ChatGPT的爆火帶動了AIGC相關產業鏈的發展。也激發了大眾研究探索AI的熱情。本文主要介紹AI領域的一些基礎概念及技術。
AI :人工智慧 (artificial intelligence) 。屬於電腦科學領域,致力於解決與人類智慧相關的常見認知問題,例如學習、創造和影像辨識等。AI的目標是建立能從資料中取得有用知識的自學習系統。
AIGC :生成式人工智慧 (Adversarial Generative Intelligence) 。屬於機器學習的一個分支。是一種可以創造新內容和想法的人工智慧,包括創造對話、故事、圖片、視訊和音樂。ChatGPT和Sora等都是AIGC技術的一種套用。
AGI :通用人工智慧 (Artificial general intelligence) 。是指具有自主自控能力、合理的自我理解能力以及能夠學習新技能的AI系統。它可以處理人類未曾訓練過它的復雜問題。它可以在存在不確定性因素時進行推理,甚至使用策略來解決問題。同時具有制定決策的能力。也就是說它的智力水平是和人類相當甚至高於人類的。具有人類能力的AGI目前仍處於理論研究階段。
演算法 :演算法是一組明確的、有序的步驟或規則,用於解決特定問題或執行某項任務。它是電腦科學的核心概念之一,也是許多其他學科的基礎。演算法可以用來處理各種型別的數據和任務,從簡單的算術運算到復雜的數據分析和機器學習。
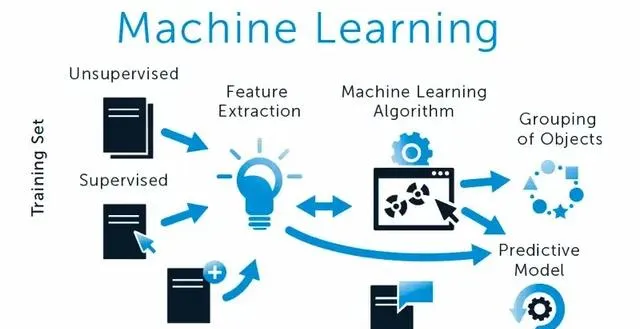
機器學習 :機器學習(Machine Learning,ML)是人工智慧(AI)的一個重要分支,它透過數據和演算法使電腦系統能夠自主學習和改進,而無需人為編程。機器學習的核心是開發能夠從數據中提取特征並做出預測或決策的演算法。機器學習又分為監督機器學習和無監督機器學習兩種。 兩者的區別即給出的用於學習的數據是否存在標簽。
常用的機器學習演算法有神經網路、線性回歸、邏輯回歸、聚類、決策樹、隨機森林等。目前用於開發機器學習相關演算法的機器學習框架主要有TensorFlow、PyTorch、Keras、PaddlePaddle等。
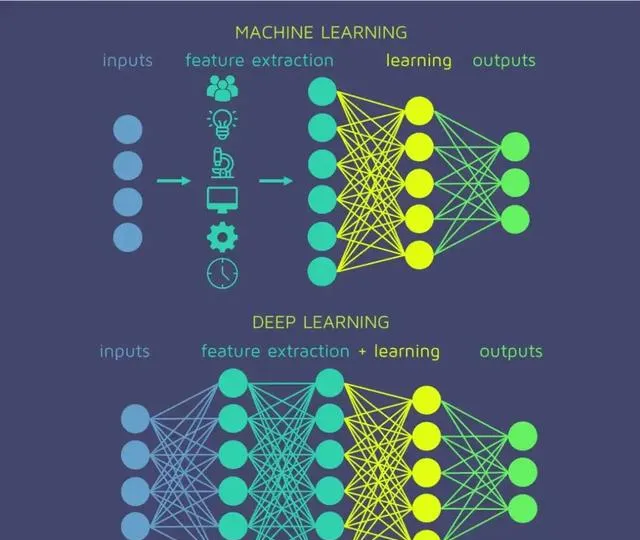
深度學習 :深度學習是機器學習的一個分支。許多傳統機器學習演算法學習能力有限,知識是從數據中獲取的,但是只是增加數據量並不能持續增加學到的知識總量。深度學習系統可以透過存取更多數據來提升效能,即「更多經驗」的機器代名詞。機器透過深度學習獲得足夠經驗後,即可用於特定的任務,如駕駛汽車、辨識田地作物間的雜草、確診疾病、檢測機器故障等。
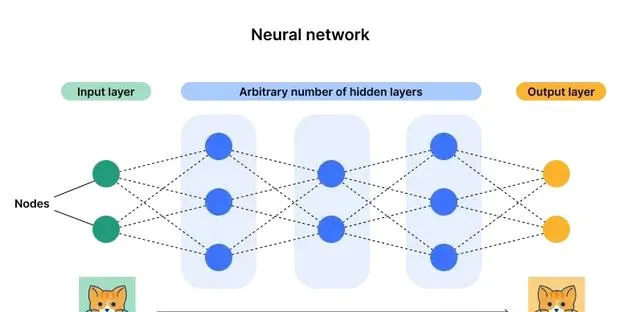
神經網路 :神經網路是一種機器學習程式或模型,它以類似於人腦的方式做出決策,透過使用模仿生物神經元協同工作方式的過程來辨識現象、權衡利弊並得出結論。
每個神經網路都由多個節點層或人工神經元組成 , 一個輸入層、一個或多個隱藏層和一個輸出層。每個節點都與其他節點相連,具有一個關聯的權重和閾值。如果任何單個節點的輸出高於指定的閾值,那麽該節點將被啟用,並將數據發送到網路的下一層。否則,不會將數據傳遞到網路的下一層。神經網路依靠訓練數據來學習並隨著時間的推移提高其準確性。一旦對其準確性進行微調,它們就會成為電腦科學和人工智慧領域的強大工具,使我們能夠高速對數據進行分類和聚類。與人類專家的人工辨識相比,人工智慧進行語音辨識或影像辨識只需幾分鐘,而人工辨識則需要幾小時。神經網路最著名的例子之一就是 Google 的搜尋演算法。
神經網路有時被稱為人工神經網路 (ANN) 或模擬神經網路 (SNN)。它們是機器學習的一個子集,是深度學習模型的核心。
NLP :自然語言處理(Natural Language Processing,NLP)是電腦科學和人工智慧的一個重要領域,旨在使電腦能夠理解、解釋、生成和響應人類自然語言。NLP結合了語言學、電腦科學和統計學的知識,以處理和分析大量自然語言數據,從而實作人機互動、文本分析等任務。

