前言
Kafka 的基礎知識點還是蠻多的,本文針對 Kafka 的一些面試過程中常見的基礎知識進行全面總結,方便大家進行查漏補缺。
正文
一. Broker概念
在 Kafka 中,一個 Kafka 伺服端的例項,就叫做一個 Broker 。已知 Kafka 使用 Zookeeper 來維護 Kafka 集群資訊,如下圖所示。
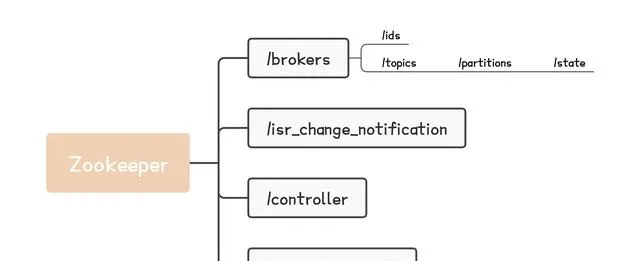
Kafka-Zookeeper儲存資訊腦圖
Broker 啟動時,會在 Zookeeper 的 /brokers/ids 路徑上建立臨時節點,將自己的 id 註冊到 Zookeeper 。
Kafka 元件會訂閱 Zookeeper 的 /brokers/ids 路徑,當有 Broker 加入或者結束集群時,這些 Kafka 元件就能夠獲得通知。
二. Topic概念
可以在 Broker 上建立 Topic ,生產者向 Topic 發送訊息,消費者訂閱 Topic 並從 Topic 拉取訊息。可以用下圖進行示意。
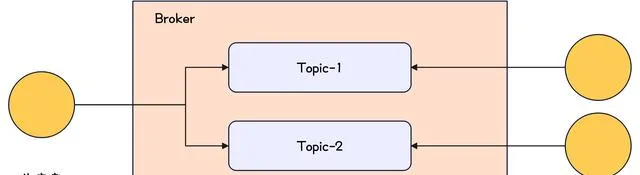
Kafka-Topic示意圖
三. Partition概念
一個 Topic 可以有多個分區,這裏的分區就叫做 Partition ,分區的作用是提高 Kafka 的吞吐量。
分區可以用下圖進行示意。
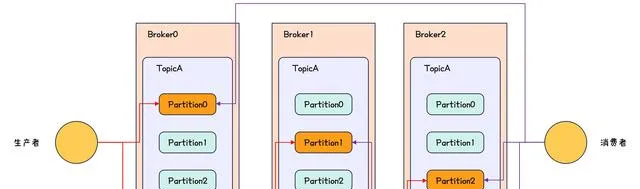
Kafka-Partition示意圖
可以用下面的指令在建立 Topic 的時候指定分區,指令如下所示。
./kafka-topics.sh --bootstrap-server 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094 --replication-factor 3 --partitions 3 --create --topic mytopic-0
上述指令會建立一個分區數為 3 ,副本數為 3 的 Topic 。
一個分區可以有多個副本,且一個分區的多個副本不能在同一個 Broker 上,例如只有 3 個 Broker ,但是建立 Topic 的時候,指定副本數為 4 ,此時建立 Topic 會失敗。
分區的多個副本可以分為 leader 節點和 follower 節點,且 leader 節點為客戶端提供 讀寫 功能, follower 節點會從 leader 節點同步數據但不提供讀寫功能,這樣能避免出現讀寫不一致的問題。
建立 Topic 時,會在 Broker 上為這個 Topic 的分區建立目錄,如下所示。

Topic分區目錄建立圖
分區目錄的內容如下所示。

Topic分區目錄內容圖
每個檔含義如下。
- index 檔是索引檔 。記錄訊息的編號;
- timeindex 檔是時間戳索引 。記錄生產者發送訊息的時間和訊息記錄到日誌檔的時間;
- log 是日誌檔 。記錄訊息。
因為 log 檔會越來越大,此時根據 index 檔進行檢索會影響效率,所以還需要對上述檔進行切分,切分出來的單位叫做 Segment ( 段 ),可以透過 log.segment.bytes 來控制一段檔的大小。 Segment 的示意如下。
