編輯:編輯部
【新智元導讀】 繼5月的檔泄露事件後,谷歌的搜尋引擎又被掀了個底朝天。不僅DeepMind發論文解釋了Vizier系統的機制,部落格作者Mario Fischer還對近百份文件做了徹底的調研分析,為我們還原了這個互聯網巨獸的全貌。
谷歌發表的論文又開始揭自家技術的老底了。
DeepMind高級研究科學家Xingyou (Richard) Song等人最近發表的論文中,解釋了谷歌Vizier服務背後的演算法秘密。

作為一個執行過數百萬次的黑盒最佳化器,Vizier幫助谷歌內部最佳化了很多研究和系統;同時,谷歌雲和Vertex也上線了Vizier服務,幫助研究者和開發人員進行超參數調整或黑盒最佳化。
Song表示,與Ax/BoTorch、HEBO、Optuna、HyperOpt、SkOpt等其他行業基線相比,Vizier在很多使用者場景中都有更穩健的表現,比如高維度、批查詢、多目標問題等。
趁著論文釋出,谷歌元老Jeff Dean也發推贊揚Vizier系統。

他提到的開源版Vizier已經托管在GitHub倉庫上,有非常詳細的文件說明,並且最近仍在持續維護更新。
倉庫地址:https://github.com/google/vizier
OSS Vizier 的分布式客戶端-伺服器系統
雖然谷歌研究院早在2017年就發文討論過整個Vizier系統,但內容遠沒有最新的這篇詳實。

論文地址:https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf
這篇技術報告包含了大量研究工作的成果和使用者反饋,在描述開源Vizier演算法的實作細節和設計選擇的同時,用標準化基準的實驗表現了Vizier在多種實用模式上的穩健性和多功能性。

論文地址:https://arxiv.org/abs/2408.11527
其中,Vizier系統叠代過程的經驗教訓也被一一展示,這對學界和行業都有很大的借鑒意義,值得一觀。
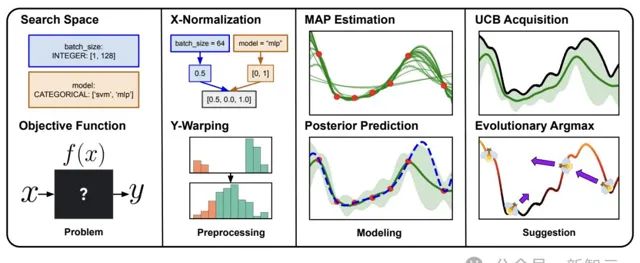
Vizier系統所用貝葉斯演算法的核心元件
文章的主要貢獻如下:
- 正式確認了Vizier目前版本的預設演算法並解釋其功能、設計選擇,以及整個叠代過程中吸取的經驗教訓
- 在原始的C++實作基礎上提供了開源的Python和JAX框架實作
- 使用行業通用基準進行測試,體現了Vizier在高維、分類、批次和多目標最佳化等模式下的穩健性
- 對零階前進演化采集最佳化器(zeroth-order evolutionary acquisition optimizer)這個非常規的設計選擇進行了消融實驗,展示並討論了其中的關鍵優勢
論文作者列表中排名前二的是兩個Richard——
Xingyou (Richard) Song曾在OpenAI擔任強化學習泛化方面的研究員,2019年以高級研究科學家的身份加入Google Brain,並從2023年起擔任DeepMind高級研究科學家,從事GenAI方面的工作。

Qiuyi (Richard) Zhang目前在DeepMind Vizier團隊中工作,也是開源版Vizier的共同建立者,他的研究主要關註超參數最佳化、貝葉斯校準和理論機器學習方向,此外在AI對齊、反事實/公平性等方面也有涉足。

