面向大數據的時空資料探勘現狀
隨著傳感器網路、手持行動裝置等的普遍套用,遙感衛星和地理資訊系統等的顯著進步,人們獲取了大量地理科學數據。這些數據內嵌於連續空間,並且隨時間動態變化,具有很大程度的特殊性和復雜性。實際上,很多套用領域,例如交通運輸、氣象研究、地震救援、犯罪分析、公共衛生與醫療等,在問題求解過程中需要同時考慮時間和空間兩方面因素。而隨著資訊科技的發展,人們已經不滿足於單純的時空數據的儲存和展現,而是需要更先進的手段幫助理解時空數據的變化。如何從這些復雜、海量、高維、高雜訊和非線性的時空數據中挖掘出隱含的時空模式,並對這些模式進行分析從而提取出有價值的資訊並用於商業活動是對時空資料探勘及分析技術的一項極大的挑戰。
IBM SPSS Modeler 是參照行業標準 CRISP-DM 模型設計而成的資料探勘工具,可支持從數據到更優商業成果的整個資料探勘過程。透過結合時空數據和其他商業數據,並且運用資料探勘工具 IBM SPSS Modeler 對時間和空間內容進行觀測分析,建立預測性模型,進而獲得決定性的認知,並將其套用於商業活動,從而改進決策過程。
面向大數據的時空預測簡介
面向大數據的時空預測主要是基於時空物件的特征構建預測模型進而預測時空物件在未來特定時間範圍內特定空間位置下的行為或者狀態。
時空預測的分類
根據時空物件的不同,時空預測有不同的分類。面向時空數據的位置和軌跡預測、密度和事件預測、結合空間的時間序列預測等研究都具有重要的套用前景。
位置和軌跡預測
面向時空數據的位置預測主要是基於時空物件的特征構建預測模型來預測時空物件所在的具體空間位置。對於即時物流、即時交通管理、基於位置的服務和 GPS 導航等涉及時空數據的套用而言,預測單個或者一組物件未來的位置或目的地是至關重要的,它能使系統在延誤的情況下采取必要的補救措施,避免擁堵,提高效率。
除了位置預測之外,面向時空數據的軌跡預測可以推測移動物件的出行規律。例如,社群網路套用借助 GPS 裝置記錄使用者軌跡數據,透過」簽到」套用(如微信、微博等)分享位置資訊。分析這些共享的 GPS 軌跡數據,可以為使用者推薦感興趣的旅遊景點和遊覽次序。
密度、事件預測
某個區域的物件密度定義為在給定時間點該區域內物件數與該區域大小之比。這是一些物件隨時間變化而呈現出的一個全域特征。面向時空數據的密度預測主要套用於即時交通管理,會對及時改善交通擁堵帶來很大助益。例如,交通管理系統透過密度預測可以辨識出道路中的密集區域,從而幫助使用者避免陷入交通阻塞,並采取有效措施及時緩解交通擁堵。此外,面向時空數據的事件預測可以根據歷史數據(時間序列),結合地理區域密度估計(發現重要特征和時空地點)來預測給定時間範圍和空間位置的機率密度,譬如基於過去犯罪事件發生的地點、時間和城市經濟等特征預測給定區域和時間段內犯罪發生的機率,進而檢測犯罪發展趨勢,有效降低城市犯罪率。
