LocalLLaMA子論壇泄露了即將推出的三款模型的早期基準測試結果。
泄露的數據表明,Meta Llama 3.1-405B在幾個關鍵的AI基準測試中超越了OpenAI的GPT-4o。這對開源AI社群來說是一個重要的裏程碑:開源模型首次擊敗目前最先進的閉源大模型。
而Meta團隊研究科學家Aston Zhang在X上釋出的內容,也印證了被泄露的測試數據。

圖片來源:X
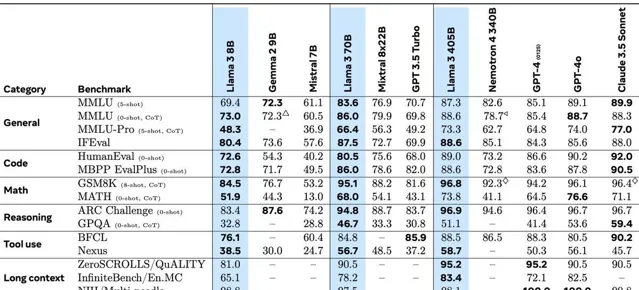
具體來看,Meta Llama 3.1-405B 在IFEval、GSM8K、ARC Challenge和Nexus等多項測試中均優於GPT-4o。但是,它在多項MMLU測試和GPQA測試等方面卻落後於 GPT-4o。另外,Llama 3.1的上下文視窗(context window)涵蓋128000個標記,比以前的Llama模型更大,大約相當於一本50頁書的長度。
圖片來源:X
但需要指出的是,值得註意的是,這些基準反映的是Llama 3.1基本模型的效能。這些模型的真正潛力可以透過指令調整來實作,而指令調整過程可以顯著提高這些模型的能力。即將推出的Llama 3.1模型的指令調整版本預計會產生更好的結果。
Llama 4已於6月開始訓練
盡管OpenAI即將推出的 GPT-5預計將具備先進的推理能力,可能會挑戰Llama 3.1在大模型領域的潛在領導地位,但Llama 3.1對標GPT-4o的強勁表現仍然彰顯了開源AI開發的力量和潛力。
要知道,對於專註於構建專業AI模型的開發人員來說,他們面臨的長期挑戰是獲取高品質的訓練數據。較小的專家模型(參數規模在10億~100億)通常利用「蒸餾技術」,需要利用較大模型的輸出來增強其訓練數據集,然而,使用來自OpenAI等閉源巨頭的此類數據受到嚴格限制,因此大大限制了商業套用。
而Llama 3.1-405B的推出意味著開發人員可以自由使用其「蒸餾」輸出來訓練小眾模型,從而大大加快專業領域的創新和部署周期。預計高效能、經過微調的模型的開發將激增,這些模型既強大又符合開源道德規範。
賓夕法尼亞大學華頓商學院副教授伊桑·莫利克(Ethan Mollick)寫道:「如果這些數據屬實,那麽可以說頂級AI模型將在本周開始免費向所有人開放。全球各地都可以使用相同的AI功能。這會很有趣。」
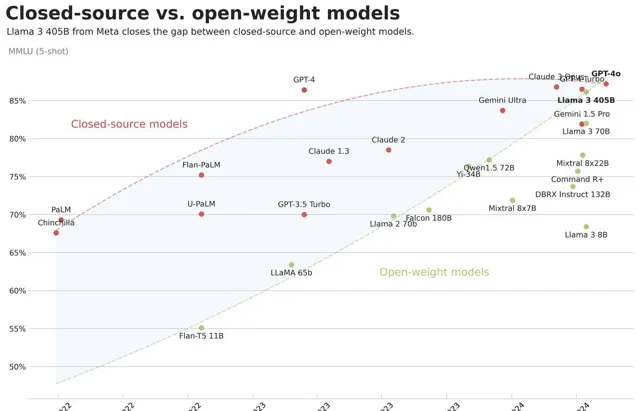
Llama 3.1-405B的開源,也證明開源模型與閉源模型的差距再次縮小了。
圖片來源:X
【每日經濟新聞】記者還註意到,除了廣受期待的Llama 3.1-405B外,外媒報道稱,Llama 4已於6月開始訓練,訓練封包括社交平台Facebook和Instagram使用者的公開貼文。而在開始之前,Mate已經向數據私密監管最嚴格的歐盟地區使用者發送超過20億條通知,提供了不同意把自己數據用於大模型訓練的選項。
據悉,Llama 4將包含文本、影像、視訊與音訊模態,Meta計劃將新模型套用在手機以及智慧眼鏡中。
每日經濟新聞











