編輯:編輯部
【新智元導讀】 這幾天的維也納,上演了一場AI圈的狂歡。在ICLR 2024上,圖靈巨頭LeCun、Bengio紛紛現身,直接讓現場擠爆,變成追星現場。
這幾天,AI屆的盛會——ICLR在維也納舉辦。
OpenAI、Meta、谷歌、智譜AI等世界前沿AI科技企業齊聚一堂。
現場名流雲集,星光耀眼,走幾步就能偶遇一位發過顛覆性paper的大咖。
毫無意外地,ICLR 2024展廳也變成了追星現場。熱鬧的氣氛,快把屋頂掀翻了。

現場追星圖靈巨頭
圖靈三巨頭中的著名「e人」LeCun,提前就在X上大方公布出自己的行程,滿懷期待地等著和粉絲們相見了。

在評論區,不僅有粉絲激動打卡,甚至還有準備現場遞簡歷的。
粉絲們果然不虛此行,在現場,LeCun口若懸河地講解,熱情的觀眾們在周圍形成密實的包圍圈。


論文地址:https://arxiv.org/abs/2305.19523

論文地址:https://arxiv.org/abs/2311.12983
另一位圖靈巨頭Yoshua Bengio,也顯示了自己的超高人氣。
現場觀眾總結道:「一個人真的需要在他的領域中做到獨一無二,才能讓他的會議室外排起如此長的隊伍!」

此前LeCun和Hinton都對此發表過言辭激烈的意見,Bengio的態度似乎一直比較模糊,迫不及待想知道他對於AGI是什麽看法了。在即將到來的5月11日,他就會在一場關於AGI的Workshop中發表演講。
值得一提的是,Bengio團隊也在今年的ICLR上獲得了傑出論文榮譽提名。


論文地址:https://openreview.net/pdf?id=Ouj6p4ca60
谷歌Meta隔壁,智譜AI也在
現場,谷歌開源模型Gema、機器人智慧體背後框架Robotics Transformers,以及其他開創性的研究一並呈現。
緊挨著Meta和谷歌,展廳中間有一家非常亮眼的公司——智譜AI。
現場的童鞋正為大家介紹GLM-4、ChatGLM等一系列研究成果。

