源自:自動化學報
作者:張凱, 楊朋澄, 彭開香, 陳誌文
「人工智慧技術與咨詢」 釋出
摘要
傳統的多模態過程故障等級評估方法對模態之間的共性特征考慮較少, 導致當被評估模態故障資訊不充分時, 評估的準確性較低. 針對此問題, 首先, 提出一種共性–個性深度置信網路 (Common and specific deep belief network, CS-DBN), 該網路充分利用深度置信網路 (Deep belief network, DBN) 的深度分層特征提取能力, 透過度量多模態數據間分布的相似性和差異性, 進一步得到能夠反映多模態過程共有資訊的共性特征以及反映每個模態獨有資訊的個性特征; 其次, 基於CS-DBN, 利用多模態過程的已知故障等級數據生成多模態共性–個性特征集, 透過加權邏輯回歸構建故障等級評估模型; 最後, 將所提方法套用於帶鋼熱連軋生產過程的故障等級評估中. 套用結果表明, 隨著多模態故障等級數據的增加, 所提方法的評估準確率逐漸增加, 當故障資訊充足時, 評估準確率可達98.75%; 故障資訊不足時, 與傳統方法相比, 評估準確率提升近10%.
關鍵詞
多模態過程 / 故障等級評估 / 共性–個性特征 / 深度置信網路 / 帶鋼熱連軋
現代復雜工業過程的大規模連續生產給制造業帶來高效益的同時也增大了事故風險. 由於工業過程中的控制回路、過程變量相互耦合, 一個部位的異常變化可能會隨著傳播不斷演變, 微小的故障也可能引起更嚴重的故障[1]. 因此, 準確判斷系統的故障程度並按照故障程度的不同調整生產決策和控制策略, 能夠提高生產的高效性和產品品質的穩定性. 目前, 工業過程故障等級評估方法已在有色金屬[2]、化工[3]、電力[4]、高鐵[5]、船舶[6]等行業成功套用, 並取得良好效果.
隨著工業自動化與數據儲存技術的快速發展, 基於數據驅動的故障等級評估方法被提出和廣泛套用[7-9], 如多元統計分析、機器學習、深度學習等. 常用的多元統計分析方法包括主元分析 (Principal component analysis, PCA)[10]、偏最小平方 (Partial least squares, PLS)[11]及其拓展方法等, 這些特征提取方法透過將高維數據投影到低維空間來提取關鍵資訊, 並用於進一步的故障評估研究. 隨著人工智慧的發展, 支持向量機 (Support vector machine, SVM)[12]、判別分析 (Fisher discriminant analysis, FDA)[13]等典型機器學習方法被廣泛套用, 這類方法透過建立過程數據與評估指標之間的對映關系來實作故障評估. 其中, SVM透過高維空間對映尋找最優分類超平面, 而FDA透過降維投影建立判別函式. 然而, 這些方法大多局限於淺層學習, 可能無法很好地處理非線性耦合數據, 在故障評估中常與其他特征選擇和提取方法相結合. 近年來, 深度學習因其能夠自動提取大規模非線性數據的深層特征而被廣泛研究與套用, 如摺積神經網路 (Convolutional neural network, CNN)[14]、堆疊自動編碼器 (Stacked auto-encoder, SAE)[15] 和深度置信網路 (Deep belief network, DBN)[16]等. 其中, DBN透過數據的機率分布來提取高層表示, 與其他網路相比, DBN兼具生成模型和判別模型雙重內容, 具有模型結構簡單、訓練難度小、易於拓展等優點. 目前, DBN已在影像處理、語音辨識、醫學診斷等任務中得到了廣泛的關註和研究[17].
上述特征提取方法側重於建立單模態的故障評估模型. 然而, 實際過程中往往存在多種工作模態, 操作條件的變化、產品規格的多樣性等使工業過程執行工況復雜多變, 傳統的單模態故障等級評估方法難以有效地提取和分析潛在的多模態數據特征, 需要構建適用於多模態過程的特征提取模型和評估指標. 一類常見的方法是將PCA、PLS等基於多元統計的方法擴充套件至多模態. 例如, 文獻[18] 利用多空間PCA獲取不同模態的獨立特征, 根據投影位置來評估線上過程執行狀態, 並綜合經濟指標來劃分效能等級. 文獻[19] 采用最小體積橢圓自適應地對各模態特征變異數的子空間進行建模, 並根據子空間之間的距離設計評估退化指標. 文獻[20] 將經濟指標資訊融入到慢特征分析中, 協同感知復雜工業過程的靜–動態特性變化, 實作了對執行狀態的綜合評價. 為了提高對具有非線性、動態性多模態過程的處理能力, 一些基於機率的評估框架被提出, 如貝葉斯網路 (Bayesian network, BN)[21]、高斯混合模型 (Gaussian mixture model, GMM)[22]等. 盡管上述方法在一定程度上解決了非線性問題, 但每個模態中仍存線上性假設, 影響了評估的準確性. 當面對復雜的非線性和高維變量時, 深度學習表現出更好的潛力, 基於深度學習的評估模型受到越來越多的研究. 文獻[23] 提出了基於條件生成對抗網路的多模態影像品質評估方法, 以平均意見分數建立評估指標, 透過雙鍊結自編碼器 (Autoencoder, AE) 提取兩個模態不同深度的特征, 並在註意力機制的監督下進行分層融合特征. 文獻[24] 針對多模態過程建立多個AE模型, 並將資料壓縮到一個共同的更小的潛在空間後進行跨模態重構, 充分利用了故障資訊. 文獻[25]提出一種基於DBN的主動遷移學習方法, 透過DBN挖掘輸入特征與暫態評估結果之間的非線性對映關系, 並結合主動遷移方法提高了線上套用的快速性和魯棒性.
