潮新聞客戶端 記者 朱高祥
當地時間5月13日22:00,OpenAI舉行了名為「春季更新」的線上釋出會,宣布推出GPT-4的升級款模型GPT-4o。
這場釋出會堪稱簡陋,前後持續不到半個小時,既沒有大屏PPT,明星高管Sam Altman也沒有出現,核心環節就是由技術長Mira Murati帶著兩位員工一起在現場展示新模型。
但這場釋出會依舊驚艷,正如GPT-4o中的「o」(omn,意為全能),GPT-4o長出了「眼睛」「嘴巴」,變得全知全能。不少網友驚呼,電影照進現實,未來套用充滿無限想象空間。
OpenAI「春季更新」釋出會。來源:OpenAI官方社交媒體
記者實測:更為強大的GPT
5月14日,GPT-4o釋出後,OpenAI的執行長Sam Altman在社交媒體上發帖,僅有一個字「her」。

圖片來源:Sam Altman社交媒體
【her】是一部科幻電影的名字,影片中人工智慧系統「薩曼莎」不僅能夠幫助男主狄奧多完美地處理好工作,而且還是朵「解語花」。她擁有性感的聲線,細膩的情感,並且風趣幽默,她能夠和狄奧多進行深度交流。「her」也是很多人看到GPT-4o演示之後的最大感受,它似乎變得跟真人一樣了。
5月14日,為了驗證GPT-4o的強大,潮新聞記者開啟ChatGPT的app進行了實測。記者發現,目前要使用GPT-4o,需要以每月20美元的價格開通「ChatGPT Plus」。
圖片來源:OpenAI官網
記者註意到,GPT-4o與GPT-3.5最明顯的不同在於界面,GPT-3.5僅支持文字與語音輸入,但GPT-4o可以輸入文字、語音、圖片以及檔等。
當記者詢問GPT-4o可以做什麽?它回答稱可以「回答問題」「語言轉譯」「寫作和編輯」「提供建議」「數學和編程」「數據分析」「建立影像」「即時資訊查詢」等。
對於「即時資訊查詢」,記者分別用「杭州今日天氣」向GPT-3.5、GPT-4與GPT-4o進行了詢問,只有GPT-4與GPT-4o可以回答。
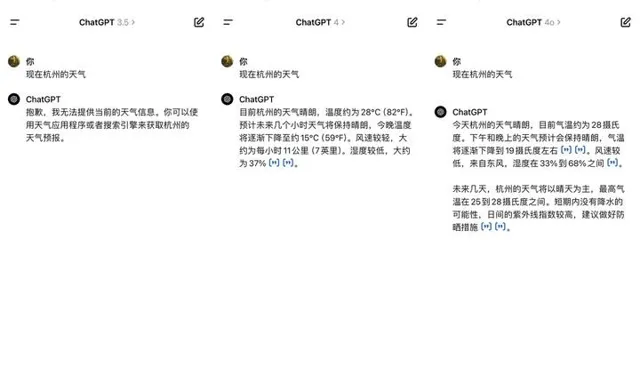
記者用「杭州天氣」詢問三個大模型
記者拍攝了一張辦公桌照片讓GPT-4與GPT-4o進行描述,這兩個大模型都可以在幾秒鐘之內給出解讀。但對比來看,GPT-4o總結得更為詳細,也更為全面。

