當地時間 7 月 23 號,Meta 公司釋出了迄今為止最強大的開源 AI 模型 Llama 3.1。該模型不僅規模龐大,效能也堪比最強大的閉源模型。這稱得上是開源 AI 領域的一個重要裏程碑。
Llama 3.1 模型家族總共有三個版本,規模最大的旗艦版本擁有 405B(4050 億)參數,是近年來最大的開源 AI 模型。其余兩個較小版本的參數量分別是 700 億和 80 億。
Meta 聲稱,Llama 3.1 405B 模型在多項基準測試中的表現超過了 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet。
「到目前為止,開源大型語言模型在功能和效能方面大多落後於閉源模型。現在,我們正迎來一個由開源引領的新時代。」
Meta 在官方部落格中寫道,「迄今為止,所有 Llama 版本的總下載量已超過 3 億次,而這僅僅是個開始。」
(來源:Meta)

模型評估
據介紹,Llama 3.1 系列模型展現了多方面的能力提升,在常識、可操縱性、數學、工具使用和多語言轉譯等功能方面可與頂級 AI 模型相媲美。
Meta 對 Llama 3.1 進行了全面的評估,包括超過 150 個基準數據集的測試,涵蓋多種語言和任務型別。
此外,該模型還經過了廣泛的人工評估,與競爭模型在真實套用場景中進行比較。
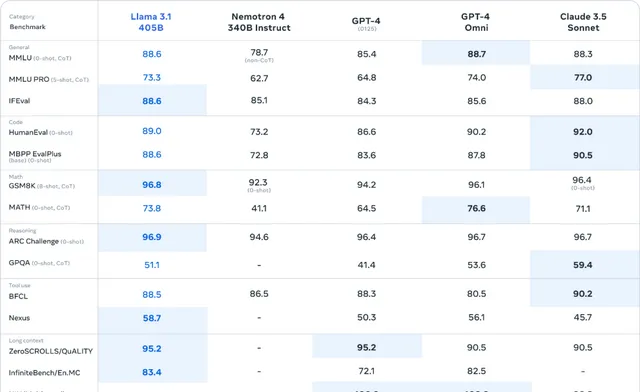
圖 | 模型評估結果(來源:Meta)
總體而言,Llama 3.1 405B 模型在推理、數學等多項任務中的表現與 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 相當,在長文本、多語言等領域甚至更勝一籌。
不過在程式碼基準測試中,Llama 3.1 405B 模型的表現不如 Claude 3.5 Sonnet。
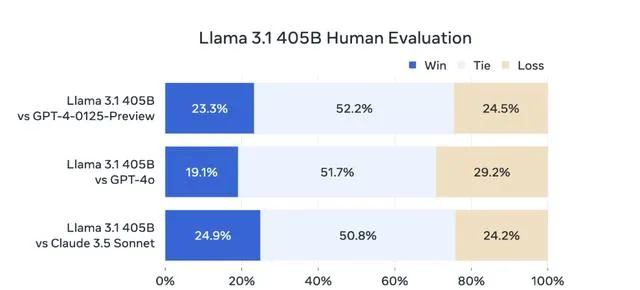
圖 | 模型評估結果(來源:Meta)
此外,在小型模型效能對比中,Llama 3.1 的 8B 和 70B 模型均表現出色,與同等規模的閉源和開源模型相比具有很強的競爭力,在幾乎所有測試中都打敗了對手。
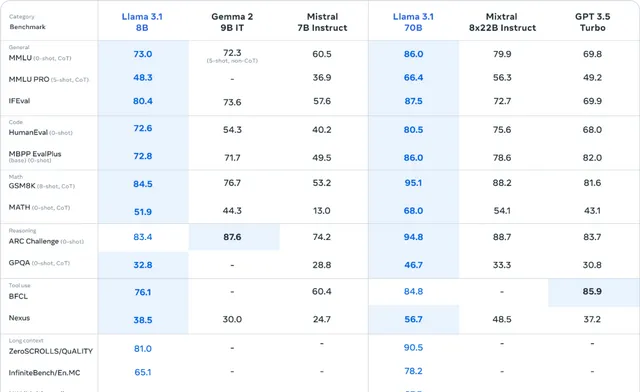
圖 | 模型評估結果(來源:Meta)