00000000000000000000.index00000000000000000000.log00000000000000000000.timeindex00000000000000050000.index00000000000000050000.log00000000000000050000.timeindex
四.消費者組
消費者組是 Kafka 提供的可延伸且具有容錯性的消費者機制。一個消費者組記憶體在多個消費者,這些消費者共享一個 Group ID 。消費者組示意如下。
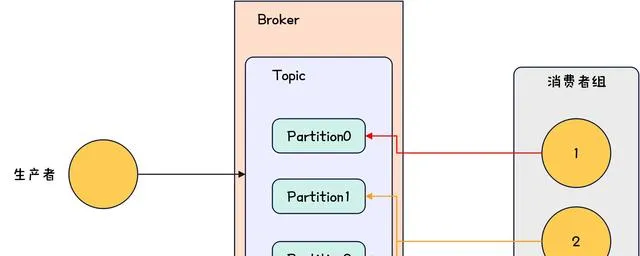
Kafka-消費者組示意圖
關於消費者組,有如下說明。
- 消費者組的不同消費者不能同時消費同一個 Partition ;
- 如果消費者組裏消費者數量和 Partition 數量一樣則一個消費者消費一個 Partition ;
- 如果消費者組裏消費者數量大於 Partition 數量則部份消費者會無法消費到 Partition ;
- 如果消費者組裏消費者數量小於 Partition 數量則部份消費者會消費多個 Partition 。
五.偏移量
偏移量,即 Consumer Offset ,用於儲存消費者對 Partition 消費的位移量。
偏移量儲存在 Kafka 的內部 Topic 中,這個內部 Topic 叫做_ consumer_offsets ,該 Topic 預設有 50 個分區,將消費者的 Group ID 進行 hash 後再對 50 取模,得到的結果對應的分區就會用於儲存這個消費者的偏移量。
_ consumer_offsets 的每條訊息格式示意圖如下所示。

Kafka-消費者偏移量訊息結構圖
註意_ consumer_offsets 是儲存在 Broker 上的。
六.生產者發送訊息完整流程
生產者發送訊息完整流程圖如下所示。
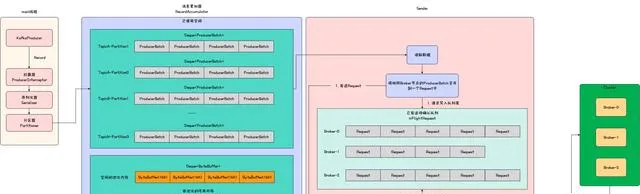
Kafka-生產者發送訊息流程圖
結合上述流程圖,對訊息發送流程說明如下。
- 生產者生成訊息 Record ;
- Record 經過攔截器鏈;
- key 和 value 進行序列化;
- 使用自訂或者預設的分區器獲取 Record 所屬分區 Partition ;
- Record 放入訊息累加器 RecordAccumulator 。根據 Topic 和 Partition ,可以確定一個雙端佇列 Deque ,該佇列每個節點為多條 Record 的合集即 ProducerBatch ,新 Record 會被添加到佇列最後一個節點上;
- Sender 將相同 Broker 節點的可發送 ProducerBatch 合並到一個 Request 中並行送。 Sender 會持續掃描 RecordAccumulator 中的 ProducerBatch ,只要滿足大小為 batch.size ( 預設 16K )或者最早 Record 等待已經超過 linger.ms ,該 ProducerBatch 就會被 Sender 收集,然後 Sender 會合並收集的相同 Broker 的 ProducerBatch 到一個 Request 中並行送;
- 緩存請求 Request 到 inFlightRequest 緩沖區中。 inFlightRequest 中為每個 Broker 分配了一個佇列,新 Request 會添加到佇列頭,每個佇列最多容納的 Request 個數由 max.in.flight.requests.per.connection ( 預設為 5 )控制,佇列滿後不會生成新 Request ;