記者用照片測試GPT-4與GPT-4o
另外針對數據分析能力,記者利用在深交所下載的14頁的「萬科2024年第一季度報告」讓GPT-4與GPT-4o進行分析,兩者均能對財務狀況、業務進展等要素進行快速總結。但對比來看,GPT-4o能力更強,分析得也更為全面透徹。
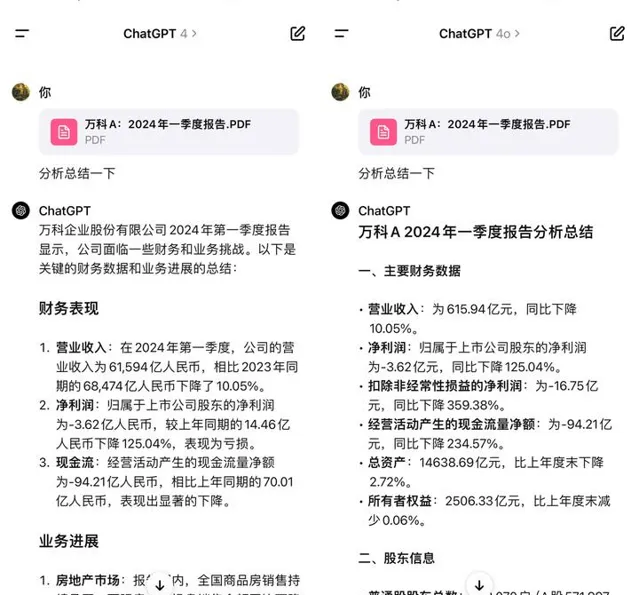
記者用萬科2024年第一季度報告檢測GPT-4與GPT-4o
值得註意的是,與釋出會上的演示不同,目前ChatGPT僅接入GPT-4o有限功能,尚不可以利用網路攝影機對現實場景分析,也不能在與其語音溝通時即時打斷。
不過,OpenAI已經宣布推出一款適用於macOS的桌面級套用,使用鍵盤快捷鍵就可向ChatGPT提問。使用者可透過電腦與ChatGPT語音對話,GPT-4o的新音訊和視訊功能後續將推出。值得註意的是,此次OpenAI並未釋出關於新模型的論文或技術文件。
長出「眼睛」和「嘴巴」的GPT,帶來什麽想象?
在釋出會上,OpenAI現場展示了和ChatGPT的若幹互動,包括:即時對話互動、語音多樣化(應使用者需求使用不同情緒、語調等)、視訊指導做題、視訊辨識環境和人(包括人的情緒)、以桌面套用形式輔助編程、即時轉譯等。

釋出會上,利用GPT-4o進行視訊指導做題。圖片來源:釋出會視訊截圖
OpenAI同時還放出了預先錄制的展示樣例若幹,包括:兩個GPT-4o交流和對唱、唱搖籃曲、線上會議套用、毒舌諷刺、視訊識物並給出西班牙語單詞、幫助面試準備、和狗互動等。

演示視訊中與狗互動。圖片來源:OpenAI官網
在所有的演示當中,最讓人驚訝的還是視訊對話:使用者開啟網路攝影機,讓ChatGPT「看」到當下,並進行互動。
用前置鏡頭自拍,ChatGPT可以辨識使用者的情緒,如「看起來很開心,甚至可以說是興奮的」,還能從使用者背後的畫面判斷其身處的環境,如「看起來你在一個攝影棚中,背後有一些燈光,你的胸前還別著麥克風,可能在錄制視訊之類的」。當有另一個人進入鏡頭並且做鬼臉的時候,ChatGPT也準確指出了這一「不太尋常」的情況,並加以描述。

圖片來源:OpenAI官網
用後置鏡頭,ChatGPT就可以和使用者共享視角。如在語言學習的過程中,開啟網路攝影機讓ChatGPT用某種語言說出物品的名稱。或者可以為視障使用者提供指引,告訴使用者「來了一輛計程車,現在招手吧」。

圖片來源:OpenAI官網
浙江大學人工智慧研究所所長吳飛告訴潮新聞記者,GPT-4o可以像「一個人」一樣即時互動,是最讓人印象深刻的地方。
「自然語言互動也是OpenAI一直以來的理念,就是讓人工智慧像人一樣能夠交流。」吳飛說,在釋出會上可以看到,與GPT-4o進行交流的時候,你不覺得對方是一個機器,就覺得對方是一個人,互動顯得非常自然。
吳飛分析稱,這些驚艷的產品表現,根本上源自於GPT-4o多模態大模型的技術進步,是跨文本、視覺和音訊端到端地訓練了一個新模型。

圖片來源:OpenAI官網
OpenAI稱這是其突破深度學習界限的最新舉措。目前,GPT-4o可以在短至232毫秒、平均320毫秒的時間內響應音訊輸入,與人類的響應時間相似。
吳飛認為,快速發展的多模態大模型給未來套用帶來了豐富的想象空間。比如,也許不久的將來大模型不再僅僅是一個聊天機器人,而是將成為超級私人助手。不僅在工作上,在出遊、訂餐等生活的方方面面,大模型都可以快速地客製化生成使用者所需的答案。
另外,GPT-4o對周圍環境的即時解讀,為視障使用者提供了更多方便,出行也將變得更為容易。
「轉載請註明出處」