2014年,Zhang以優秀畢業生的身份從普林斯頓大學獲得學士學位,之後在加州大學柏克萊分校獲得獲得套用數學和電腦科學的博士學位。
搜尋引擎機制大起底
作為絕對的行業巨頭,谷歌很多未被披露的核心技術都讓外界好奇已久,比如,搜尋引擎。
十多年來超過90%的市場份額,讓谷歌搜尋成為了或許是整個互聯網上最具影響力的系統,它決定了網站的生死存亡及網路內容的呈現形態。
但谷歌究竟是如何對網站進行排名的具體細節,從來都是「黑匣子」。
不像Vizier這類產品,搜尋引擎既是谷歌的財富密碼,也是看家技術,官方發論文披露是不可能的。
雖然也有媒體、研究人員以及從事搜尋引擎最佳化工作的人士進行過種種猜測,但也只是盲人摸象。
曠日持久的谷歌反壟斷訴訟最近宣布判決,美國的各級檢察官搜羅了約500萬頁的檔,變成公開的呈堂證供。
然而,谷歌內部文件泄露和反壟斷聽證會的公開檔等等,並沒有真正告訴我們排名的具體工作原理。
並且,由於機器學習的使用,自然搜尋結果的結構非常復雜,以至於參與排名演算法開發的谷歌員工也表示,他們並不能完全理解許多訊號權重的交互作用,無法解釋為什麽某個結果會排在第一或第二。
5月27日,一位匿名訊息人士(後證實為搜尋引擎最佳化行業資深從業者Erfan Azimi)曾向SparkToro公司的CEO Rand Fishkin提供 了一份2500頁的谷歌搜尋API泄露文件,揭示了谷歌搜尋引擎內部排名演算法的詳細資訊 。

但這還不是全部。
專門報道搜尋引擎行業的新聞網站Search Engine Land最近還發表了一篇部落格,根據數千份泄露的谷歌法庭檔進行逆向工程,首次揭秘谷歌網路搜尋排名的核心技術原理。

原文連結:https://searchengineland.com/how-google-search-ranking-works-445141
這篇博文是原作者在幾周的工作中對近100份文件經過多次檢視、分析、結構化、丟棄和重組之後才誕生的,雖然並不一定嚴格準確或面面俱到,但可以說是了解谷歌搜尋引擎絕無僅有的全面且詳細的資料。
作者的省流版結構示意圖如下:
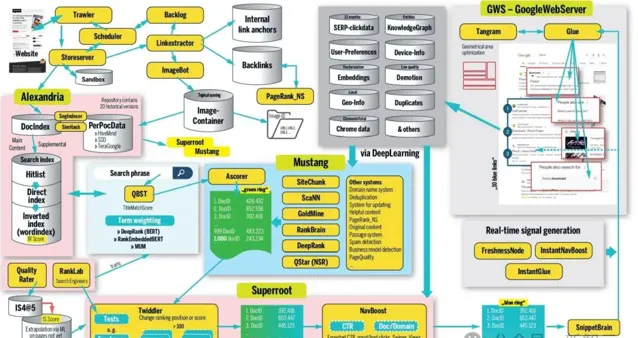
毫無疑問,谷歌搜尋引擎是一個龐大而復雜的工程。從爬蟲系統、儲存庫Alexandria、粗排名Mustang,再到過濾和細排名系統Superroot以及負責最終呈現頁面的GWS,這些都會影響網站頁面最終的呈現和曝光。
新檔:等待Googlebot存取
當一個新網站釋出時,它不會立刻被谷歌索引,谷歌如何透過收集和更新網頁資訊呢?
第一步就是爬蟲和數據收集,谷歌首先需要知道該網站URL的存在,網站地圖的更新或放置URL連結可以讓谷歌抓取到新網站。
並且,頻繁被存取的頁面連結能更快地引起谷歌的註意。
爬蟲系統(trawler system)會抓取新內容,並記錄何時重新存取URL以檢查網站更新,這由一個稱為排程器的元件管理。
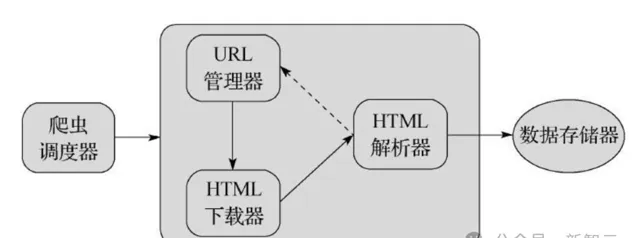
接著,儲存伺服器決定是否轉發該URL或是否將其放到沙箱(sandbox)中。
谷歌之前一直否認沙箱的存在,但最近的泄露資訊表明,(可疑的)垃圾網站和低價值網站也會被放入沙箱,谷歌顯然會轉發一些垃圾網站,可能是為了進一步分析內容和訓練演算法。
然後,影像連結被傳輸到ImageBot中,以便後續的搜尋呼叫,有時會出現延遲的情況,ImageBot有分類功能,能夠將相同或相似的圖片放置在一個影像容器中。
爬蟲系統似乎使用自己的PageRank來調整資訊抓取頻率,如果一個網站的流量更大,這個抓取頻率就會增加(ClientTrafficFraction)。
Alexandria:谷歌索引系統
谷歌的索引系統被稱為Alexandria,為每個網頁內容分配唯一的DocID。如果出現內容積比重復的情況,則不會建立新的ID,而是將URL連結到已有的DocID。
谷歌會明確區分URL和文件:一個文件可以由多個包含相似內容的URL構成,包括不同語言版本,所有這些URL都由同一個DocID進行呼叫。
如果碰到不同網域名稱的重復內容,谷歌會選擇在搜尋排名中會顯示規範版本。這也解釋了為什麽其他的URL有時可能會有相似的排名。並且,所謂「規範」版本的URL也不是一錘子買賣,而是會隨著時間發生變化。