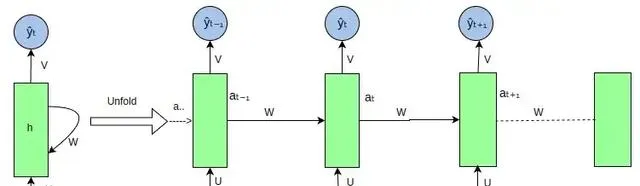
RNN :迴圈神經網路 (RNN) 是一種使用序列數據或時序數據的人工神經網路。這些深度學習演算法常用於順序或時間問題,如語言轉譯、自然語言處理 (nlp)、語音辨識、影像字幕等;它們包含在一些流行的套用中,比如 Siri、語音搜尋和 Google Translate。與前饋神經網路和摺積神經網路 (CNN) 一樣,迴圈神經網路利用訓練數據進行學習。區別在於「記憶」,因為它從先前的輸入中獲取資訊,以影響當前的輸入和輸出。雖然傳統的深度神經網路假設輸入和輸出相互獨立的,但迴圈神經網路的輸出依賴於序列中先前的元素。盡管未來的活動也可能有助於確定特定序列的輸出,但是單向迴圈神經網路無法在預測中說明這些事件。
大模型 :大模型 (large model) ,泛指參數很多的機器學習模型,大模型可以看作是數據轉換問題,即輸入 序列,輸出 序列,其中 = ,這裏的W矩陣就可以看作大模型必不可少的參數,這些參數可以影響模型的訓練效果和預測能力。根據場景不同,大部份大模型公司把大模型分為大語言模型、電腦視覺(包含影像和視訊)、音訊、多模態大模型四大類。
LLM :大語言模型(large language model)。是一種利用機器學習技術來理解和生成人類語言的人工智慧模型。LLM 使用基於神經網路的模型,通常運用自然語言處理(NLP)技術來處理和計算其輸出。目前比較知名的大語言模型有GPT-4、文心一言、通義千問等。

CV :電腦視覺 (Computer vision) 是指讓電腦和系統能夠從影像、視訊和其他視覺輸入中獲取有意義的資訊,並根據該資訊采取行動或提供建議。如果說人工智慧賦予電腦思考的能力,那麽電腦視覺就是賦予發現、觀察和理解的能力。

模型庫 :可以下載大模型的地方。如國外的Huggingface和國內的ModelScope
模型訓練 :模型訓練是機器學習中的一個重要步驟,它的作用是從給定的數據集中學習出一個模型,使得該模型能夠對新的數據進行準確的預測和分類。
模型推理 :模型推理是指使用訓練好的模型來進行預測、分類或回歸的過程。模型推理是機器學習的基礎,它允許我們使用模型來生成預測結果,給出對未知數據的估計值。在模型推理過程中,我們將訓練好的模型輸入新的數據,並使用模型產生預測結果。例如,在影像分類中,我們可以使用訓練好的摺積神經網路模型來對一張新的影像進行分類。
數據集 :又稱為資料集、數據集合或資料集合,是一種由數據所組成的集合。數據反映了真實世界的狀況。數據集作為深度學習和機器學習的輸入,對AI開發有至關重要的意義。
數據標註 :在機器學習中,數據標註流程用於辨識原始數據(圖片、文字檔案、視訊等)並添加一個或多個有意義的資訊標簽以提供下文,從而使機器學習模型能夠從它進行學習。例如,標簽可指示相片是否包含鳥或汽車、錄音中有哪些詞發音,或者 X 影像是否包含腫瘤。各種使用案例都需要用到數據標記,包括電腦視覺、自然語言處理和語音辨識。數據標註常用的工具有label-studio等。
pre-training :預訓練是一種無監督學習方法,模型透過大量無標簽數據進行訓練,以捕捉數據的底層結構和模式。在自然語言處理領域,預訓練模型通常會學習詞匯、語法和句子結構等基本特征。預訓練的目的是讓模型學會一定程度的通用知識,為後續的微調階段打下基礎。
微調 :微調是一種有監督學習方法,透過在有標簽數據上對預訓練模型進行進一步訓練,以適應特定的任務。這個過程使得模型能夠利用預訓練階段學到的通用知識,結合新數據的標簽資訊,使模型在特定任務上表現更好。
參考資料:https://www.ibm.com/cn-zh/topics?