模型能力與套用
Meta 表示,Llama 3.1 系列模型的上下文視窗達到了 128K,相當於一本 50 頁的書,並且提供英語、德語、法語、義大利語、葡萄牙語、印地語、西班牙語和泰語等多語言支持,大大提升了長文本和多語種內容的處理能力。
Meta 生成式人工智慧副總裁艾哈邁德·達爾(Ahmad Al-Dahle)表示,Llama 3.1 模型能夠整合搜尋引擎應用程式編程介面(API,Application Programming Interface),根據復雜查詢從互聯網檢索資訊,並呼叫多個工具完成任務。例如,它可以生成並執行 Python 程式碼來繪制圖表。
不過,Llama 3.1 目前還不是多模態模型,僅支持文本輸入。但 Meta 表示,正在開發能辨識影像、視訊,並理解(和生成)語音的 Llama 模型。
在套用方面,與之前的 Llama 模型一樣,Llama 3.1 405B 可在亞馬遜 AWS、微軟 Azure 和谷歌 Cloud 等雲平台上下載或使用。它還會與 Meta 的產品結合,為使用者提供聊天機器人和資訊查詢等服務。
該模型目前已經用在 Meta.ai 和 Meta AI 虛擬助手上。從本周開始,Llama 3.1 將首先登陸 WhatsApp 和美國的 Meta.ai 網站,隨後幾周將上線 Instagram 和 Facebook。
雖然最先進的 Llama 3.1 405B 模型可以在 Meta.ai 上免費使用,但每周提示數量有限(上限不詳),超過限制則會切換到更小的 70B 模型。這似乎表明 405B 模型對於 Meta 來說還是太昂貴了,無法全面執行。

模型規模與訓練
Llama 3.1 405B 模型的訓練規模令人驚嘆。
Meta 使用了超過 1.6 萬個輝達 p00 GPU,在超過 15 萬億個 tokens(的數據集)上進行訓練,相當於 7500 億個單詞。
盡管 Meta 沒有透露具體的開發成本,但僅根據其使用的輝達芯片價格估算,成本就已高達數億美元。
Meta 對其整個訓練堆疊進行了重大最佳化,以達到如此大規模的訓練目標。
在模型架構方面,他們選擇了標準的僅解碼器 transformer 模型,而非混合專家模型,以最大化訓練穩定性。
訓練數據方面,Meta 透過改進處理和數據篩選流程,提高了訓練數據的品質。
此外,他們還選取了叠代式的後訓練程式,「每輪都使用監督微調和直接偏好最佳化,用高品質的合成數據不斷提升模型效能」。

開源策略與生態系
盡管開發成本高昂,Meta 仍堅持開源 Llama 模型。
Meta 的 CEO 馬克·祖克柏(Mark Zuckerberg)在公開信中表示,相比專有模型,開源 AI 模型終將超越它們,並且已經在以更快的速度改進,最終和 Linux 一樣,成為支持大多數手機、伺服器和裝置的開源作業系統。
他預測,「Llama 3.1 的釋出將成為行業的一個轉折點,未來大多數開發者更青睞於使用開源模型。」

圖 | 祖克柏的公開信(來源:Meta)
為了推廣 Llama 3.1,Meta 正與包括微軟、亞馬遜、谷歌、輝達和 Databricks 在內的 20 多家公司合作,幫助開發者部署自己的模型。
Meta 聲稱,Llama 3.1 在生產環境中的執行成本僅為 OpenAI 的 GPT-4o 的一半左右。
與此同時,Meta 更新了 Llama 的授權條款,讓開發者可以透過 Llama 3.1 模型的輸出,來開發第三方 AI 模型。
這一變化解決了 AI 社群對 Meta 模型的一個主要批評,是公司積極爭取 AI 領域話語權的一部份。
此外,為了確保模型的安全性和道德性,Meta 首次在 Llama 3.1 的「紅隊測試」(對抗性測試)中包括了潛在的網路安全和生物化學用例。
他們還公開了一個完整的參考系統,其中包括多個範例應用程式和新元件,如多語言安全模型 Llama Guard 3 和提示註入過濾器 Prompt Guard。
然而,關於訓練數據的問題仍然存在爭議。Meta 拒絕透露具體的數據來源,只表示使用了合成數據來改進模型。
總而言之,Llama 3.1 系列模型的釋出,象征著開源 AI 模型在效能上第一次和頂級閉源模型相匹敵。這可能會對 AI 行業產生深遠影響,推動更多創新和套用。
參考資料:
https://ai.meta.com/blog/meta-llama-3-1/
https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/
https://www.theverge.com/2024/7/23/24204055/meta-ai-llama-3-1-open-source-assistant-openai-chatgpt
https://techcrunch.com/2024/07/23/meta-releases-its-biggest-open-ai-model-yet/
營運/排版:何晨龍