Alexandria收集文件的URL
作者的文件在網上只有一個版本,因此它被系統賦予了自己的DocID。
有了DocID之後,文件的各個部份都會搜尋出關鍵詞並匯總到搜尋索引(search index)中。「熱詞列表」(hit list)中匯總了每頁多次出現的關鍵詞,會先被發送到直接索引(direct index)中。
以作者的網頁為例,由於其中多次出現「pencil」一詞,在詞匯索引(word index)中,DocID就列在「pencil」條目下。
演算法會根據各種文本特征計算出文件中「鉛筆」一詞的IR(資訊檢索)分數並分配給DocID,稍後用於釋出列表(Posting List)。
比如,文件中「pencil」一詞被加粗,並包含在一級標題中(儲存在AvrTermWeight中),這類訊號都會增加IR得分。
谷歌會將重要的文件移至HiveMind,即主記憶體系統,同時使用快速SSD和傳統HDD(稱為TeraGoogle)來長期儲存不需要快速存取的資訊。
值得註意的是,專家估計,在最近的AI熱潮之前,谷歌掌握了全球約半數的網路伺服器。
一個龐大的互聯集群網路能夠讓數百萬個主記憶體單元一起工作,一位谷歌工程師曾在一次會議上指出,理論上,谷歌的主記憶體可以儲存整個網路。
有趣的是,儲存在HiveMind中的重要文件的連結以及反向連結似乎有更高的權重,而HDD(TeraGoogle)中的URL連結可能權重較低,甚至可能不被考慮。
每個DocID的附加資訊和訊號都以動態方式儲存在PerDocData中,這個儲存庫保存了每個文件最近的20個版本(透過CrawlerChangerateURLHistory),許多系統在調整相關性時都會存取這些資訊。
並且,谷歌有能力隨著時間變化評估不同的版本。如果想要完全更改文件的內容或主題,理論上需要建立20個過渡版本來完全覆蓋掉舊的版本。
這就是為什麽恢復一個過期網域名稱(一個曾經活躍,但之後由於破產或其他原因被放棄或出售的網域名稱)不會保留原來網域名稱的排名優勢。
如果一個網域名稱的Admin-C和其主題內容同時發生變化,機器可以輕松辨識出這一點。
此時,谷歌會將所有訊號置零,曾經有流量價值的舊網域名稱不再提供任何優勢,與全新註冊的網域名稱無異,接手舊網域名稱並不意味著接手原本的流量和排名。

除了泄密事件之外,美國司法機構針對谷歌的聽證會和審判的證據檔也是有用的研究來源,甚至包含內部電子信件
QBST:有人在搜尋「pencil」
當有人在谷歌中輸入搜尋詞「pencil」時,QBST(Query Based Salient Terms)開始工作。
QBST負責分析使用者輸入的搜尋詞,根據重要性和相關性為其中包含的各個詞語分配不同的權重,並分別進行相關DocID的查詢。

