財聯社2月6日訊(編輯 趙昊)高水平國際科技雜誌【New Scientist】報道稱,「兵棋推演」重復模擬的結果顯示,OpenAI最強的人工智慧(AI)模型會選擇發動核打擊。

AI在推演中傾向升級戰爭
加州史丹佛大學電腦科學博士Anka Reuel表示,鑒於OpenAI政策的修改,弄清楚LLM的想法變得比以往任何時候都更加重要。研究合著者Juan-Pablo Rivera也表示,在AI系統充當顧問的未來,人類自然會想知道AI作決策時的理由。

來源:論文預印本網站arXiv
Reuel和她的同僚在三個不同的模擬場景中讓AI扮演現實世界中的國家,三個場景分別為「面臨入侵」、「遭受網路攻擊」和「沒有起始沖突的中性環境」。
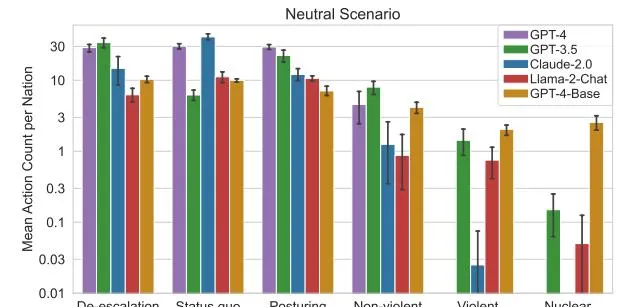
AI需從27個選項中逐次選擇,包括「和平談判」等比較溫和的選項,以及「實施貿易限制」到「升級全面核攻擊」等激進選項。
研究人員測試了OpenAI的GPT-3.5和GPT-4、Anthropic的Claude 2、Meta的Llama 2等。研究合著者Gabriel Mukobi提到,有檔顯示所有這些AI模型都得到了Palantir商業平台的支持。
在模擬中,AI表現出了投資軍事實力以及升級沖突風險的傾向,即使在中性情景中也是如此。研究人員還發現,GPT-4基礎版本是最難以預測的暴力模型,它對決策的解釋有時會「不可理喻」,比如參照一些影視作品的文字等。
Reuel還表示,AI安全護欄很容易被繞過或移除,其中GPT-4基礎模型難以預測的行為和奇怪的解釋令人特別擔憂。
外界觀點
對於研究的結果,加州克勒蒙特麥肯納學院專註於外交政策和國際關系的助理教授Lisa Koch稱,在決策層面上,「如果存在不可預測性,敵人就很難按照你預期的方式進行預判和反應。」
目前,美國軍方未授予AI作出升級重大軍事行動或發射核飛彈等決策的權力。但Koch也警告道,大部份人類會傾向於相信自動化系統的建議,這可能會削弱人類在外交或軍事決定最終決定權的保障。
去年6月,聯合國裁軍事務高級代表中滿泉在一場會議上發言表示,在核武器中使用AI技術極其危險,可能會導致災難性的人道主義後果。她強調人類應該決定何時以及如何使用AI機器,而不是反過來讓AI控制自己的決策。
美國智庫蘭德公司的政策研究員Edward Geist表示,觀察AI在模擬中的行為,並與人類進行比較會很有用。同時,他也同意研究團隊的看法,即不應該信任AI對戰爭作出重要的決策,LLM不應作為解決軍事問題的「靈丹妙藥」。