結合空間的時間序列預測
結合空間的時間序列預測是從時間的角度來考慮時空數據。與傳統的時間序列不同的是,與空間有關的時間序列彼此不是獨立的,而是和空間相關的。例如,可以首先構造時間序列模型以獲取每個獨立空間區域的時間特性,然後構造神經網路模型擬合隱含的空間相關性,最後基於統計回歸結合時間和空間預測獲得綜合預測。
時空預測的理論框架
如上所述,時空預測根據時空物件的不同有不同的分類方法,本文我們重點介紹 IBM SPSS Modeler 中對於包含時間和空間兩種內容的數據的建模與預測。其提供了一個綜合時間和空間內容的有效的手段,充分利用各種數據序列的特征,將時間、空間及時空自回歸預測方法有效地結合,並在預測同時考慮了研究物件之間的空間影響關系,從而提高了預測的精確度。
時空數據建模
時空預測模型實質上是一個基於線性回歸的擴充套件模型,其原理可以用如下公式表示:

其中, 系數β是自變量的系數,表示自變量對於目標變量的影響程度;Z作為線性擬合的殘留誤差,是目標變量變化中用自變量線性組合無法表示的部份,可用來在自回歸(Autoregressive,AR)模型中捕捉時間自相關性,進而用於描述空間的相關性。我們可以透過圖 1 所示的流程圖來具體討論這一過程。
圖 1. 時空數據建模流程圖
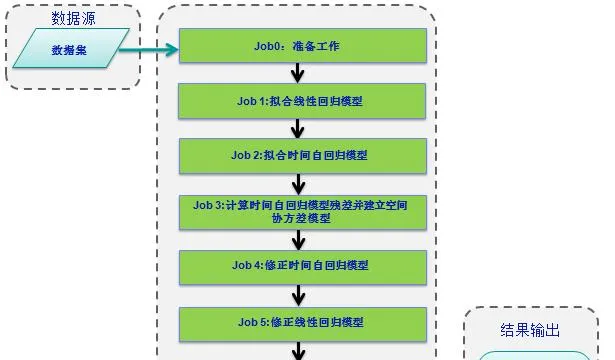
Job0 :準備工作
針對時空建模的復雜性,適當的數據驗證和缺失值篩選將有助於模型的構建。透過檢測,包含缺失值或無效值百分比較高的一些樣本位置將從分析中刪除,而缺失值或無效值百分比較低的樣本位置則被留下來,後期建模過程中將對其進行特殊編碼處理,以盡可能多保留數據資訊。
Job1 :擬合線性回歸模型
回歸模型采用標準的線性回歸模型(包括或不包括截距),但由於數據的時空相關關系,其殘留誤差會形成一個零均值的非獨立的時空相關隨機過程。線性回歸的系數,可衡量自變量對目標變量的影響程度,較大的系數對應的自變量表明其單位變化會產生較大的目標變量變化。
Job2 :擬合時間自回歸模型
自回歸模型使用指定的自回歸階數,即指定之前若幹個時刻的值來預測當前值。自回歸的系數可用與衡量過往時刻的殘留誤差對當前值的影響。自回歸模型同樣包含殘留誤差,由於其中的時間自相關因素已被移除,自回歸模型的殘留誤差在時間上是相互獨立的。
Job3 :計算時間自回歸模型殘留誤差並建立空間共變異數模型
基於地理空間的共變異數模型建立在時間自回歸模型殘留誤差的基礎上,空間共變異數模型有兩種實作方法:參數法和非參數法。參數法具有更精簡的數學運算式和更好的模型推廣能力,所以在假設所給數據能夠進行參數化建模的情況下,提供了兩個參數檢驗方法來確定模型的準確性。其一是檢測是否空間中存在隨著距離而變化的衰減,其二檢測空間變異數在給定區域具有普遍性(變異數同質性檢驗)。如果不滿足參數化模型的假設,將會構造非參數化的模型,利用空間殘留誤差所形成空間關系矩陣來描述數據中的空間關系。