詞匯加權過程相當復雜,涉及RankBrain、DeepRank(前身為BERT)和RankEmbeddedBERT等系統。
QBST對於SEO很重要,因為它會影響Google對搜尋結果的排名,從而影響網站可以獲得多少流量和可見度。
如果網站包含與使用者查詢匹配最常用的術語,QBST就會讓網站排名更高。
經過QBST後,相關詞匯如「pencil」,會被傳遞給Ascorer做進一步處理。
Ascorer:建立「綠環」
Ascorer從倒排索引(即詞匯索引)中提取「pencil」條目下的前1000個DocID,按IR得分排名。
根據內部檔,這個列表稱為「綠環」。在業內,這被稱為釋出列表(posting list)。
在我們關於「鉛筆」例子中,相應文件在釋出列表中排名第132位元。如果沒有其他系統的介入,這將是它的最終位次。
Superroot:「千裏挑十」
Superroot負責對剛剛Mustang篩選出的1000個候選網頁重新排名,將1000個DocID的「綠環」縮減為10個結果的「藍環」。
這個任務具體由Twiddlers和NavBoost執行,其他系統可能也有參與,但由於資訊不準確,具體細節尚不清楚。
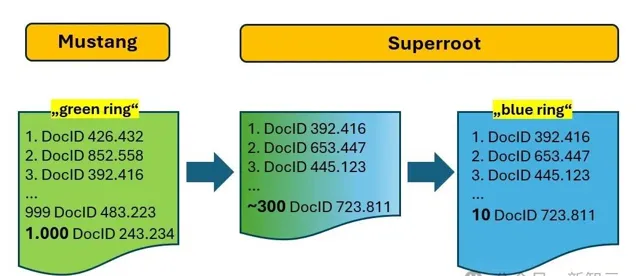
Mustang生成1000個潛在結果,Superroot將其過濾為10個
Twiddlers:層層過濾
各種檔表明,谷歌使用了數百個Twiddler系統,我們可以將其視為類似於WordPress外掛程式中的過濾器。
每個Twiddler都有自己特定的過濾目標,可以調整IR分數或者排名位次。
之所以用這種方式設計,是因為Twiddler相對容易建立,而且無需修改 Ascorer中復雜的排名演算法。
排名演算法的修改非常具有挑戰性,因為涉及潛在的副作用,需要大量的規劃和編程。相反,多個Twiddler並列或順序操作,並不知道其他Twiddler的活動。
Twiddler基本可以分為兩種型別:
-PreDoc Twiddlers可以處理幾百個DocID的集合,因為它們幾乎不需要額外的資訊;
-相反,「Lazy」型別的Twiddler需要更多的資訊,例如來自PerDocData資料庫的資訊,需要相對更長的時間和更復雜的過程。
因此,PreDocs先接收釋出列表並減少網頁條目,然後再使用較慢的「Lazy」型別的過濾器,兩者結合使用大大節省了算力和時間。
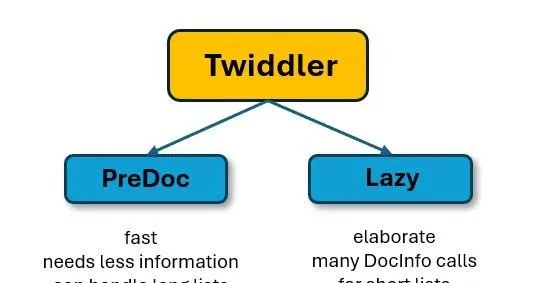
兩種型別的、超過100個Twiddler負責減少潛在的搜尋結果數量並重新排序
經過測試,Twiddler有多種用途,開發者可以嘗試使用新的過濾器、乘數或特定位置限制,甚至可以做到非常精準的操控,將一個特定的搜尋結果排名到另一個結果的前面或後面。
谷歌的一份泄露的內部檔顯示,某些Twiddler功能應僅由專家與核心搜尋團隊協商後使用。

