蘋果最新殺入開源大模型戰場,而且比其他公司更開放。
推出7B模型,不僅效果與Llama 3 8B相當,而且一次性開源了全部訓練過程和資源。
要知道,不久前Nature雜誌編輯Elizabeth Gibney還撰文批評:
許多聲稱開源的AI模型,實際上在數據和訓練方法上並不透明,無法滿足真正的科學研究需求。
而蘋果這次竟然來真的!!
就連NLP科學家、AutoAWQ建立者也發出驚嘆:
Apple釋出了一個擊敗Mistral 7B的模型,但更棒的是他們完全開源了所有內容,包括預訓練數據集!
也引來網友線上調侃:

至於這次開源的意義,有熱心網友也幫忙總結了:
對於任何想要從頭開始訓練模型或微調現有模型的人來說,數據管理過程是必須研究的。
當然,除了OpenAI和蘋果,上周Mistral AI聯合輝達也釋出了一個12B參數小模型。
HuggingFace創始人表示,「小模型周」來了!

卷!繼續卷!所以蘋果這次釋出的小模型究竟有多能打?
效果直逼Llama 3 8B
有多能打先不說,先來看Hugging Face技術主管剛「拆箱」的模型基礎配置。
總結下來就是:
7B基礎模型,在開放數據集上使用2.5T tokens進行訓練
主要是英文數據,擁有2048tokens上下文視窗
數據集包括DCLM-BASELINE、StarCoder和ProofPile2
MMLU得分接近Llama 3 8B
使用PyTorch和OpenLM框架進行訓練

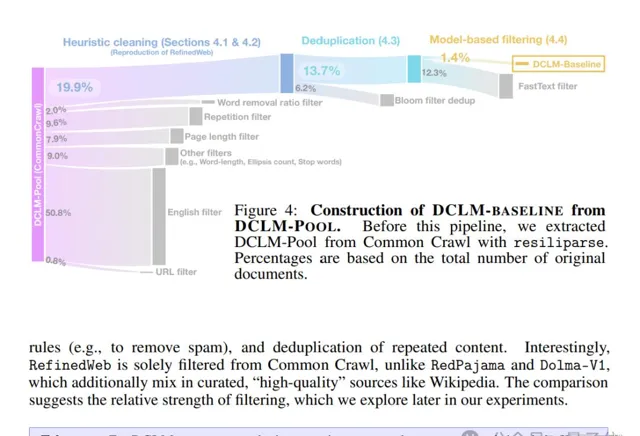
具體而言,研究團隊先是提出了一個語言模型數據比較新基準——DCLM。
之所以提出這一基準,是因為團隊發現:
由機器學習 (ML) 模型從較大的數據集中自動過濾和選擇高品質數據,可能是構建高品質訓練集的關鍵。
因此,團隊使用DCLM來設計高品質數據集從而提高模型效能,尤其是在多模態領域。
其思路很簡單:使用一個標準化的框架來進行實驗,包括固定的模型架構、訓練程式碼、超參數和評估,最終找出哪種數據整理策略最適合訓練出高效能的模型。
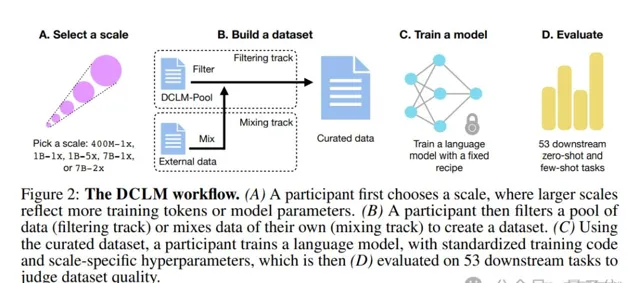
基於上述思路,團隊構建了一個高品質數據集DCLM-BASELINE,並用它從頭訓練了一個7B參數模型——DCLM-7B。
DCLM-7B具體表現如何呢?
結果顯示,它在MMLU基準上5-shot準確率達64%,可與Mistral-7B-v0.3(63%)和Llama 3 8B(66%)相媲美;並且在53個自然語言理解任務上的平均表現也可與Llama 3 8B相媲美,而所需計算量僅為後者的1/6。
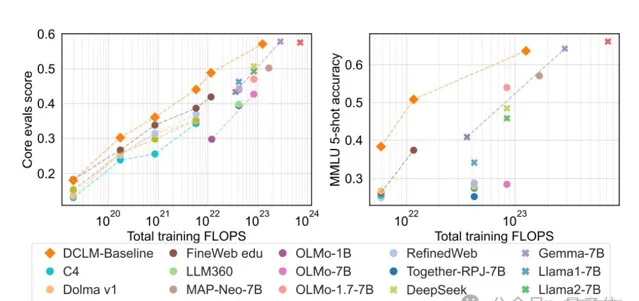
與其他同等大小模型相比,DCLM-7B的MMLU得分超越Mistral-7B,接近Llama 3 8B。
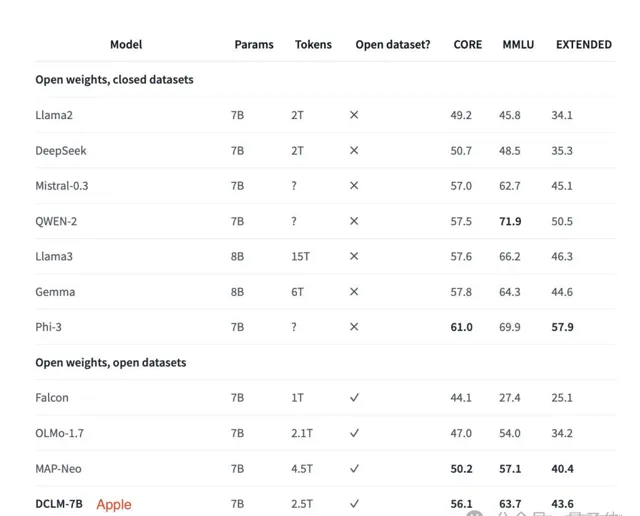
最後,為了測試新數據集效果,有業內人士用Kappa西的llm.c訓練了GPT-2 1.5B,來比較DCLM-Baseline與FineWeb-Edu這兩個數據集。