現有的多模態過程故障等級評估方法針對不同的執行模態分別建立評估模型, 僅考慮在所有模態的故障等級數據均已知條件下如何透過最佳化學習網路來提高評估的準確率, 未考慮在某些執行模態各種故障等級資訊未知下如何改進和最佳化演算法. 並且大部份方法只關註各模態數據的獨有特征, 缺少對各模態間共性特征的建模與分析. 實際上, 盡管模態在進行切換, 但並不是所有變量的相關性都隨模態切換發生改變, 一些多模態過程具有明顯的共同資訊. 例如, 在帶鋼熱連軋過程生產不同規格板帶時, 上遊機架軋制力和輥縫變量遵循相似的軌跡, 而彎輥力變量往往表現出不同的特性. 因此, 分別提取多模態過程的共性特征和各執行模態的個性特征[26], 並根據故障對共性特征和個性特征的影響構建評估模型, 可透過共性特征實作對部份模態缺失資訊的補充, 提高多模態過程故障評估的準確性. 本文的故障等級評估方法示意圖如圖1所示.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
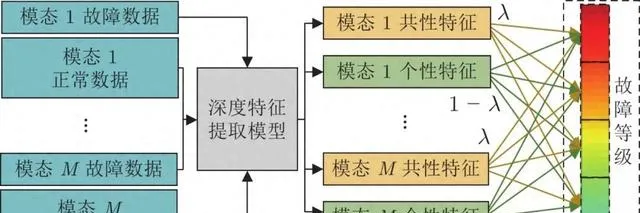
圖 1 融合共性–個性特征的故障評估方法示意圖
針對多模態過程的故障等級評估問題, 本文以DBN為特征提取基礎模型並進行深層次拓展, 提出了一種基於共性–個性深度置信網路 (Common and specific deep belief network, CS-DBN) 的故障等級評估方法. 首先, 針對多模態過程數據, 構建一種CS-DBN模型來提取模態間的共性特征和個性特征; 其次, 提出融合共性–個性特征的故障等級評估方法, 考慮到兩種特征對每個等級指標的重要性不同, 給共性–個性特征分配不同的權重因子; 最後, 將所提方法套用到帶鋼熱連軋過程中, 利用實際過程數據驗證所提方法的有效性.
1. 問題提出與基本思路
本節以熱連軋過程故障等級評估為例, 介紹問題的提出與基本思路. 圖2 展示了3種規格帶鋼生產過程中第2機架軋制力的采樣數據, 若把3種規格帶鋼生產過程視為3種執行模態, 可以看出, 3種模態的軋制力數據具有共性, 即開始軋制階段呈現上升趨勢. 另外, 它們還有各自的獨有特征, 如模態3軋制力增長到一定程度就趨於穩定, 而另外兩個模態軋制力分別呈現持續增長和持續下降的特征. 傳統故障等級評估方法大多根據故障的大小判斷故障等級, 忽視了故障對變量變化趨勢等深層次特征的影響, 因此容易出現誤評估情況. 以軋制力故障為例, 該種故障在熱連軋過程中屬於較為嚴重的故障, 3種模態的軋制力故障下的軋制力數據如圖3所示. 若已知模態1和模態3的軋制力故障數據, 利用訓練好的評估模型評估模態2的故障等級, 如圖3所示, 由於模態1和模態3所訓練的評估模型並不能完全覆蓋到模態2故障數據的全部資訊, 因此傳統方法容易將該故障錯評為一般故障或者正常. 若利用模態2的故障數據提取共性特征, 如圖3所示, 該故障對共性特征的影響較大, 利用模態1和模態3共性特征訓練好的評估模型可將此故障正確地評估為嚴重故障. 