如果您認為自己了解Twidder的工作原理,請相信我們:您不了解。我們也不確定自己是否了解
還有一些Twiddlers僅用於建立註釋,並將這些註釋添加到DocID中。
在COIVD期間,為什麽你所在國家的衛生部門在COVID-19搜尋中總是排在第一位?
那正是因為Twiddler會根據語言和地區,使用queriesForWhichOfficial來促進官方資源的精確分配。
雖然開發者無法控制Twiddler重新排序的結果,但了解其機制可以更好地解釋排名波動和那些「無法解釋的排名」。
品質評估員和RankLab實驗室
全球範圍內有數千名品質評估員負責為谷歌評估搜尋結果,對新演算法或過濾器進行上線前的測試。
谷歌表示,他們的評分僅供參考,不會直接影響排名。
這本質上是正確的,但他們的評分和投標票的確對排名產生了極大的間接影響。
評估員通常在行動裝置上進行評估,從系統接收URL或搜尋短語,並回答預設的問題。
例如,他們會被問到,「這篇內容作者和創作實踐是否清晰?作者是否擁有該主題的專業知識?」
這些答案會被儲存起來並用於訓練機器學習演算法,讓演算法能夠更好地辨識高品質、值得信賴的頁面,和不太可靠的頁面。
也就是說,人類評估者提供的結果成為深度學習演算法的重要標準,谷歌搜尋團隊建立的排名標準反而沒那麽重要。
想象一下,什麽樣的網頁會讓人類評估者覺得可信?
如果某個網頁包含作者的照片、全名和LinkedIn連結,通常會顯得令人信服。反之,缺乏這些特征的網頁會被判定為不那麽可信。
接著,神經網路將辨識這一特征為關鍵因素,經過至少30天的積極測試執行,模型可能開始自動將此特征用作排名標準。
因此,具有作者照片、全名和LinkedIn連結的頁面可能會透過Twiddler機制獲得排名提升,而缺乏這些特征的頁面則會出現排名下降。
另外,根據谷歌泄露的資訊,透過isAuthor內容和AuthorVectors內容(類似於「作者指紋辨識」),可以讓系統辨識並區分出作者的獨特用詞和表達方式(即個人語言特征)。
評估員的評價被匯總成「資訊滿意度」(IS)分數。盡管有許多評估員參與,但IS評分僅適用於少數URL。
谷歌指出,許多沒有被點選的文件可能也很重要。當系統無法進行推斷時,文件會被自動發送給評估員並生成評分。
評估員相關的術語中提到了「黃金」,這表明某些文件可能有一個「黃金標準」,符合人類評估員的預期可能有助於文件達到「黃金」標準。
此外,一個或多個Twiddler系統可能會將符合「黃金標準」的DocID推進排名前十。
品質評估員通常不是谷歌的全職員工,而是隸屬於外包公司。
相比之下,谷歌自己的專家在RankLab實驗室中工作,負責進行實驗、開發新的Twiddler以及進行評估和改進,看Twiddler能否提高結果品質還是僅僅只能過濾掉垃圾信件。
經過驗證並有效的Twiddler隨後被整合到Mustang系統中,使用了復雜、互連且計算密集型的演算法。
NavBoost:使用者喜歡什麽?
在Superroot中,另一個核心系統NavBoost在搜尋結果排名方面也發揮著重要作用。

Navboost主要用於收集使用者與搜尋結果互動的數據,特別是他們對不同查詢結果的點選量。
盡管谷歌官方否認將使用者點選數據用於排名,但聯邦貿易委員會(FTC)披露的一封內部電子信件指示,點選數據的處理方式必須保密。
谷歌對此進行否認涉及兩方面的原因。
首先,站在使用者的角度來看,谷歌作為搜尋平台無時無刻監視使用者的線上活動,這會引起媒體對於私密問題的憤怒。
但站在谷歌的角度來看,使用點選數據是為了獲得具有統計意義的數據指標,而不是監控單個使用者。
FTC檔確認了點選數據將會影響排名,並頻繁提到NavBoost系統(在2023年4月18日的聽證會上提到54次),2012年的一次官方聽證會也證明了這一點。