這一系列展示,引起了眾多國外學者的圍觀。
現場的近兩千名與會嘉賓和學者,認真聽了GLM大模型技術團隊的介紹。
介紹內容包括了GLM系列大模型的多項前沿研究成果,涵蓋數學、文生圖、影像理解、視覺UI理解、Agent智慧體等領域。
在現場,大家熱烈討論起了對Scaling Law的看法。而GLM團隊,對此也有獨到見解——
「相比模型大小或訓練計算量,智慧湧現和預訓練損失有更加緊密的聯系。」
比如,著名的OpenAI 996研究員Jason Wei,認真讀過智譜AI這篇講預訓練損失的論文後,表示十分贊嘆。
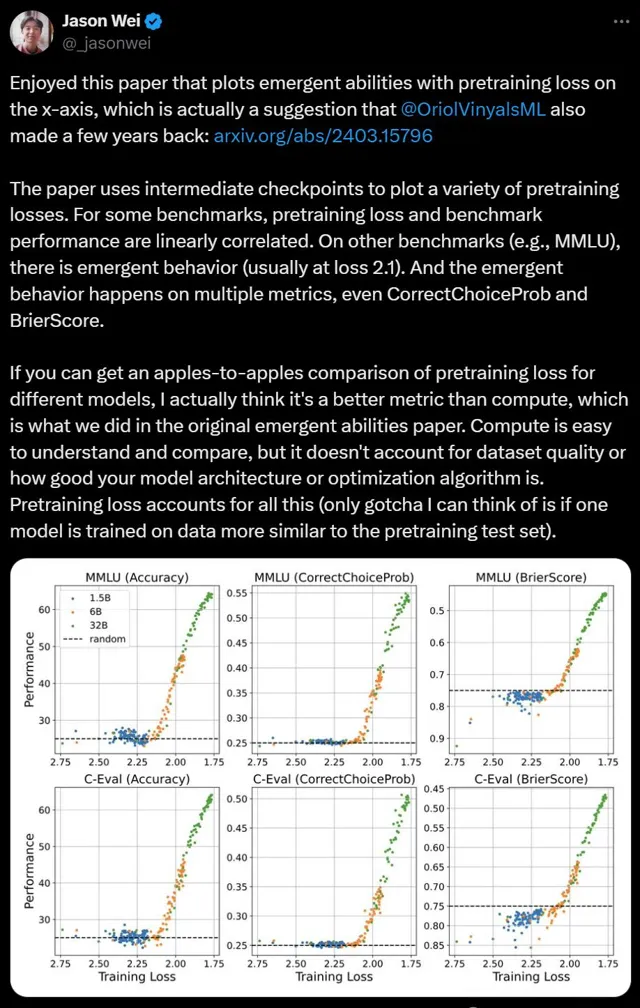
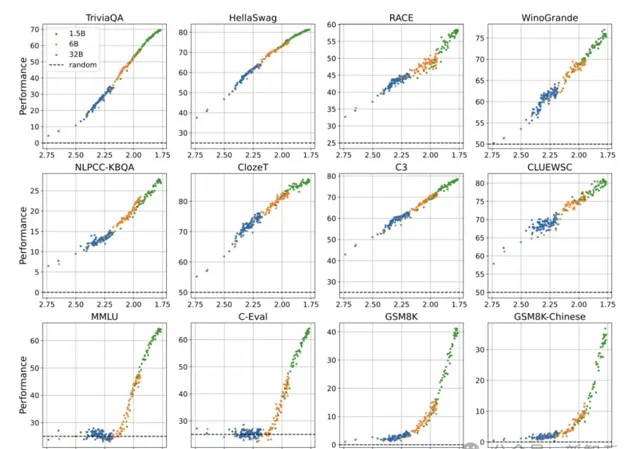
論文中,團隊透過訓練30+個不同參數和數據規模LLM,評估了其在12個中英文數據集上的表現。

論文地址:https://arxiv.org/abs/2403.15796
結果觀察到,只有當 預訓練損失 低於某個閾值時,LLM會出現湧現能力。
而且,從 預訓練損失 的角度定義「湧現能力」,效果優於僅依賴模型參數或訓練量。
智譜AI的此番表現,也讓越來越多外國網友意識到——
19歲獲得博士的Stability AI研究主任Tanishq表示,CogVLM這類最有競爭力、為開源生態做出重大貢獻的開源基礎模型,就是來自中國。

這位遊戲工作室的前CEO,去年就開始用CogVLM和Stable Diffusion做完整的開源版本了。
是的,自CogVLM自釋出之後,其強大的能力便引起了外國網友的驚呼。
在今年1月的LLM排行榜中,也有人發現——
當時Gemini和GPT-4V遠遠領先於任何開源LLM,唯一一個例外,就是CogVLM。

可見,這波國產大模型出海,智譜AI已經悶聲不響地在國外建立了自己的巨大影響力。
特邀演講
展廳精彩演示之外,今年的ICLR,共邀請了七位特邀演講嘉賓,分享他們對AI的見解。
有來自谷歌DeepMind的研究科學家Raia Hadsell,佐治亞理工學院副教授&FAIR首席科學家Devi Parik,有來自馬克斯·普朗克電腦科學研究所(MPI-SWS)的主任Moritz Hardt,唯一一家中國團隊是智譜AI 的GLM 大模型技術團隊。
Raia Hadsell
谷歌DeepMind科學家Raia Hadsell的演講題目是——「在人工智慧發展的起伏過程中學習:通向AGI道路上的意外真理」。

經過數十年的穩定發展和偶爾的挫折後,AI正處在一個關鍵的拐點。
AI產品已經爆炸式地進入主流市場,我們還未觸及到scaling紅利的天花板,因此整個社群都在探討下一步的方向。