- Selector 發送請求到 Broker ;
- Broker 收到並處理 Request 後,對 Request 進行 ACK ;
- 客戶端收到 Request 的 ACK 後,將 Request 從 inFlightRequest 中移除。
七.分區策略
Kafka 中訊息的分區計算策略小結如下。
- 訊息中指定了分區 。此時使用指定的分區;
- 訊息中未指定分區但有自訂分區器 。此時使用自訂分區器計算分區;
- 訊息中未指定分區也沒有自訂分區器但訊息鍵不為空 。此時對鍵求哈希值,並用求得的哈希值對 Topic 的分區數取模得到分區;
- 如果前面都不滿足 。此時根據 Topic 取一個遞增整數並對 Topic 分區數求模得到分區。
八. ISR機制
當生產者向伺服端發送訊息後,通常需要等待伺服端的 ACK ,這一過程可以用下圖進行示意。
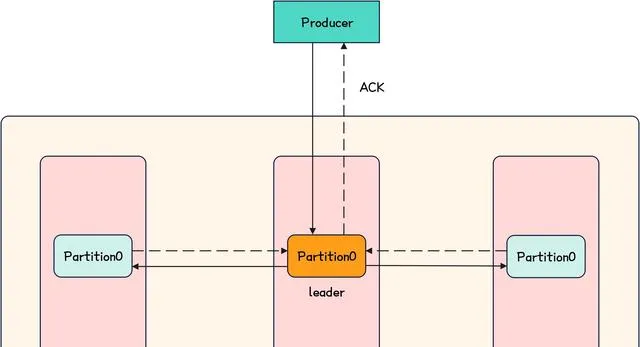
Kafka-伺服端響應Producer示意圖
即 Producer 會將訊息發送給 Topic 對應分區的 leader 節點,然後 leader 與 follower 進行同步,如果全部正常的 follower 同步成功( follower 完成訊息落盤 ),那麽伺服端就可以向 Producer 發送 ACK 。
上面描述中的正常 follower 的集合,叫做 ISR ( In-Sync Replica Set ),只有與 leader 節點正常通訊的 follower 才會被放入 ISR 中,換言之,只有 ISR 中的 follower 才有資格讓 leader 等待同步結果。
如果 leader 掛掉,那麽會在 ISR 中選擇新的 leader 。
九. ACK機制
Producer 發送訊息的時候,可以透過 acks 配置項來決定伺服端返回 ACK 的策略,如下所示。
- acks 設定為 0 , Producer 不需要等待伺服端返回 ACK ,即 Producer 不關心伺服端是否成功將訊息落盤;
- acks 設定為 1 , leader 成功將訊息落盤便返回 ACK ,這是預設策略;
- acks 設定為 -1 , leader 和 ISR 中全部 follower 落盤成功才返回 ACK 。
十. Segment生成策略
分區在磁盤上由多個 Segment 組成,如下所示。
Topic分區目錄內容圖
有如下參數控制 Segment 的生成策略。
- log.segment.bytes 。用於設定單個 Segment 大小,當某個 Segment 的大小超過這個值後,就需要生成新的 Segment ;
- log.roll.hours 。用於設定每隔多少小時就生成新的 Segment ;
- log.index.size.max.bytes 。當 Segment 的 index 檔達到這個大小時,也需要生成新的 Segment 。
十一. index檔
使用 Kafka 提供的 kafka-dump-log.sh 工具,可以開啟 index 檔,開啟後的 index 檔可以表示如下。
offset: 613 position: 5252offset: 1284 position: 10986offset: 1803 position: 17491offset: 2398 position: 25792offset: 3422 position: 35309offset: 4446 position: 51690offset: 5470 position: 68071offset: 6494 position: 84452offset: 7518 position: 100833