Job4 :修正時間自回歸模型
空間共變異數量化表達了數據的空間關系,從而可以從之前線性回歸的殘留誤差中移除空間關系的影響,進而能夠修正時間自回歸模型,更新自回歸模型的參數,獲得更加準確的時間自回歸關系的描述。
Job5 :修正線性回歸模型
基於準確 的空間關系和時間自相關關系的描述,可從原始的數據中去除時間和空間關系的影響,從而能夠修正線性回歸模型的參數,更加準確的描述出自變量對目標變量的影響。
Job6 :計算測定後的統計值並保存結果
上述步驟已經完成了模型的估計過程,獲得的模型可生成目標變量的估計值,與觀測值相比較,能夠評價所建模型的品質。同時透過一些參數檢驗的方法,可以評價自變量,時間自回歸系數的重要性等一些基於模型的評價指標。
時空數據預測
時空數據預測是基於時空數據模型的一個假設情況分析(what-if 分析),可以預測未來一段時間在分析範圍中任何地理位置的目標值。我們可以透過圖 2 所示的流程圖來具體討論這一過程。
圖 2. 時空數據預測流程圖
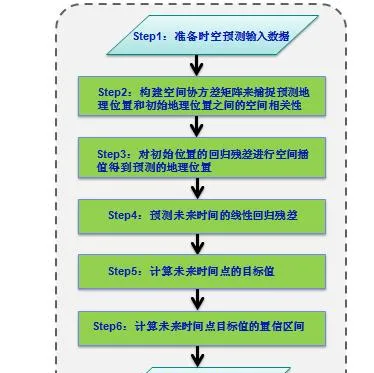
Step1 :準備時空預測輸入數據
想要獲得未來時間的目標預測值,首先需要有和時空數據建模的輸入數據結構統一的未來時刻的自變量數據。未來時刻的自變量數據可以保持已知的最終數據不變,或者是人為修改過的用於假設分析的數據。
Step2 :構建空間共變異數矩陣來捕捉預測地理位置和初始地理位置之間的空間相關性
預測數據中的地理位置和初始數據中的地理位置可以不同,也可以預測數據中一些地理位置和初始地理位置相同,或者預測地理位置是初始地理位置的子集。
Step3 :對初始位置的回歸殘留誤差進行空間插值得到預測的地理位置
利用第 2 步構建的空間共變異數矩陣對初始地理位置經過轉換後的回歸殘留誤差進行插補,從而得到預測的地理位置 。
Step4 :預測未來時間的線性回歸殘留誤差
預測未來時間的回歸殘留誤差是在時間點 m+1, m+2, … m+H 上逐步叠代進行, 其中, m 是建模的最終時間點,H 是需要預測的未來時間點的個數。
Step5 :計算未來時間點的目標值
未來時間點的目標值需要透過回歸模型,第 4 步中計算得到的時間點 m+1, m+2, … m+H 上的回歸殘留誤差和在未來時間點和新的地理位置上的預測輸入數據值來計算。
Step6 :計算未來時間點目標值的置信區間
基於高斯過程和已知模型每一部份的變異數情況,可逐級推出最終預測目標值的置信區間。此步驟過於復雜,本文不作詳述。
Step7 :預測結果輸出