彎輥力故障也是熱連軋過程經常發生的故障, 當彎輥力發生異常後, 會間接影響軋制力的動態設定, 該故障對帶鋼產品的厚度影響較小, 常被當做輕微的故障. 圖4 給出了3種模態彎輥力故障下的數據曲線, 如果利用模態1和模態2的故障數據訓練評估模型並評估模態3的故障等級, 由於模態3的故障數據範圍已經超越了模態1和模態2的故障數據範圍, 傳統的評估方法易將該故障誤評為嚴重故障. 而如果利用模態3故障數據提取的共性特征來評估, 如圖4所示, 由於共性特征並沒有受到較大影響, 因此可被正確評估為輕微故障. 因此, 可以看出, 若不考慮各模態間的共性特征和個性特征, 很容易導致錯誤的評估結果.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
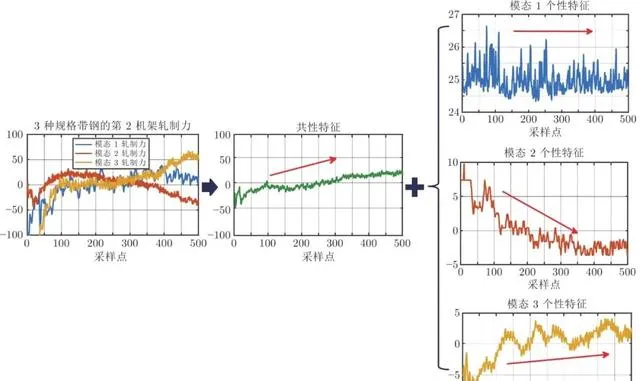
圖 2 熱連軋過程單變量共性−個性特征分解示意圖
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
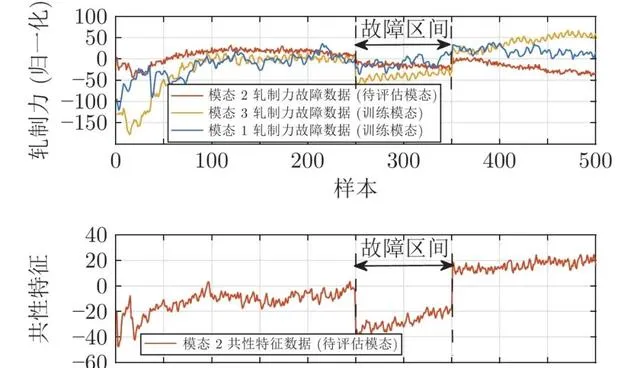
圖 3 軋制力故障共性特征等級評估示意圖
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
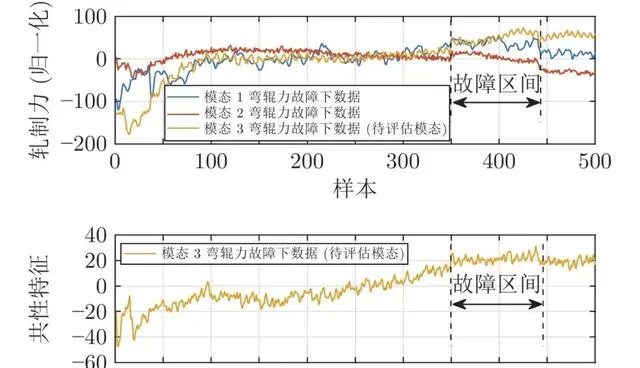
圖 4 彎輥力故障共性特征等級評估示意圖
實際熱連軋生產過程中變量眾多且相互耦合關聯, 多模態特性也使得過程固有的非線性更加明顯. 假設帶鋼熱連軋過程在M 種模態下執行, 每種模態下的過程數據可表示為

其表示由n 個過程變量Nm 個樣本組成的數據矩陣. 如何基於Xm 構建提取各模態的共性特征和個性特征的模型, 對多模態過程故障等級的評估起著關鍵作用. 為實作這一目的, 較為直接的方法是在傳統特征提取的基礎上, 深度挖掘各模態特征間的共性和個性部份. DBN作為特征提取方法可實作高維非線性數據的處理. 按照以上思路, DBN可從Xm 中提取到各模態基本特征
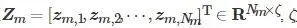
為深層特征的維度. 在此基礎上, 如何構建從
到共性特征
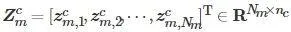
和個性特

間的對映關系亟待解決, 其中, nc 和ns 分別代表共性特征和個性特征的維度. 不失一般性, 這種對映關系可以定義如下
(1)

(2)
式中,
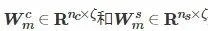
分別表示共性特征和個性特征的對映權重,

分別表示兩種特征的偏置,

分別表示兩種特征對映的非線性函式.
基於以上思路, 剩余部份的具體工作包括: 第一, 構建共性–個性深度置信網路模型, 實作式 (1) 和式 (2) 所描述的對映關系; 第二, 提出融合共性–個性特征進行故障等級評估的方法.
