
圖片來源@視覺中國
文 | 讀懂財經
在2022年的春節,OpenAI推出的ChatGPT快速引爆了資本圈與AI圈,至此拉開了AI大航海的序幕。
到了今年,類似的故事也在發生。2月16日淩晨,在沒有任何預兆和訊息透露的情況下,OpenAI 突然釋出了自己的第一個文生視訊模型:Sora。很顯然,這給了整個AI行業一點小小的震撼。
相比市面上現有的AI視訊模型,Sora展示出了遠超預期的能力:不僅直接將視訊生成的時長一次性提升了15倍,在視訊內容的穩定性上也有不小的提升。更重要的是,在公布的演示視訊裏,Sora展示了對物理世界部份規律的理解,這是過去文生視訊模型一大痛點。
隨著Sora的釋出,另一個有趣的事情是,為什麽總是OpenAI?要知道,在Sora釋出前,探索AI視訊模型的公司並不少,包括大眾熟知的Runway、Pika,也取得了不錯的進展。但OpenAI依然實作了降維打擊。
這是一場典型的OpenAI式勝利:聚焦AGI這一終極目標,不拘泥於具體場景,透過Scaling Law,將生成式AI的「魔法」從文本延伸到了視訊和現實世界。
在這個過程中,AI所創造的虛擬世界與現實世界的邊界逐漸模糊,OpenAI距離AGI的目標也將越來越近。
01 降維打擊的Sora
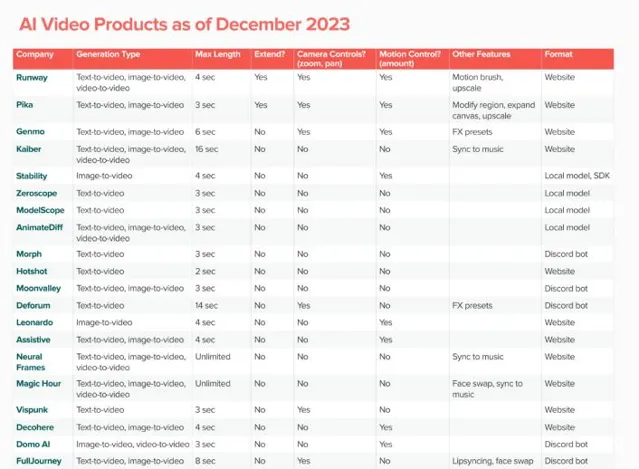
在Sora釋出前,大眾對文生視訊方案並不陌生。根據知名投資機構a16z此前的統計,截至2024年底,市場上共有21個公開的AI視訊模型,包括大眾熟知的Runway、Pika、Genmo以及Stable Video Diffusion等等。
那麽相比現有的AI視訊模型,Sora所展示出來的優勢,主要集中在以下幾點:
一是視訊長度的巨大提升。Sora生成長達1分鐘的超長視訊,這樣內容長度遠遠高於市面上的所有AI視訊模型。
根據a16z統計,現有的AI視訊模型制作的視訊長度大都在10秒以內,像此前大熱的Runway Gen 2、Pika,其制作的視訊長度分別只有4秒和3秒。60秒的視訊長度,也意味著其基本達到了抖音等短視訊平台的內容要求。
二是視訊內容的穩定性。對AI視訊來說,它們基本上是生成幀,在幀與幀之間創造時間上連貫的動畫。但由於它們對三維空間以及物體應如何互動沒有內在的理解,導致AI視訊往往會出現人物扭曲和變形。
比如說,這樣的情況經常會出現:片段的前半部份,一個人在在街道上行走,後半部份卻融化在地面上——模型沒有「堅硬」表面的概念。由於缺乏場景的三維概念,從不同角度生成相同片段也很困難。
但Sora的獨特之處在於,其所制作的60秒視訊不僅能夠實作一鏡到底,視訊中的女主角、背景人物,都達到了驚人的一致性,各種鏡頭隨意切換,人物都是保持了極高的穩定性。以下是Sora釋出的演示視訊:
Prompt: 一位時尚女性走在充滿溫暖霓虹燈和動畫城市標牌的東京街道上。她穿著黑色皮夾克、紅色長裙和黑色靴子,拎著黑色錢包。她戴著太陽鏡,塗著紅色口紅。她走路自信又隨意。街道潮濕且反光,在彩色燈光的照射下形成鏡面效果。許多行人走來走去。
三是深刻的語言理解能力使Sora能夠精準地辨識使用者的指令,從而在生成的視訊中呈現出豐富的表情和生動的情感。這種深層次的理解不僅局限於簡單的命令,Sora還理解這些東西在物理世界中的存在方式,甚至能夠實作相當多的物理互動。
舉個例子,就拿Sora對於毛發紋理物理特性的理解來說,當年皮克斯在制作【怪物公司】主角毛怪時,為能呈現其毛發柔軟波動的質感,技術團隊為此直接連肝幾個月,才開發出仿真230萬根毛發飄動的軟體程式。而如今Sora在沒有人教的情況下,輕而易舉地就實作了。
「它學會了關於 3D 幾何形狀和一致性的知識,」計畫的研究科學家Tim Brooks表示。「這並非我們預先設定的——它完全是透過觀察大量數據自然而然地學會的。」
毫無疑問,相比於其他「玩具級」的視訊生成AI,Sora在AI視訊領域實作了降維打擊。
02 把視覺數據統一起來
從技術層面來說,圖片生成和視訊生成的底層技術框架較為相似,主要包括迴圈神經網路、生成對抗網路(generative adversarial networks,GAN)、自回歸模型(autoregressive transformers)、擴散模型(diffusion models)。