在這次的演講中,基於20多年在AI領域的經驗,Raia探討了我們對AGI發展之路的假設,如何隨時間發展而變化。
與此同時,她還揭示了,在這個探索的過程中,我們得到的意外發現。
從強化學習到分布式架構,再到神經網路,已經在科學領域發揮著潛在的革命性作用。
Raia認為,透過汲取過去的經驗教訓,可以為AI未來的研究方向提供重要的洞見。
Devi Parikh
另一邊,FAIR首席科學家Devi Parik給所有人講述了,自己生活中的故事。

從演講題目可見略知,Parik的分享內容,非比尋常。
在ICLR大會上,在解釋為什麽技術環境是現在這個樣子時,大家會重點針對互聯網、大數據和算力的發展,展開討論。
然鵝,鮮有人關註那些微小,但重要的個人故事。
其實,每個人的故事,都可以匯聚成為推動技術進步的重要力量。
透過這種方式,我們可以彼此學習,相互激勵。這讓我們在追求目標時,更加堅韌和高效。

Moritz Hardt
德國MPI-SWS主任Moritz Hardt帶來了「新興的科學基準」的演講。

顯然,基準測試成為機器學習領域的「核心支柱」。
自20世紀80年代以來,雖然人類在這個研究範式下取得了諸多成就,但對其深層次的理解仍然有限。

在此次演講中,Hardt透過一系列選定的實證研究和理論分析,探索基準測試作為一門新興科學的基本原理。
他具體討論了標註錯誤對數據品質的影響、模型排名的外部驗證性,以及多工基準測試的前景。
與此同時,Hard還展示了許多案例研究。
這些挑戰了我們的傳統看法,還突顯了發展科學基準測試的重要性和益處。
GLM Team
中國這邊,智譜AI的GLM大模型技術團隊,也帶來了「ChatGLM通往AGI之路」的精彩演講。
值得一提的是,這也是國內「首次」在國際頂級會議上展示大模型相關的主題演講。

這次演講,首先從中國的角度,介紹AI在過去幾十年的發展歷程。
同時,他們以ChatGLM為例,闡述自身在實踐過程中獲得的理解和洞見。

2024 AGI前瞻:GLM 4.5、 GLM-OS、 GLM-zero
在ICLR上,GLM大模型團隊介紹了面向AGI的GLM三大技術趨勢。
通往AGI的必經之路在哪裏?
業界對此意見不一。有人認為是智慧體,有人認為是多模態,有人說,Scaling Law是通往AGI的必要非充分條件。
而LeCun堅持認為,LLM是通往AGI的一條歧路,靠LLM帶不來AGI。
對此,團隊也提出了自己的獨特觀點。

首先,他們講到了GLM-4的後續升級版本,即GLM-4.5及其升級模型。
GLM-4的後續升級版,將基於超級認知(SuperIntelligence)和超級對齊(SuperAlignment)技術,同時在原生多模態領域和AI安全領域有長足進步。
GLM大模型團隊認為,在通往AGI的路上,文本是最關鍵的基礎。
而下一步,則應該把文本、影像、視訊、音訊等多種模態混合在一起訓練,變成一個真正的「原生多模態模型」。
同時,為了解決更加復雜的問題,他們還引入了GLM-OS概念,即以大模型為中心的通用計算系統。
這一觀點,與Karpathy此前提出的大模型作業系統的觀點,不謀而合。

在ICLR現場,GLM大模型團隊詳細介紹了GLM-OS的實作方式:
基於已有的All-Tools能力,再加上記憶體記憶(memory)和自我反饋(self-reflection)能力,GLM-OS有望成功模仿人類的PDCA機制,即Plan-Do-Check-Act迴圈。
具體來說就是,首先做出計劃,然後試一試形成反饋,調整規劃然後再行動以期達到更好的效果。
依靠PDCA迴圈機制,LLM便可以自我反饋和自主前進演化——恰如人類自己所做的一樣。
此外,GLM大模型團隊還透露,自2019年以來,團隊就一直在研究名為GLM-zero的技術,旨在研究人類的「無意識」學習機制。
「當人在睡覺的時候,大腦依然在無意識地學習。」