2. 共性–個性深度置信網路
本節提出了CS-DBN模型來提取各模態數據中隱含的共性特征和個性特征, 同時結合已有方法總結了CS-DBN的特點.
2.1 特征提取網路結構
多模態共性–個性特征提取框架如圖5所示. 網路由三部份組成, 分別是預訓練網路、特征變換網路和重構網路. 預訓練網路建立並列DBN, 以標準化後的模態數據Xm 作為各子網路輸入, 提取各模態數據的深層特征Zm . 特征變換網路將每種模態的特征分別分解為共性特征和個性特征, 以預訓練網路的輸出Zm 作為輸入, 結合MK-MMD (Multi-kernel maximum mean discrepancy)[27], 將每個模態特征數據對映為具有最小分布距離的共性特征和具有最大分布距離的個性特征. 同時, 為了增強模型的魯棒性, 首先, 將獲得的各模態共性特征和個性特征透過多層感知機 (Multilayer, perceptron, MLP)[25]層對映至共同的ζ維度; 然後, 將第m個模態學習得到的共性–個性特征與其他模態的共性特征進行加性融合, 以從其他模態學習到的共性特征來增強該模態共性資訊的表示, 進而作為重構網路的輸入. 重構網路利用權重矩陣的轉置重構輸入數據得到
, 通常采用反向傳播 (Back propagation, BP) 演算法, 使用重構數據與原始數據的誤差平方和進行反向調參, 以無監督的方式對整個網路進行參數的全域最佳化.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※

圖 5 DBN與CS-DBN網路結構示意圖
2.2 DBN預訓練
圖5 展示了透過DBN逐層預訓練提取每個模態執行數據特征的過程. DBN由多個受限波茲曼機 (Restricted Boltzman machine, RBM) 堆疊而成, RBM由可見層和隱藏層組成, 將前一個RBM的隱藏層輸出作為下一個RBM可見層的輸入, 自下而上初始化DBN的參數. 在訓練過程中, 單個RBM采用對比散度 (Contrastive divergence, CD)[28]演算法進行一步吉布士采樣, 參數更新公式為
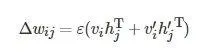
(3)
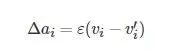
(4)
(5)
式中, vi 和ai 分別表示第i 個可見單元的狀態和偏置, hj 和bj 分別表示第j 個隱藏單元的狀態和偏置,
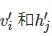
為顯層和隱層透過條件機率采樣生成的重構數據;
為第i 個可見單元及第j 個隱藏單元間的連線權重; ε 為學習率. 此外, 為了提高訓練的速度, 避免過擬合, 本文將
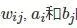
的更新規則分別改進為
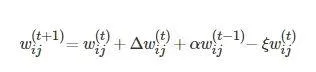
(6)
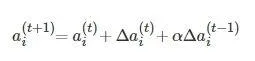
(7)

(8)
式中, α 為加速學習過程的動量, t 表示叠代的次數, ξ 為權重衰減項. 透過這種方式逐個訓練RBM. 在提出的模型中, 第一層的可見單元是實值, 使用高斯受限波茲曼機來訓練網路的第一層[29], 然後使用白努利受限波茲曼機進行深層RBM的訓練.
DBN預訓練可稱為編碼過程, 第m 個模態的數據
經過DBN預訓練後, 最高層RBM的輸出為深度特征Zm . 再將深度特征數據反向逐層解碼, 增加與DBN對應的後向微調步驟, 可以得到微調後的重構數據
. 每個模態無監督的DBN重構訓練損失函式為
(9)
2.3 特征轉換層
在提取的多模態深度特征基礎上, 進一步設計特征轉換層. 預訓練後, 將各模態深層特征
維共性特征空間和ns 維個性特征空間, 並將共性–個性特征視為來自兩個分布的樣本, 采用MK-MMD計算分布距離來分離兩種特征.
MMD透過核對映方法將兩個分布的關鍵統計特征嵌入到高維再生希爾伯特空間 (Reproducing kernel Hilbert space, RKHS) 中, 然後計算核均值嵌入之間的距離, 但MMD在很大程度上依賴於核函式的選擇. 為了解決核函式對最終對映效能的影響, 本文采用MK-MMD演算法, 該演算法在原始MMD特征核的基礎上, 利用多個高斯核的線性組合來增強距離度量效能, 從而能夠更準確地將輸入空間的值對映到RKHS中得到最優值.