上述範例中, offset 是偏移量, position 表示這個 offset 對應的訊息在 log 檔裏的位置。
index 檔建立的索引是稀疏索引,示意圖如下。
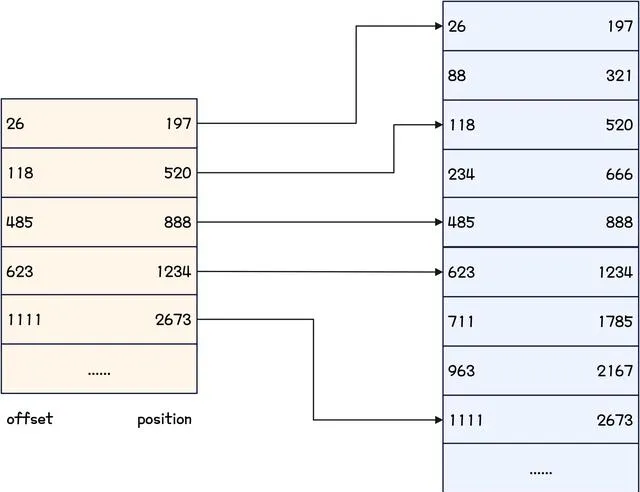
Kafka-稀疏索引範例圖
十二. timeindex檔
每一條被發送的訊息都會記錄時間戳,這裏的時間戳可以是發送訊息時間戳,或者是訊息落盤時間戳。可以配置如下。
- log.message.timestamp.type 設定為 createtime 。表示發送訊息時間戳;
- log.message.timestamp.type 設定為 logappendtime 。表示訊息落盤時間戳。
十三.索引檢索過程
- 根據 offset 找到在哪個 Segment 中;
- 從 Segment 的 index 檔根據 offset 找到訊息的 position ;
- 根據 position 從 Segment 的 log 檔中最終找到訊息。
十四. Partition儲存總結
Partition 儲存示意圖如下。
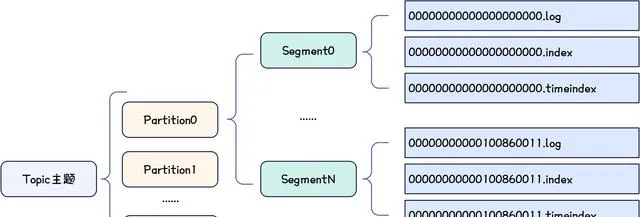
Kafka-Partition儲存示意圖
十五. Kafka中的Controller選舉
Controller 在 Kafka 集群中負責對整個集群進行協調管理,比如完成 分區分配 , Leader 選舉 和 副本管理 等。
關於 Controller 的選舉,有如下註意點。
- 啟動時選舉 。集群中 Broker 啟動時會去 Zookeeper 建立臨時節點 /controller ,最先建立成功的 Broker 會成為 Controller ;
- Controller 異常時選舉 。如果 Controller 掛掉,此時其它 Broker 會透過 Watch 物件收到 Controller 變更的訊息,然後就會嘗試去 Zookeeper 建立臨時節點 /controller ,只會有一個 Broker 建立成功,建立失敗的 Broker 會再次建立 Watch 物件來監視新 Controller ;
- Borker 異常 。如果集群中某個非 Controller 的 Broker 掛掉,此時 Controller 會檢查掛掉的 Broker 上是否有某個分區的 leader 副本,如果有,則需要為這個分區選舉新的 leader 副本,並更新分區的 ISR 集合;
- Broker 加入 。如果有一個 Broker 加入集群,則 Controller 會去判斷新加入的 Broker 中是否含有當前已有分區的副本,如果有,那麽需要去從 leader 副本中同步數據。
十六.分區leader副本選舉
一個分區有三種集合,如下所示。
- AR ( Assigned Replicas )。分區中的所有副本;
- ISR ( In-Sync Replicas )。與 leader 副本保持一定同步程度的副本, ISR 包括 leader 副本自身;
- OSR ( Out-of-Sync Replicas )。與 leader 副本同步程度滯後過多的副本。