與Runway、Pika等主流AI視訊聚焦於擴散模型不同,Sora采取了一個新的架構——Diffusion transformer 模型。正如它的名字一樣,這個模型融合了擴散模型與自回歸模型的雙重特性。Diffusion transformer 架構由加利福尼亞大學柏克萊分校的 William Peebles 與紐約大學的 Saining Xie 在 2023 年提出。
在這個新架構中,OpenAI沿用了此前大語言模型的思路,提出了一種用 Patch(視覺修補程式)作為視訊數據來訓練視訊模型的方式,是一個低維空間下統一的表達單位,有點像文本形式下的Token。LLM把所有的文本、符號、程式碼都抽象為Token,Sora把圖片、視訊都抽象為Patch。
簡單來說,OpenAI會把視訊和圖片切成很多小塊,就像是拼圖的每一片一樣。這些小塊就是Patch,每一個修補程式就像是電腦學習時用的小卡片,每張卡片上都有一點點資訊。
透過這種方式,OpenAI能夠把視訊壓縮到一個低維空間,然後透過擴散模型模擬物理過程中的擴散現象來生成內容數據,從一個充滿隨機雜訊的視訊幀,逐漸變成一個清晰、連貫的視訊場景。整個過程有點像是把一張模糊的照片變得清晰。
按OpenAI的說法,將視覺數據進行統一表示這種做法的好處有兩點:
第一,采樣的靈活性。Sora 可以采樣寬屏 1920x1080p 視訊、垂直 1080x1920 視訊以及介於兩者之間的所有視訊(如下列3個視訊)。這使得 Sora 可以直接以其原生寬高比為不同裝置建立內容,快速以較低尺寸制作原型內容。
第二,取景與構圖效果的改善。根據經驗發現,以原始寬高比對視訊進行訓練可以改善構圖和取景。比如,常見的將所有訓練視訊裁剪為正方形的模型,有時會生成僅部份可見主體的視訊。相比之下,Sora 的視訊取景有所改善。
為什麽OpenAI能夠想到將視覺數據進行統一表示的方法?除了技術原因外,也很大程度上得益於OpenAI與Pika、Runway,對AI視訊生成模型的認知差異。
03 世界模型,透過AGI的道路
在Sora釋出前,AI 視訊生成往往被人看作是AI套用率先垂直落地的場景之一,因為這很容易讓人想到顛覆短視訊、影視/廣告行業。
正因為如此,幾乎所有的 AI 視訊生成公司都陷入了同質化競爭:過多關註更高畫質、更高成功率、更低成本,而非更大時長的世界模型。你能看到,Pika、Runway做視訊的時長都不超過 4s 範圍,雖然可以做到畫面足夠優秀,但物體動態運動表現不佳。
但OpenAI對AI視訊生成的探索更像是沿著另一條路線前進:透過世界模型,打通虛擬世界與現實世界的邊界,實作真正AGI。在OpenAI公布的Sora技術報告裏,有這樣一句話:
「我們相信Sora今天展現出來的能力,證明了視訊模型的持續擴充套件(Scaling)是開發物理和數位世界(包含了生活在其中的物體、動物和人)模擬器的一條有希望的路。」
世界模型,最早是由Meta 首席科學家楊立昆(Yann LeCun)在2023 年 6 月提出的概念,大致意思是可以理解為是要對真實的物理世界進行建模,讓機器像人類一樣,對世界有一個全面而準確的認知,尤其是理解當下物理世界存在的諸多自然規律。
換言之,OpenAI更願意把Sora 視為理解和模擬現實世界的模型基礎,視為 AGI 的一個重要裏程碑,而不是AI套用落地的場景。這意味著,相比其他玩家,OpenAI永遠用比問題更高一維度的視角看待問題。
在實際情況裏,這會讓解決問題變得更加容易。正如愛因史坦說過,我們不能用創造問題時的思維來解決問題。從這個角度上說,也能夠解釋為什麽OpenAI總能時不時給行業來點小震撼。
盡管從目前看,AI生成的視訊仍然有著各種各樣的問題,比如模型難以準確模擬復雜場景的物理,也可能無法理解因果關系的具體例項,但不可否認的是,至少Sora開始理解部份物理世界的規則,讓眼見不再為實,基於物理規則所搭建的世界真實性遇到前所未有挑戰。
當大模型從過去文本中學習的模式,開始轉為向視訊和真實世界學習。隨著Scaling Law的邏輯在各個領域湧現,或許賽博世界與物理世界的邊界將變得更加模糊。