設m1 和 m2 分別代表 M 個模態中任意兩個模態, 第m1個模態的共性特征數據
滿足分布 p , 第 m2 個模態的共性特征數據
滿足分布q, m1,m2=1,2,3,⋯,M, 則由MK-MMD定義的p 與q 之間距離的經驗估計為
(10)
式中, Hk [27]是具有特征核k 的RKHS, E(⋅) 表示給定分布的期望, ϕ(⋅) 表示原始特征空間對映到RKHS的對映函式, 與特征對映關聯的特征內核
, MK-MMD使用多個核的凸組合, 表示如下
(11)
其中, 系數βu 被約束以保證匯出的多核k 特性, d 為特征核的個數,
可表示如下
(12)
式中, σu 為核函式的頻寬.
在訓練階段, 為了降低計算復雜度, 本文采用Gretton等[27]提出的MK-MMD的無偏估計. MK-MMD的計算可以轉換為
(13)
其中, 四元組
定義為
為一個批次的樣本數.
可計算為
(14)
同樣, 類似於式 (13), 可以計算兩兩模態個性特征之間的MK-MMD距離
. 在本文框架中, 不同模態共性特征
應有盡可能相似的分布, 同時模態個性特征
的分布盡可能差異較大. 因此, 需要最小化
. 將距離度量加入網路的損失函式中, 模態共性特征和個性特征的梯度從兩個不同的來源計算: 各子網路重構誤差和兩兩模態間不同分布的MK-MMD距離. 並透過BP演算法反向調節各部份參數. 整體損失函式為
(15)
其中,
分別為重構部份以及共性–個性特征部份的參數, 用以平衡各項, 使網路損失函式最小化.
2.4 方法特點及對比分析
在構建的CS-DBN網路中, 共性特征的維度nc 需要在模型訓練的時候確定. 根據式 (14) 可以看出, 當nc 從1開始逐漸增大時, 各模態共性特征間的MK-MMD距離不會有較大增加. 由於整體的重構誤差
逐漸減小, 因此
會呈現下降趨勢. 當nc取值增大時, 共性特征間的距離會逐漸變大, 導致
的下降變得不明顯. 綜上, 在訓練過程中可以將nc從1逐漸增大到
, 並記錄損失函式值
, 當損失函式值不再明顯減小時, 記錄此時的nc.
CS-DBN透過機率生成和非線性對映建立原始數據與特征間的關系, 更適合於復雜非線性工業過程. 與文獻[30] 和文獻[31] 中方法相比, 在特征提取的原理方面, CS-DBN在滿足共性特征距離最小、個性特征距離最大的前提下, 透過最小化重構誤差來獲取特征, 充分地結合了傳統方法的特點. 在訓練過程中, CS-DBN不要求各模態的數據等長, 這也極大地擴充套件了方法的通用性. 從投影空間的角度獲取的共性特征和個性特征相互正交, 這有利於構建互補的故障檢測指標, 而CS-DBN和基於張量分解方法不能滿足特征的正交性, 各種方法的特點及比較總結如表1所示. 接下來, 將介紹如何結合CS-DBN的特點構建故障等級評估方法.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 1 各類共性–個性特征提取方法特點總結
3. 融合共性–個性特征的故障等級評估
本節在CS-DBN的基礎上, 提出了融合共性–個性特征進行故障等級評估的方法.
3.1 故障等級劃分
如第1節所描述, 模態間的共性特征關聯了多個操作模態的狀態, 影響共性特征的故障會引起系統結構性故障, 表現為影響多個模態的關鍵品質指標, 屬於嚴重故障. 影響模態個性特征的故障, 可以透過系統的閉環調節及時補償, 不會對關鍵指標產生影響. 並且, 由於特征變量間的耦合作用, 影響各模態個性特征的故障可能會由於未及時檢修或故障較大等原因, 演變為影響多模態共性特征的故障. 因此, 可以根據故障對共性特征和個性特征的影響構建評估方法. 本文結合國家標準GB/T709-2006將故障劃分為3個等級: 「輕微故障」、「一般故障」、「嚴重故障」. 具體來說, 當有故障發生時, 將主要影響個性特征且不影響品質指標的故障劃分為「輕微故障」; 將同時影響共性特征和個性特征且對品質指標的影響較小的故障劃分為「一般故障」; 將對共性特征影響較大且對品質指標影響較大的故障劃分為「嚴重故障」.
3.2 故障等級評估模型
基於CS-DBN模型, 並利用第3.1節已知的各模態故障等級數據, 可獲得多模態共性特征集
, 包含正常數據的共性特征
和故障數據的共性特征
, 同時獲得多模態個性特征集Zsm, 包含正常數據的個性特征
和故障數據的個性特征
. 將每個模態特征數據樣本與故障等級標簽進行模式匹配可得到數據
和
其中
為樣本對應的G 個故障等級標簽. 透過邏輯回歸(Logistic regression, LR)[32]的多分類「一對多」策略, 將多個二分類進行獨立調優並整合. Softmax函式是LR在多分類的推廣, 其輸出為樣本點屬於每一類的機率, 共性特征中第i 個樣本
屬於每個等級的機率可計算為
(16)
式中,
為權重矩陣. 類似地, 個性特征屬於每一類的機率
也可以按照式 (16) 計算得到.