自2012年8月起,官方明確表示點選數據會影響排名
搜尋結果頁面上的各種使用者行為,包括搜尋、點選、重復搜尋和重復點選,以及網站或網頁的流量都會影響排名。
對使用者私密的擔憂只是原因之一。另一種擔憂是,透過點選數據和流量進行評估,可能會鼓勵垃圾信件發送者和騙子使用機器人系統偽造流量來操縱排名。
谷歌也有反制這種情況的方法,例如透過多方面的評估將使用者點選區分為不良點選和良好點選。
所使用的指標包括在目標頁面的停留時間、在什麽時間段檢視網頁、搜尋的起始頁面、使用者搜尋歷史中最近一次「良好點選」的記錄等等。
對於每個在搜尋結果頁面(SERPs)中的排名,都有一個平均預期點選率(CTR)作為基準線。
例如,根據Johannes Beus在今年柏林CAMPIXX大會上的分析指出,自然搜尋結果的第1位平均獲得26.2%的點選,第2位獲得15.5%的點選。
如果一個CTR顯著低於預期的比率,NavBoost系統會記錄下這一差距,並相應地調整DocID的排名。
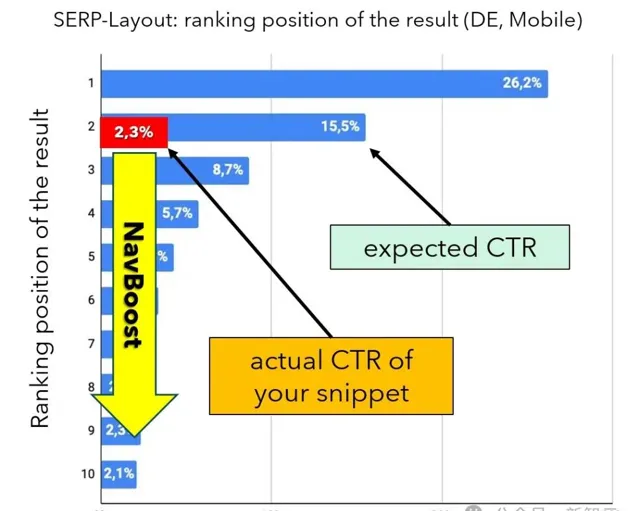
如果「expected_CRT」與實際值偏差較大,則排名會相應調整
使用者的點選量基本上代表了使用者對結果相關性的意見,包括標題、描述和網域名稱。
根據SEO專家和數據分析師的報告,當全面監控點選率時,他們註意到了以下現象:
如果一個文件在搜尋查詢中進入前10名,而CTR顯著低於預期,可以觀察到排名將在幾天內下降(取決於搜尋量)。
相反,如果CTR相對於排名來說高得多,排名通常會上升。如果CTR較差,網站需要在短時間內調整和最佳化標題和內容描述,以便獲得更多的點選。
計算和更新PageRank是耗時且計算密集的,這就是使用PageRank_NS指標的原因。NS代表「最近的種子」,一組相關頁面共享一個PageRank值,該值暫時或永久地套用於新頁面。
谷歌在一次聽證會上就如何提供最新資訊樹立了一個良好典範。例如,當使用者搜尋「史坦利杯」時,搜尋結果通常會顯示一個水杯。
然而,當史坦利杯冰球比賽正在進行時,NavBoost會調整結果以優先顯示關於比賽的即時資訊。
根據最新發現,文件的點選指標包含了13個月的數據,有一個月的重疊,以便與前一年進行比較。
出乎意料的是,谷歌實際上並沒有提供太多個人化的搜尋結果。測試結果已經表明,對使用者行為進行建模並調整,比評估單個使用者的個人偏好更能帶來優質的結果。
然而,個人偏好,例如對搜尋和視訊內容的偏好,仍然包含在個人化結果中。
GWS:搜尋的結尾和開端
谷歌網路伺服器(GWS)負責呈現搜尋結果頁面(SERP),包括10個「藍色連結」,以及廣告、圖片、Google地圖檢視、「People also ask」和其他元素。

FreshnessNode、InstantGlue(在24小時內反應,延遲約10分鐘)和InstantNavBoost等這些元件可以在頁面顯示前的最後時刻調整排名。
FreshnessNode可以即時監測使用者搜尋行為的變化,並根據這些變化調整排名,確保搜尋結果與最新的搜尋意圖匹配。
InstantNavBoost和InstantGlue在最終呈現搜尋結果之前,對排名進行最後的調整,例如根據突發新聞和熱門話題調整排名等。
因此,要想取得高排名,一個優秀的文件內容還得加上正確的SEO措施。
排名可能會受到多種因素的影響,包括搜尋行為的變化、其他文件的出現和即時資訊的更新。因此,必須認識到,擁有高品質的內容和做好SEO只是動態排名格局中的一部份。
谷歌的John Mueller強調,排名下降通常並不意味著內容品質不佳,使用者行為的變化或其他因素可能會改變結果的表現。
例如,如果使用者開始偏好更簡短的文本,NavBoost將自動相應地調整排名。然而,Alexandria系統或Ascorer中的IR分數是保持不變的。
這告訴我們,必須在更廣泛的意義上理解SEO。如果文件內容與使用者搜尋意圖不一致,僅僅最佳化標題或內容是無效的。
參考資料:
https://searchengineland.com/how-google-search-ranking-works-445141
https://arxiv.org/abs/2408.11527











