一直以來,研究人員都在試圖開發出能夠在現實環境中安全、高效地執行復雜任務(如多指手操作)的機器人技能。傳統的機器人學習方法往往需要大量的實際數據,這不僅耗時耗力,還存在安全風險。因此,仿真環境下的學習並結合後續的仿真到現實(sim-to-real)遷移成為了一個有效的替代方案。
近日, 谷歌DeepMind團隊提出了一種名為DemoStart的新型自主強化學習方法,該方法能夠在只有少量示範和稀疏獎勵的情況下,讓裝備有機械手臂的機器人在仿真環境中學習復雜的操作技能,並成功實作了零樣本的仿真到現實遷移。
▍ Google DeepMind推出DemoStart技術
DemoStart方法是一種結合了示範引導與稀疏獎勵的強化學習框架,目的是透過自動化課程設計,提高機器人在仿真環境中的操作技能學習效率,並最終實作這些技能從仿真到現實的零樣本遷移。 該方法的核心在於透過少量且可能不完全最佳化的示範來指導強化學習演算法的探索過程,從而找到解決復雜操作任務的有效策略。

DemoStart從20個模擬演示開始 生成了強化學習教程
研究人員表示,DemoStart方法首先利用提供的示範數據,將示範中的每個狀態轉換為一系列不同難度的任務參數(TP)。這些任務參數在後續強化學習過程中作為學習的起點,透過動態調整學習任務的難度,引導策略逐步逼近最優解。 與傳統強化學習方法相比,DemoStart不需要復雜的獎勵函式設計,僅需一個簡單的稀疏獎勵訊號即可指導學習過程,大大降低了任務設計的難度和成本。
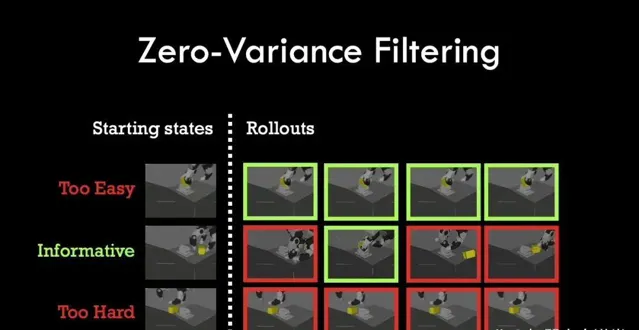
此外,DemoStart還透過一種稱為零變異數過濾(ZVF)的機制來最佳化學習過程。ZVF透過分析策略在當前任務參數下的表現穩定性,篩選出那些既能提供有效學習訊號又不會導致訓練過程陷入局部最優的任務參數。這種機制有助於策略在保持一定探索性的同時,穩步提高效能。

在實作過程中, DemoStart采用了一種分布式行動者-學習者架構 ,其中行動者在仿真環境中執行策略並收集經驗數據,而學習者則根據這些數據進行策略更新。為了實作仿真到現實的遷移, DemoStart還引入了一種策略蒸餾技術 ,將基於仿真特征的策略轉換為基於視覺的策略,從而使得訓練出的策略能夠在真實環境中執行。
▍ DemoStart技術整合三個關鍵機制
研究人員表示, DemoStart技術整合了三個關鍵機制,分別為示範引導的任務參數化、零變異數過濾的最佳化選擇與策略蒸餾的視覺遷移。
具體來看,DemoStart方法能夠利用示範數據來生成一系列不同難度的任務參數(TP)。在仿真環境中,透過記錄並保存示範過程中每個時間步的環境狀態,可以生成多個起始狀態作為任務參數。這些起始狀態分布在示範的不同位置,從而構成了一個從易到難的任務序列。

透過將這些任務參數作為強化學習的起點,DemoStart能夠逐步引導策略從簡單的任務開始學習,逐漸挑戰更復雜的任務,最終實作復雜操作技能的掌握。
另一個關鍵機制是零變異數過濾(ZVF),它透過對任務參數進行篩選,最佳化學習過程中的經驗數據選擇。ZVF機制透過分析策略在當前任務參數下的表現穩定性,即策略在某些任務參數下是否有時成功有時失敗,來辨識出那些既不過於簡單也不過於困難的任務參數。這些任務參數能夠提供有效的學習訊號,幫助策略在保持探索性的同時穩步提高效能。透過丟棄那些成功率始終為0或1的任務參數,ZVF避免了策略陷入局部最優或無法獲得學習訊號的情況,從而提高了學習效率。
為了實作從仿真到現實的零樣本遷移,DemoStart引入了策略蒸餾技術。在仿真環境中,首先訓練一個基於特征的策略,該策略能夠高效地完成各種操作任務。然後,透過策略蒸餾過程,將這個基於特征的策略轉換為一個基於視覺的策略。
蒸餾過程中,利用行為複制方法從教師策略(基於特征的策略)生成的數據中學習一個學生策略(基於視覺的策略),使得學生策略能夠僅依靠視覺輸入和機器人本體感覺資訊來執行操作任務。這種轉換不僅保留了教師策略的高效性,還使得策略能夠在真實環境中執行,因為真實環境中的機器人通常只能透過視覺和本體感覺來獲取環境資訊。透過策略蒸餾,DemoStart實作了從仿真到現實的平滑遷移,為機器人在現實中的套用提供了可能。
▍ DemoStart方法實作細節解析
DemoStart方法采用分布式行動者-學習者架構來實作高效的數據收集和策略更新。 在架構中,多個行動者並列執行在仿真環境中,每個行動者負責執行當前策略並收集經驗數據。收集到的經驗數據被發送到中心化的學習者,學習者根據這些數據來更新策略。