最終得到的預測結果包括在未來時間指定位置的目標值,以及預測值置信區間的上下限。
時空預測套用例項
在充分了解時空數據建模及預測理論結構的基礎上,我們來描述該時空預測模型在 IBM SPSS Modeler 中的具體實作,並結合套用例項展示如何套用時空數據模型的假設情況分析(what-if 分析)實作對未來任何時間任何地點目標值的準確預測。
時空預測模型描述
在 IBM SPSS Modeler 中,時空預測模型分析使用包含位置數據、預測輸入欄位(預測變量)、時間欄位和目標欄位的數據,如圖 3 中時空預測模型欄位選項的參數所示。 時空預測模型的輸入數據必須是經過時空數據預處理,融合了時間序列和形狀數據,同時包含時間變量,空間位置變量及其他相關變量的數據。在該數據中,每個位置在數據中都有許多行,這些行表示每個預測變量在每個測量時間的值。 分析數據後,可以使用該數據來預測所使用的形狀數據(.shp 檔)內任意位置處的目標值。 並且,還可以預測何時能夠獲知未來時間點的輸入數據。
圖 3.時空預測模型-欄位選項
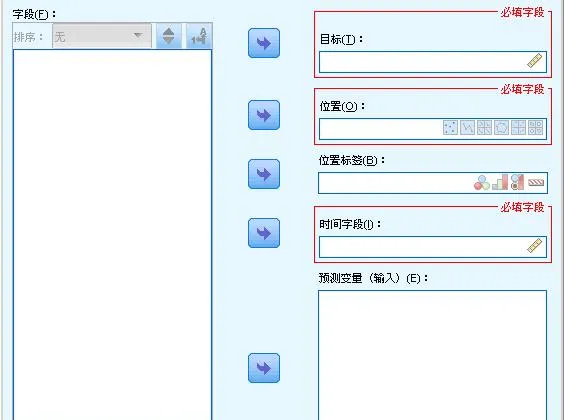
這裏,目標欄位是將要預測的目標變量。位置欄位是一個測量級別為」地理空間」的欄位,可以是點、線、多邊形(面)、多點、多線、多面等位置型別。形狀數據通常包含一個表明層特征的名稱的欄位,例如,這可能是省/自治區/直轄市或者國家或地區的名稱。 使用此欄位可以將名稱或標簽與位置相關聯,方法是選擇一個分類欄位來標註輸出中的所選位置欄位,即位置標簽欄位。時間欄位是要在預測中使用的時間變量,只能選擇測量級別為」連續」且儲存型別為時間、日期、時間戳記或整數的欄位。預測變量是預測輸入欄位,只能選擇測量級別為」連續」的欄位。
設定好時空預測模型所需的變量後,我們就該考慮時空預測模型的構建了。在 IBM SPSS Modeler 中,時空預測模型的構建選項還分為時間間隔、基本、高級和輸出等子項,分別實作時空數據建模中的不同功能。
在可以構建時空預測模型之前,需要進行數據準備以便將時間欄位轉換為索引;要使得能夠進行這種轉換,時間欄位中的記錄之間必須有固定的區間。如果數據尚未包含此資訊,我們就可以使用」時間間隔」子項中的選項來設定此區間,然後才能進行時空數據建模。」時間間隔」選項如圖 4 所示。
圖 4. 時空預測模型-時間間隔選項
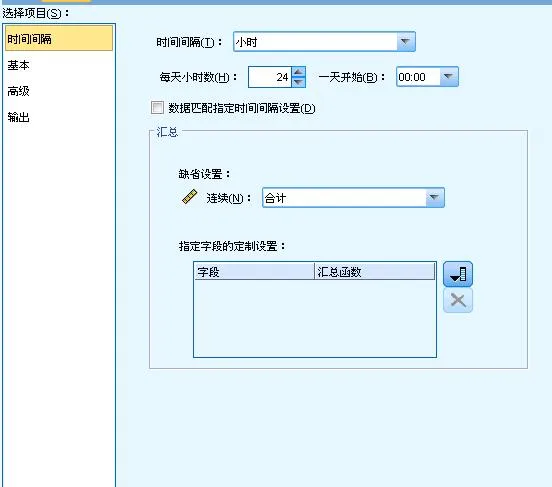