共性特征和個性特征共同決定了故障等級且對每個等級的故障貢獻值不同, 因此不能僅將兩種特征透過拼接或加和來進行等級評估訓練. 為了獲得更好的效能, 在訓練階段根據兩種特征的重要性進行加權, 得到屬於每個等級的機率
, 最終
屬於每個等級的機率
計算為
(17)
最終的評估結果Grade(xm,i) 確定為
中機率最大值對應的等級. 式(17)中, λ(0≤λ≤1) 為特征的加權系數, λ 越大表示共性特征分量在等級評估過程中所占比重越大. 當λ=0 時, 表示只有個性特征分量, 個性特征反映了各個模態內的資訊, 因此, 當用於訓練模型的各模態故障資訊不足時, 可能會影響評估精度. 當λ 逐漸增大至1時, 表示在確定故障等級時只有共性特征分量起作用.
3.3 基於CS-DBN的故障等級評估方法總結
以熱連軋過程為例, 本文所提出的方法可總結如圖6所示. 選取該過程幾個典型規格的帶鋼軋制過程作為M 個工作模態, 並將這些模態的執行數據匯出作為CS-DBN的網路訓練數據. 同時, 可以利用各模態已知的故障等級數據生成共性–個性特征正常/故障特征集, 用來訓練評估模型. 當線上得到待評估模態數據後, 可利用訓練的模型參數進行線上故障等級評估. 詳細的方法總結可描述如下:
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
圖 6 基於CS-DBN的故障等級評估流程圖
1) 離線建模:
a) CS-DBN模型的構建:
b) 等級評估模型的構建:
2) 線上套用:
a) 獲取待評估模態數據
並進行標準化處理;
b) 透過CS-DBN模型得到線上數據共性–個性特征
;
c) 基於
, 透過式 (17) 確定故障等級.
4. 帶鋼熱連軋過程套用驗證
本節將所提方法用到熱連軋精軋過程中, 透過實際精軋過程數據驗證本文方法的評估效果.
4.1 過程描述及數據描述
4.1.1 過程描述
帶鋼熱連軋主要由加熱爐、粗軋機、飛剪、精軋機組、層流冷卻和卷取機等相互耦合的工序構成, 熱連軋過程布局如圖7所示. 其中, 精軋機組是控制成品品質和保障系統安全的關鍵環節, 精軋機組由F1 至F7 共7台機架串聯組成, 每個機架由一對工作輥、一對支撐輥以及相應的液壓壓下裝置等部份構成. 四輥軋機的下支撐輥的下部設有軋制力檢測傳感器. 工作輥之間的輥縫控制由高精度的液壓伺服控制系統完成, 透過設定輥縫值來保證帶鋼的出口厚度. 出口厚度是關鍵效能指標之一, 厚度精度取決於精軋機壓下系統和厚度控制系統 (Automatic gauge control, AGC) 的裝置形式, 現代化AGC能綜合采用多種形式的厚度自動控制系統, 以適應不同鋼種、規格和工藝參數變化的要求.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
圖 7 熱連軋機組及精軋機組布局圖
4.1.2 數據描述
本文采用某鋼鐵廠帶鋼熱連軋現場采集的過程數據來驗證所提方法的有效性. 數據描述如表2所示. 選擇Q235B碳素結構鋼4種規格帶鋼的生產過程作為4種模態, 4種規格帶鋼的出口厚度分別為2.30 mm、2.70 mm、3.00 mm和3.95 mm. 評估數據為該過程的關鍵過程變量, 包括7個機架的輥縫、軋制力和彎輥力 (第1機架無彎輥力控制) 共20個過程變量.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 2 熱連軋過程多模態數據描述
不同模態的故障等級數據可透過如圖8所示的熱連軋過程故障註入系統獲得. 該系統整合了熱連軋過程壓下、溫降、彎輥、活套等各類機理模型, 透過讀取實際的多規格生產過程、工藝設定及軋機的狀態數據, 並利用增量疊加形式將各類故障註入到正常的過程數據, 從而獲得各種等級的故障數據. 實驗表明, 該系統可較好地模擬實際生產過程的故障產生、傳播及對產品品質的影響. 在該系統中可讀取表2所描述的4種規格的正常過程數據, 並透過選擇故障型別、故障大小及故障發生位置等資訊實作故障註入.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
圖 8 熱連軋故障註入系統
本文選取了熱連軋過程常見的3類典型故障進行方法驗證. 3類故障按照第3.1節的劃分標準可分別歸類為「輕微故障」、「一般故障」和「嚴重故障」. 故障型別1為F5彎輥力傳感器故障, 由於系統的閉環控制, 該故障可以透過增大F6和F7的彎輥力來補償, 因此只影響各模態的個性特征, 不會對出口厚度造成影響. 故障型別2為F4輥縫故障, 該故障將影響F4和F5的軋制力和輥縫, 但由於AGC系統的補償控制, 可以透過壓下裝置做相應調節來消除厚度偏差. 故障型別3為F2與F3間冷卻水閥執行器故障, 該故障會導致F3軋鋼入口溫度升高, 由於前饋控制器的影響, F3及之後機架的軋制力和輥縫都會受到影響, 最終影響鋼品出口厚度, 在這種情況下, 任何帶鋼型別的生產過程都將受到影響, 因此系統的共性特征和個性特征都將受到影響. 綜合考慮故障影響的變量以及鋼品出口厚度差, 本文將每個模態的數據劃分4個等級, 故障劃分結果如表3所示.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 3 熱連軋過程故障等級劃分及標簽添加
4.2 故障資訊已知下的等級評估
4.2.1 模型訓練
如第3.3節所描述, 整個模型訓練分為兩步: 1) CS-DBN特征提取模型; 2) 故障等級評估模型. 選擇第4.1.2節中描述的4個模態的正常工況數據訓練CS-DBN模型, 每個模態封包含20個變量3000個樣本, 組成訓練集
.