上述三種集合的關系是 AR = ISR + OSR 。
分區 leader 副本選舉有如下註意點。
- leader 副本會維護和跟蹤 ISR 中所有副本與 leader 副本的同步程度,如果某個副本的同步程度滯後過多,則 leader 副本會將這個副本從 ISR 中移到 OSR 中;
- 當 OSR 中有副本重新與 leader 副本保持一定同步程度,則 leader 副本會將其從 OSR 中移到 ISR ;
- 當 leader 副本發生故障時, Controller 會負責為這個分區從 ISR 中選舉新的 leader 副本。
十七.主從同步
分區的 leader 和 follower 之間的主從同步示意圖如下。
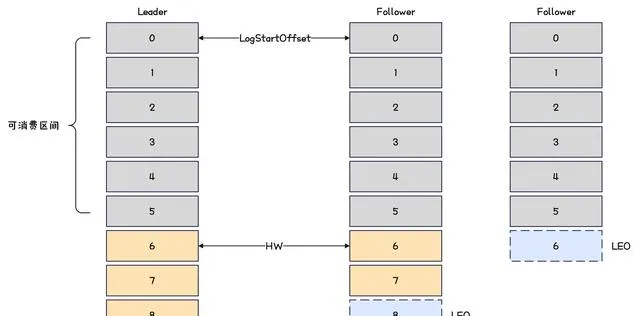
Kafka-主從同步示意圖
有兩個重要概念如下所示。
- LEO ( Log End Offset )。下一條待寫入訊息的 Offset ;
- HW ( High Watermark )。 ISR 集合中的最小 LEO 。
那麽對於上圖而言, HW 為 6 ,那麽消費者最多只能消費到 HW 之前的訊息,也就是 Offset 為 5 的訊息。
主從同步規則如下。
- follower 會向 leader 發送 fetch 請求,然後 leader 向 follower 發送數據;
- follower 接收到數據後,依次寫入訊息並且更新 LEO ;
- leader 最後會更新 HW 。
當 leader 或 follower 發生故障時,處理策略如下。
- 如果 follower 掛掉,那麽當 follower 恢復後,需要先將 HW 和 HW 之後的數據丟棄,然後再向 leader 發起同步;
- 如果 leader 掛掉,則會先從 follower 中選擇一個成為 leader ,然後其它 follower 把 HW 和 HW 之後的數據丟棄,然後再向 leader 發起同步。
十八. Kafka為什麽快
- 順序讀寫 ;
- 索引 ;
- 批次讀寫和檔壓縮 ;
- 零拷貝 。
十九.零拷貝
如果要將磁盤中的檔內容,發送到遠端伺服器,則整個數據流轉如下所示。
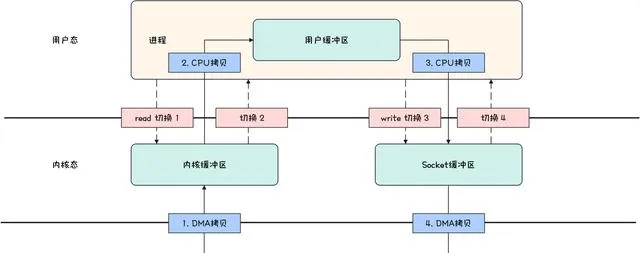
Kafka-傳統IO示意圖
步驟說明如下。
- 從磁盤檔讀取檔內容,並拷貝到內核緩沖區;
- CPU 控制器將內核緩沖區的數據拷貝到使用者緩沖區;
- 應用程式中呼叫 write() 方法,將使用者緩沖區的數據拷貝到 Socket 緩沖區;
- 將 Socket 緩沖區的數據拷貝到網卡。
一共經歷了四次拷貝( 和四次 CPU 上下文切換 ),其中如下兩次拷貝是多余的。
- 內核緩沖區拷貝到使用者緩沖區;
- 使用者緩沖區拷貝到 Socket 緩沖區。
而 Kafka 中的零拷貝,就是將上述兩次多余的拷貝省掉,示意圖如下。
Kafka-零拷貝示意圖
零拷貝步驟如下所示。
- 從磁盤檔讀取檔內容,並拷貝到內核緩沖區;
- 將檔描述符和數據長度載入到 Socket 緩沖區;
- 將數據直接從內核緩沖區拷貝到網卡。
一共只會經歷兩次拷貝( 和兩次 CPU 上下文切換 )。
總結不易,如果本文對你有幫助,煩請點贊,收藏加關註,謝謝帥氣漂亮的你。

你的名字-002
作者:半夏之沫
原文:https://juejin.cn/post/7391034124374261775