根據輸入數據中時間欄位的特征選擇或者轉換為合適的時間間隔是時空數據建模的必要條件。這裏,時間間隔可以以周期、年、季度、月、周、天、時、分、秒等一系列為單位。基於所選的時間間隔,還有一系列與之相關的選項,比如,時間間隔為年或季度時的開始月份,時間間隔為周時每周的第一天和每周的天數,時間間隔為小時時每天的小時數和一天開始的時間等。如果輸入數據已包含正確的時間間隔資訊,並且不需要進行轉換,選中」數據匹配指定時間間隔設定」 核取方塊。 選中此框後,」匯總」區域中的設定將不可用。反之,如果輸入數據中的時間欄位需要轉換為特定區間,取消選中」數據匹配指定時間間隔設定」核取方塊,並指定用於匯總的欄位以便與指定區間匹配的選項。 例如,如果有以周和月為單位的混合數據,那麽可以對周值進行匯總或累計,以獲得均勻的月間隔。所用的匯總方法可以從」缺省設定」下拉框中選擇並套用於未逐個指定的所有連續欄位。如果希望對於特定欄位進行客製設定,即將特定匯總函式套用於個別欄位,則在」指定欄位的客製設定」表中選擇欄位並選擇匯總方法。
實際上,時間間隔的設定與轉換是時空數據預處理的一部份,在 IBM SPSS Modeler 中,為方便使用,內嵌於時空數據建模中。時空數據建模的構建實質是透過基本構建選項和高級構建選項來設定的,如圖 5 和圖 6 所示。
圖 5. 時空預測模型-基本構建選項
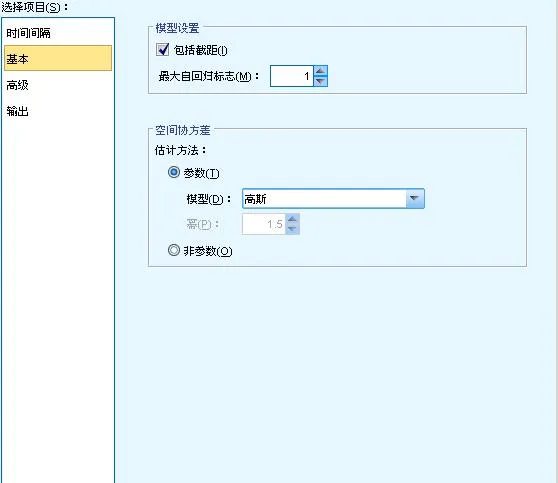
我們可以在基本構建選項裏主要設定最大自回歸階數和空間共變異數矩陣的估計方法。自回歸階指定使用哪些先前值來預測當前值,使用」最大自回歸標誌」選項可以指定用於計算新值的先前記錄數。空間共變異數的估計方法可以選擇參數或非參數,其中參數方法又可以從三種模型型別中進行選擇:高斯、指數和冪指。
圖 6. 時空預測模型-高級構建選項
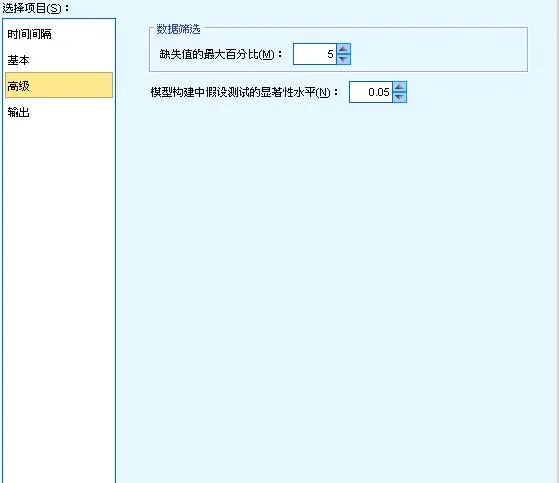
時空數據建模的高級構建選項主要用來對模型構建過程進行微調。其中,」缺失值的最大百分比」指定模型中可以包括的包含缺失值的記錄所占的最大百分比。」模型構建中假設測試的顯著性水平」指定用於時空數據模型估計的所有檢驗(包括兩項擬合優度檢驗、效應 F 檢驗和系數 T 檢驗)的顯著性水平值,此級別可以是 0 與 1 之間的任何值,並以 0.01 為增量變動。
最後是時空數據模型的輸出選項,主要用於在構建模型之前,使用此頁面中的選項來選擇要包括在模型輸出檢視器中的輸出,如圖 7 所示。
圖 7.時空預測模型-輸出選項
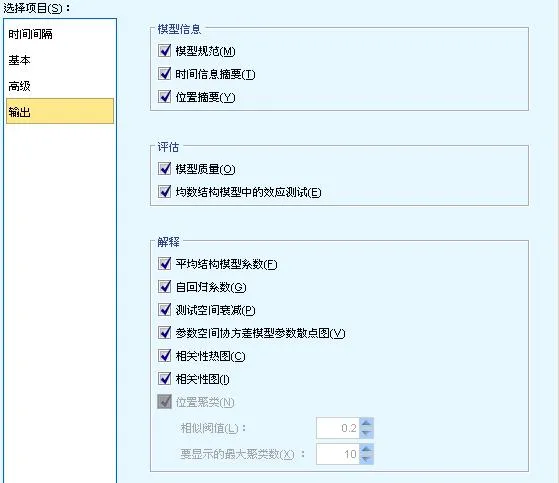
如圖所示,時空數據模型的輸出分為模型資訊、評估、和解釋三部份。其中,模型資訊包括模型規範和時間資訊摘要;評估包括模型品質和均值結構模型中的效應檢驗;解釋包括平均結構模型系數、自回歸系數、測試空間衰減、參數空間共變異數模型參數散點圖、相關性熱圖、相關性圖和位置聚類。所有這些圖或表均從不同角度展現時空數據模型,以不同形式向使用者詮釋時空數據模型的意義。
時空預測套用例項