CS-DBN的訓練過程首先對每個模態建立DBN子模型. 采用試錯法進行超參數選擇, 逐層設定隱含層節點數並依次疊加RBM層數, 根據損失曲線收斂的速度和大小初步確定DBN的結構參數、損失函式L的各約束項以及叠代步數 (epoch). 中間特征轉換層共性–個性特征維度nc和ns是影響評估結果的關鍵參數, 維度較低可能不能充分提取資訊, 維度較高則會產生冗余資訊. 在確定維度值時, 首先固定nc為1, ns由1逐漸增大, 觀察收斂曲線, 可確定獲得最小收斂值時ns維度為7; 再固定ns值, 逐漸增加共性特征維度, 不同nc值的重構誤差收斂值如圖9所示. 為了簡化模型結構, 最終選擇最佳共性特征維度為5. 綜合以上偵錯結果, DBN結構最終包含2個隱含層, 預訓練部份最佳DBN網路結構為20-35-14, 中間特征轉換層權重設定為
. 批次數Nb 設定為80, 學習率ε 為0.0001, 叠代步數設定為600次, 隨機失活率dr設定為0.5, 具體模型參數設定如表4所示.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
圖 9 共性特征維度nc與重構誤差
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 4 CS-DBN模型參數
為驗證本文所提方法的收斂效果, 圖10給出了CS-DBN訓練過程中的叠代曲線. 其中, 圖10(a)為CS-DBN損失函式L 在訓練過程中的叠代曲線. 可以看到, 在叠代次數達到400步時, 訓練過程叠代曲線已經明顯收斂. 圖10(b)、圖10(c)為不同模態的共性特征間和個性特征間MK-MMD值的叠代曲線. 可以看出, 隨著訓練次數的增加, 不同模態的共性特征間MK-MMD值呈現出不斷減小的趨勢至收斂, 反之個性特征間MK-MMD值隨叠代次數逐漸增大. 這反映出MK-MMD方法可以區分不同模態數據分布間的相似性和差異性.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
圖 10 CS-DBN訓練過程叠代曲線
基於CS-DBN模型, 可獲得各模態正常工況數據和不同等級故障數據的共性特征
,
以及個性特征
,
. 共性–個性特征與等級標簽匹配後用於訓練等級評估模型部份. 等級評估模型訓練集由每種模態正常數據以及不同等級故障數據各2000組組成. 測試集為第4個模態的數據, 包括1000組正常數據和3000組各等級故障數據.
4.2.2 等級評估結果
為了驗證所提方法的套用效果, 本文將基於CS-DBN的等級評估結果與SVM、FDA兩類典型機器學習方法以及DBN、SAE結合Softmax深度學習方法的等級評估結果對比, 以說明本文所提方法的優越性. 4種對比方法對模態數據進行整體建模, 利用4個模態的正常數據和已有的各模態等級故障數據訓練評估模型. 其中, SAE的隱層神經元數設定為40-25-4, DBN結合Softmax的網路結構設定為35-14-4, SVM的核函式設定為徑向基核函式. 為了清晰地展示評估精度, 本文引入準確率(Accuracy)、精確率(Precision)、MacroF1作為評估指標[15, 25].