結果顯示DCLM-Baseline取得了更高的平均分,且在ARC(小學生科學問題推理)、HellaSwag(常識推理)、MMLU等任務上表現更好。

「小」模型成新趨勢
回到開頭,「小」模型最近已成新趨勢。
先是HuggingFace推出了小模型家族「SmolLM」,其中包含135M、360M和1.7B型號模型。

它們在廣泛的推理和常識基準上優於類似大小的模型。

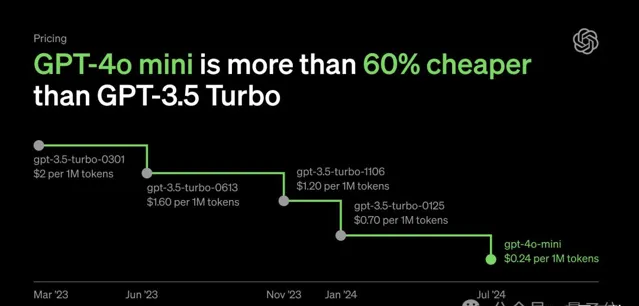
然後OpenAI突然釋出了GPT-4o mini,不僅能力接近GPT-4,而且價格大幅下降。
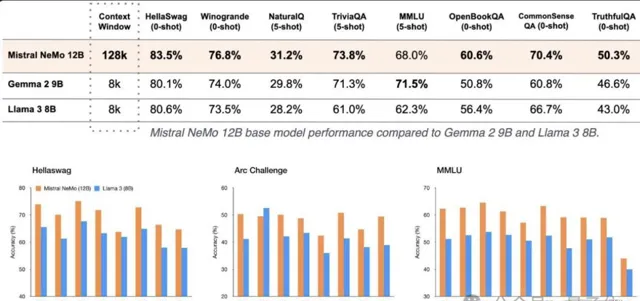
就在GPT-4o mini釋出同日,Mistral AI聯合輝達釋出了12B參數小模型——Mistral NeMo。
從整體效能上看,Mistral NeMo在多項基準測試中,擊敗了Gemma 2 9B和Llama 3 8B。
所以,為啥大家都開始卷小模型了?
原因嘛可能正如smol AI創始人提醒的,雖然模型變小了,但在能力相近的情況下,小模型大大降低了成本。
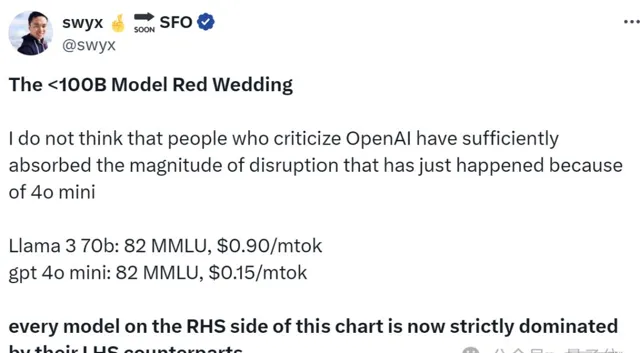
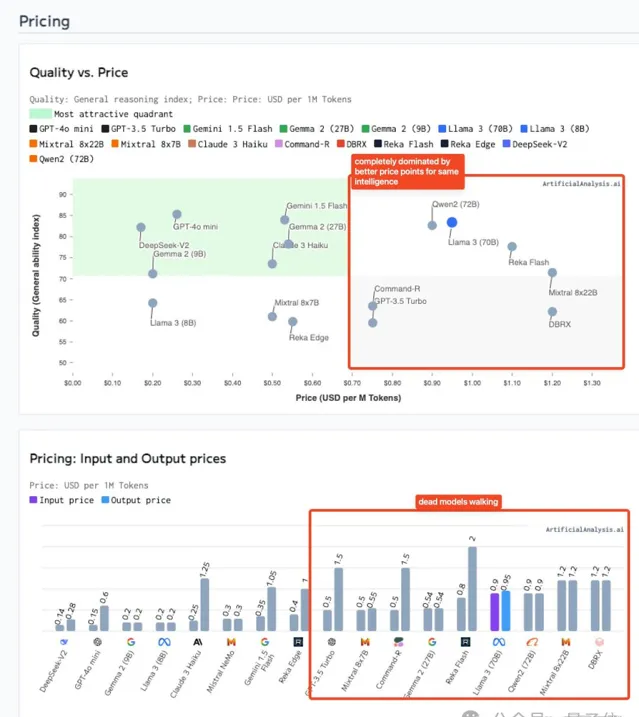
就像他提供的這張圖,以GPT-4o mini為代表的小模型整體比右側價格更低。
對此,我等吃瓜群眾be like:
所以,你更看好哪家呢?