GLM大模型團隊表示,「無意識」學習機制是人類認知能力的重要組成部份,包括自我學習、自我反思和自我批評。
人腦中存在著「反饋」和「決策」兩個系統,分別對應著LLM大模型和記憶體記憶兩部份。
因此,GLM-zero的相關研究將進一步拓展人類對意識、知識、學習行為的理解。
盡管還處於非常早期的研究階段,但GLM-zero可以視為通向AGI的必經之路。
而這,也是GLM大模型團隊首次向外界公開這一技術趨勢。
國內頂流技術團隊
2020年底,GLM大模型技術團隊研發了GLM預訓練架構。
2021年訓練完成百億參數模型GLM-10B,同年利用MoE架構成功訓練出收斂的萬億稀疏模型。
2022年還合作研發了中英雙語千億級超大規模預訓練模型GLM-130B並開源。
而過去一年裏,團隊幾乎每3-4個月,就完成一次基座大模型的升級,目前已經更新到了GLM-4版本。
不僅如此,作為國內最早入局LLM公司,智譜AI曾在2023年就設立了一個雄心勃勃的目標——全線對標OpenAI。
GLM大模型技術團隊構建了基於AGI願景的完整大模型產品矩陣。
在GLM系列之外,還有CogView文生圖模型、CodeGeeX程式碼模型,多模態理解模型CogVLM,再到GLM-4V多模態大模型和All-Tools功能以及AI助手智譜清言。

與此同時,GLM大模型技術團隊的研究人員,在業界有著極高的影響力。
比如,圈裏爆火的李飛飛主講史丹佛大學CS25課程,每次都會邀請Transformer研究前沿的專家,分享自己的最新突破。
而目前已經確定,CS25課程的嘉賓中,就有來自智譜AI的研究員。

CogVLM
團隊開發的開源視覺語言模型CogVLM,一經釋出就引發了業界關註。
3月Stability AI公布的一篇論文就顯示,因效能太出色,CogVLM直接被Stable Diffufion 3拿來做影像標註了。

論文地址:https://arxiv.org/abs/2403.03206

CogAgent
在此基礎之上,基於CogVLM改進的開源視覺語言模型CogAgent,主要針對的是使用者圖形界面GUI的理解。
而CogAgent的相關論文,已經被國際電腦視覺領域級別最高的學術會議CVPR 2024收錄。
要知道,CVPR以錄取嚴格著稱,今年論文錄取率只有約2.8%。

論文地址:https://arxiv.org/abs/2312.08914
ChatGLM-Math
針對LLM解決數學問題,GLM大模型團隊提出了「Self-Critique」的叠代訓練方法。
即透過自我反饋機制,幫助LLM同時提升語言和數學的能力。

論文地址:https://arxiv.org/abs/2404.02893
這一方法,包含了兩個關鍵步驟:
首先訓練一個從LLM本身生成「Math-Critique」模型,以評估模型生成數學問題答案,並提供反饋訊號。
其次,透過拒絕采樣微調和DPO,利用新模型對LLM自身的生成進行監督。

GLM大模型團隊還設計了MATHUSEREVAL基準測試集,以評估新模型數學能力,結果如下:


顯而易見,新方法顯著提升了LLM的數學問題解決能力,同時仍能提升其語言能力。重要的是,它在某些情況下優於參數量增加兩倍的大模型。
GLM-4躋身全球第一梯隊
在OpenCompass 2.0基準測試中,智譜AI新一代基座大模型的實力不容小覷。
在總榜排名中,GLM-4位元列第三,位居國內榜首。

在不久前SuperBench團隊釋出的【SuperBench大模型綜合能力評測報告】中,GLM-4也躋身全球第一梯隊。
特別是在最關鍵的語意理解,智慧體能力上,GLM-4更是國內第一,力壓一眾競爭對手。

剛剛過去的大模型元年,熱鬧非凡的百模大戰打了一年。
2024年,若想化身為AGI元年,全世界大模型團隊還有很長的路要走。