時空預測模型有許多潛在的套用,例如緊急管理建築物或設施、對機械服務工程師進行績效分析和預測或者進行公共交通規劃。 在這些套用中,通常要對時間和空間進行能耗等測量。 可能與記錄這些測量值相關的問題包括哪些因子影響未來的觀測值、如何實作所需的變化或者如何更好地管理系統? 為了回答這些問題,我們可以在不同位置使用能夠預測未來值的統計技術,並可以顯式地對可調因子進行建模以執行假設情況分析。
本節我們將透過套用時空數據建模以及執行假設情況分析來實作數據中心的能量管理,避免使用過多的制冷能量把數據中心的熱量控制在可接受的標準範圍內。一個典型的數據中心,壓力通風系統(plenum)透過打孔瓦(perforated tiles)供應冷空氣,冷空氣透過通風口(inlet)冷卻伺服器溫度。而伺服器散發熱空氣並傳給空調機組(ACU),熱空氣在空調機組裏被冷卻並重新交換到壓力通風系統,依此迴圈。為了更好地實作數據中心的能量管理,數據中心還需部署即時熱量傳感器(thermal sensors)來監控能量使用。但是,熱量傳感器不可能存在數據中心的任何一個位置,因而需要對沒有部署熱量傳感器的位置進行預測。因此,我們將建立一個時空數據預測模型來預測整個數據中心在未來時間的溫度,並結合影響數據中心溫度的其他相關因素執行假設情況分析,從而對如何改善數據中心的能量使用效率提出建設性意見。
數據收集和預處理
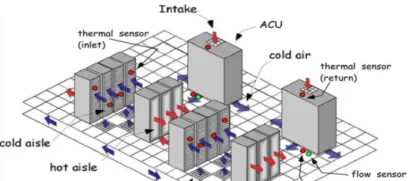
為了進一步理解並調控數據中心的熱量管理系統,數據中心在有限的位置布置熱量傳感器,透過傳感器收集不同位置的即時溫度。另外,數據中心的熱量傳感器、空調機組和打孔瓦的物理參數,比如每個熱量傳感器的座標位置,每個空調機組的座標位置和長寬高(三維物體)以及打孔瓦的座標和長寬(二維物體)等資訊也會相應地影響數據中心不同位置的空氣流,如圖 8 所示。
圖 8. 數據中心結構圖
這些數據不能直接套用於時空數據預測建模,必須要先進行數據預處理,把溫度數據、各個物體的位置數據等進行融合,從而得到一個包含空間地理位置欄位,時間欄位,預測輸入欄位和將要預測的目標欄位的一個表格式的輸入數據。
時空數據建模
經過數據預處理,我們得到一個包括時空數據預測建模所需欄位的標準輸入數據。然後我們將選擇並設定時空數據預測模型的不同參數來建立時空數據預測模型。很顯然,這裏的目標欄位為數據中心的溫度,空間位置欄位為溫度被監控的位置,即熱量傳感器的座標位置,時間欄位為溫度被監控的一系列時間點,預測數據欄位則為其他相關因素,包括數據中心的空氣流、空調機組的長寬高等,如圖 9 所示。
圖 9. 數據預處理後的輸入數據結構

接下來根據數據中心溫度的監控時間點來設定時間間隔選項,如果溫度是每小時收集一次,那麽時間間隔應設為小時並設定起始點;如果溫度的收集頻率是一天一次,則應設時間間隔為天。並且根據輸入數據的時間變量的特征決定是否需要對數據進行轉換從而使得數據與指定的時間間隔設定匹配。
