
人工智慧:GPU如何塑造計算與AI領域的變革
在人工智慧的時代,一位默默無聞的英雄正在改變數據處理的格局,那就是圖形處理單元(GPU)。即使你不是科技從業者,作為遊戲愛好者,你也可能體會到GPU在提升遊戲體驗方面的強大作用。如今,NVIDIA憑借其強大的GPU技術在科技界占有一席之地。這些處理器可以同時進行成千上萬的操作,在訓練和執行大型語言模型(LLM)以及各種AI演算法中發揮著重要角色。值得關註的是,GPU究竟是什麽?它是如何運作的?又為何對人工智慧如此重要?
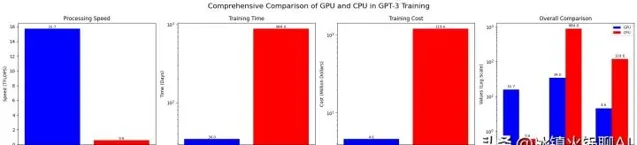
盡管GPU在處理復雜計算上表現出眾,我們依然需要它們來訓練大型語言模型。為了更好地理解GPU的強大之處,我們來看看一個實際案例:訓練GPT-3這一先進語言模型,大約需要34天的時間。如果是使用傳統的CPU,時間會更漫長,你能想象大約要多久嗎?(答案是無比久!)

作為一名人工智慧領域的研究者,我決定深入探討GPU對AI的影響,並與大家分享我的發現。請隨我一起解答這些問題,探索這些小矽片如何在重塑人工智慧的未來。
GPU的歷史與AI的結合


在GPU普及之前,AI模型主要是透過CPU運算。使用CPU的方法不僅浪費電力,還存在時間上的巨大消耗。CPU核心數量有限,無法高效地處理大型復雜模型。為此,GPU作為新型芯片應運而生。隨著AI模型的日益復雜,對平行計算的需求顯著增加,研究者們意識到GPU憑借其獨特的並列架構和數千個處理核心,可以更勝於CPU。

進入2000年代後期,利用GPU來加速AI模型的訓練已成為一種趨勢,結果顯示這些芯片能極大地縮短訓練時間。但最基本的問題依然存在,GPU與CPU的區別到底在哪裏,為什麽GPU在AI領域表現更為優異?