實驗設定:模擬(頂部)和真實(底部)機器人環境和任務
這種架構的優勢在於能夠充分利用多核處理器的計算能力,加速數據收集和策略更新的速度。同時,由於行動者和學習者之間的解耦,使得系統更加靈活和可延伸,可以根據需要增加或減少行動者的數量來調整系統效能。

訓練分布從演示的結束轉移到演示的開始
在策略蒸餾階段,為了訓練基於視覺的策略,需要從基於特征的策略中生成大量的訓練數據。這些數據通常以軌跡的形式存在,每條軌跡包含一系列狀態、動作和獎勵資訊。
為了確保蒸餾過程的穩定性和高效性,DemoStart方法對訓練數據進行了一系列預處理。首先,從基於特征的策略中篩選出成功的軌跡,這些軌跡代表了策略在不同任務參數下的有效行為。然後,對每條軌跡進行標註,標記出每個時間步的視覺輸入、本體感覺資訊和相應的動作。最後,將這些標註好的軌跡組合成訓練數據集,用於訓練基於視覺的策略。
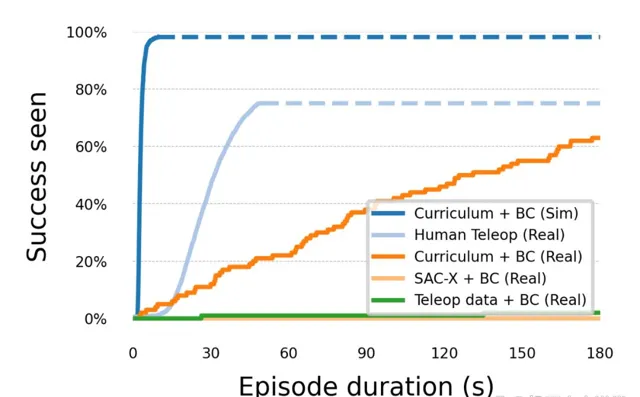
拾取放置成功率隨情節持續時間而變化
在訓練基於視覺的策略時,DemoStart方法利用多個相機來捕捉環境的視覺資訊。這些相機被固定在機器人周圍的不同位置,以確保能夠全面覆蓋機器人的工作空間。為了處理來自多個相機的視覺輸入,DemoStart采用了一種多模態編碼方法,將每個相機的影像輸入到獨立的摺積神經網路中進行特征提取。然後,將提取到的特征向量進行拼接和融合,作為視覺策略的輸入。
此外,為了進一步提高策略的魯棒性和適應力,DemoStart還引入了域隨機化技術來模擬不同光照條件、相機視角和物體外觀的變化。透過在訓練過程中不斷變化這些視覺因素,使得策略能夠學習到更加泛化的視覺表示,從而更好地適應真實環境中的各種不確定性。
▍ 實測DemoStart在三指機械手上的任務執行能力
為了驗證DemoStart方法的有效性,研究人員在配備有三指機械手(DEX-EE Hand)的Kuka LBR iiwa14機器人上進行測試,真實環境中的設定被精確復制到仿真環境中,使用MuJoCo物理引擎進行模擬。機器人需要完成的任務包括插頭提升、插頭插入、立方體定向、螺母螺栓螺紋連線以及螺絲刀放入杯子等。
在仿真環境中,DemoStart在多個任務上均取得了超過98%的成功率,遠超基於示範直接學習的策略。 與標準的強化學習基線相比,DemoStart僅使用極少量的示範就達到了出色的效能,顯示出其高效的學習能力。
在插頭插入任務中,DemoStart方法透過少量示範和稀疏獎勵,成功引導策略學習到了高效的插頭插入行為。 策略不僅學會了如何準確地定位和插入插頭,還能夠在面對不同初始狀態時表現出良好的泛化能力。在實驗過程中,研究人員觀察到策略逐漸從依賴示範行為轉變為發現更加高效和魯棒的操作方式,充分證明了DemoStart方法在強化學習過程中的探索和最佳化能力。
為了進一步驗證DemoStart方法的仿真到現實遷移能力,研究人員將訓練好的策略透過策略蒸餾技術轉換為基於視覺的策略,並在真實機器人上進行了測試。實驗結果顯示,經過蒸餾的策略在真實環境中依然保持了較高的成功率, 特別是在插頭插入和插頭提升任務中,成功率分別達到了64%和97%,顯著優於僅依賴示範學習的方法。
此外研究人員還對DemoStart方法進行了詳細的消融實驗,以分析不同機制對效能的影響。結果顯示,零變異數過濾機制在提升策略效能和穩定性方面發揮了關鍵作用,而策略蒸餾技術則是實作仿真到現實遷移的核心。 透過結合這些機制,DemoStart方法成功地實作了在少量數據和稀疏獎勵條件下的高效強化學習,為機器人操作技能的自動化學習提供了一種新的解決方案。
▍ 結語與未來:
DemoStart是一種創新的自主強化學習方法,能夠在只有少量示範和稀疏獎勵的情況下訓練出高效能的機器人操作技能,並實作零樣本的仿真到現實遷移,該方法不僅簡化了任務設計過程,還有效提高了學習效率。隨著未來研究的不斷推進,DemoStart有望在更多復雜機器人操作任務中發揮重要作用。