然後根據需求設定最大自回歸階數指定使用哪些先前值來預測未來值,並且指定計算空間共變異數的估計方法。為了最大程度的提高對時空數據預測模型的預測準確性,還可以透過設定」缺失值的最大百分比」和」模型構建中用於假設檢驗的顯著性水平」 對模型構建過程進行微調。
最後構建時空數據模型,從而實作後續的模型輸出和假設檢驗分析。
時空數據預測
想要獲得對目標值的預測,即要了解下一個時間監測點或者將來某個時間點數據中心不同位置的溫度值,需要有和時空數據建模的輸入數據結構統一的預測輸入數據。其中,時間為將要預測溫度值的時間點,空間位置為將要預測溫度值的位置點,其他相關輸入變量均為每個將要預測溫度的位置的相應未來值。有了預測輸入變量,輸入時空數據模型即可得到數據中心在指定時間指定位置的溫度值,同時還可獲得該預測值的錯誤變異數及預測置信度的上下限。
時空預測結果展示
時空數據預測模型的顯著性不僅在於它可以同時處理時間和空間兩種內容並對未來任何時間任何地點的目標值進行預測,更在於可以透過時空預測模型進行假設檢驗分析從而改善決策。
在上述數據中心能量管理的套用例項中,時空數據模型可以透過熱圖來視覺化在指定時間指定位置的目標值,如圖 10 所示。
圖 10. 數據中心溫度預測熱圖

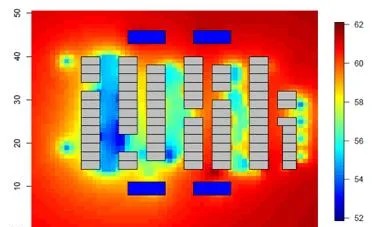
在時空預測過程中,首先假定在下一個時間監測點所有其他的參數都保持現有值,即空調機組的數目和位置,熱量傳感器的位置,空氣流等保持不變的情況下的溫度情況,得到如圖 11 熱圖所示的結果。從圖中可以看出,在現有制冷持續的情況下,部份區域會出現溫度過冷現象。基於該假設檢驗分析的結果,為了節約能量,我們可以把空調機組的制冷設定溫度升高 1 度,從而得到如圖 12 所示的熱圖。從圖中可以看出,保持現有設定不變情況下的過冷現象得到明顯改善。
圖 11. 保持現有設定不變的溫度熱圖
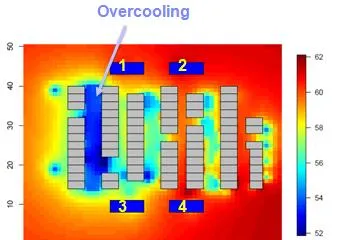
圖 12. 采取措施後的溫度熱圖
結束語
時空資料探勘是資料探勘中的重要研究內容,其中時空預測的套用領域最為廣泛。隨著資訊科技的發展,人們已經不滿足於單純的空間數據的儲存和展現,而是需要更先進的手段幫助理解空間數據的變化,發現空間數據之間的動態關系。實際上, 很多空間現象是隨時間動態變化的,在問題求解過程中需要同時考慮時間和空間兩方面因素。本文主要圍繞時空資料探勘的發展現狀及時空預測的分類,重點介紹基於時間和空間兩種內容的時空綜合預測方法,具體描述了該方法在 IBM SPSS Modeler 中的實作,並結合套用例項詳細說明如何套用時空數據建模及預測實作準確而有效的時空預測。
參考資源