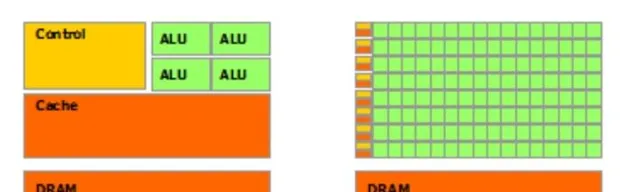
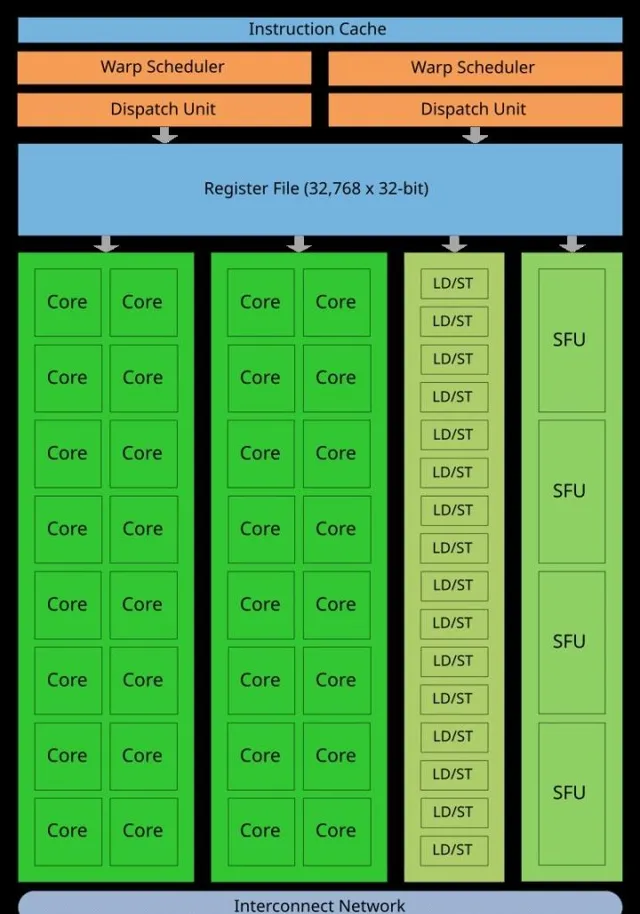
兩者之間的差異,首先體現在設計上。CPU(中央處理器)和GPU(圖形處理器)都是電腦系統的核心組成部份,但二者被設計的初衷截然不同。CPU適合處理復雜而多變的任務,通常核心數量在2到16之間,專註於順序處理。而GPU則擁有更多的小型核心,通常在數千個左右,善於並列處理任務。因此,GPU能夠高效地執行多項任務,尤其在圖形渲染和科學計算中表現出色。
為深入理解GPU和CPU的差異,以下數據或許能揭示一二。如果我們以訓練GPT-3為例,該模型的訓練需要10,000個NVIDIA V100 GPU,並且大約耗時34天。這一過程的成本約為460萬美元,而整個計算量大約為3.14E23次浮點運算。相對來看,一個NVIDIA V100 GPU每秒能執行約15.7萬億次浮點運算,而CPU的速度則低得多。在這情況下,若換用CPU進行訓練,所需時間幾乎會翻倍,達到884天,訓練成本更是可能膨脹至約1.2億美元。
GPU的演變與創新
圖形處理領域的發展起源於20世紀80年代。1986年,德州儀器推出了首批可編程圖形處理器,隨後的1999年,3Dlabs推出了專門用於3D渲染的GPU,成為行業裏程碑。進入21世紀後,NVIDIA不斷推出新產品,使GPU逐漸從圖形領域擴充套件至通用計算。2006年,NVIDIA釋出了CUDA平行計算平台,改變了科研和數據處理的遊戲規則。
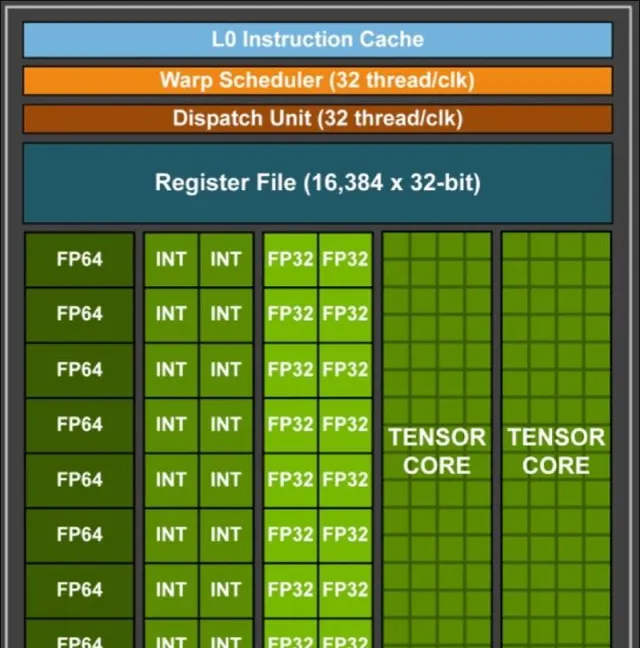
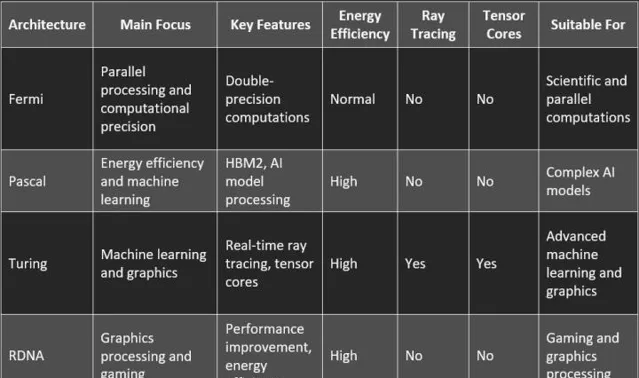
伴隨著計算技術的進步,NVIDIA在2010年代推出了以Fermi架構為基礎的GeForce 400系列,進一步提升了AI計算的處理速度。之後的每一次升級,都是在不斷向更高效、大規模處理能力邁進。輝達的Blackwell架構就涵蓋了2080億個晶體管,既確保了出色的處理能力,又提升了AI模型的訓練效率。
結語
本文探討了GPU在現代計算、特別是在AI領域的重要性。隨著處理能力的提升,像OpenAI的o1模型等的效能也大幅增長。GPU的未來將透過神經形態芯片的發展進一步擴充套件智慧機器的潛力,而深度學習計算的需求也將促使新的創新不斷湧現。隨著每一次技術的叠代,我們正在一步步接近智慧機器像人類一樣學習和推理的未來。