當訓練過程4個模態全部故障資訊已知時, 等級評估結果如表5所示. 對比可知, 在4個模態各等級故障資訊已知的情況下, 5種方法評估結果都有較高的準確率、精確率和MacroF1. 其中, 融合共性–個性的故障等級評估方法的各項指標均達到98% 以上, 高於其他4種方法. 因此, 融合多模態共性–個性特征的評估方法可以更加有效準確地判斷故障等級.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 5 各模態全部故障資訊已知下的評估結果 (%)
4.3 故障資訊部份已知的等級評估
為了進一步驗證本文方法在多模態故障數據不充分下的套用效果, 本節考慮訓練過程中多模態部份故障資訊不全的情況, 設計包含不同故障資訊的案例, 並透過新模態數據進行評估結果驗證.
4.3.1 故障資訊不完全情況下的評估結果
在CS-DBN模型訓練完成後, 選擇4個模態的正常數據以及前3個模態的部份故障數據作為評估模型的訓練集. 同時將第4個模態的各等級數據共4000組作為測試集, 即在訓練過程中測試集的各等級故障數據均未參與故障等級評估模型的訓練.
表6以準確率指標為例展示了各模態不同故障組合案例下的評估結果. 案例A考慮了每個訓練模態中包含最多兩種等級故障數據下的評估準確率, 其中A-1到A-8是各模態間不同的組合情況. 可以看出, 當故障資訊較少時, CS-DBN方法整體故障等級評估準確率在60.00% 以上, 均高於其他4種方法, 同時, 在多數情況下, SVM和FDA方法評估失敗(Accuracy ≤≤ 50.00%). 案例B設定為每個模態均有兩種等級的故障數據, 故障資訊較案例A增多. 從評估結果可以看出, 與案例A相比, 在B-1至B-8不同故障數據組合情況下所有方法的評估準確率均有所提升, CS-DBN在某些故障組合下準確率可達到85.50%, 平均準確率為71.92%, 遠高於DBN的61.47% 和SAE的58.25%. 在案例C中, 某些模態的故障等級數據從兩種增加至三種, 更多的故障數據參與訓練提升了評估效果. 其中CS-DBN方法在所有故障組合下準確率均高於70.00%, 平均準確率為73.12%, 高於DBN的70.47% 和SAE的64.85%. 同時, FDA和SVM方法也均超過50.00%. 案例D設定為訓練過程中至少有兩個模態有三種等級的故障數據. 評估結果顯示, CS-DBN方法的平均準確率為80.79%, 同時在4個故障組合中, 準確率均高於80.00%, 最高為88.25%. 與之相比, FDA和SVM平均值仍為50.00% 左右, DBN和SAE方法也無較大提升.
※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※ ※
表 6 各模態部份故障資訊已知下的評估準確率結果 (%)
總結表6可知, 隨著更多的故障等級數據參與訓練, 5種方法的評估準確性都有所增加. CS-DBN方法因其可以提取多模態過程的共性資訊, 能夠更好地學習到多模態過程同一等級故障數據間的共性特征, 與傳統方法相比, 評估準確率提升近10%. 本文所提模型可以更準確地評估未知故障資訊下的模態所發生的故障.
4.3.2 待評估模態故障資訊未知下的評估結果
當前3個模態的全部故障資訊已知時, 選擇4個模態的正常數據以及前3個模態的各等級故障數據訓練評估模型, 使用第4個模態的各等級數據(均1000組) 進行測試. 圖11(a) ~ 圖11(e)分別展示所提方法和對比方法的等級評估結果. 如圖11(b)和圖11(c)所示, DBN和SAE在「嚴重故障」和「一般故障」等級中有較多的誤評估樣本. 由圖11(d)和圖11(e)可以看出, 當待評估模態故障資訊未知時, SVM和FDA的評估精度較低, 其中FDA未能區分「嚴重故障」和「一般故障」, 造成了精確率和MacroF1值失效. CS-DBN方法的評估準確率達到了92.40%, 精確率達到了92.64%, MacroF1達到了92.37%, 僅在「正常數據」和「輕微故障」裏有少量評估失誤, 評估準確率較第4.3.1節中案例D的結果提升了11.61%. 可以看出, 當用於訓練的故障資訊增多時, 本文所提方法能夠充分利用不同模態的共性–個性特征, 進一步提高模型的效能.
圖 11 前3個模態全部故障資訊已知時的評估結果
4.3.3 權重因子λ對評估結果的影響分析
圖12 展示了在不同故障資訊的實驗中權重系數取值與評估準確率的關系. 圖12 中, 實驗1至實驗10為評估模型訓練中故障資訊逐漸增多的代表性案例. 例如, 實驗1中故障資訊為模態1至模態3分別含有一種故障等級數據; 實驗5中故障資訊包括模態1的「輕微故障」、模態2的「一般故障」與「嚴重故障」、模態3的「輕微故障」與「一般故障」; 實驗10包含4個模態的全部故障資訊數據. 當λ=0 時, 即只有個性特征部份參與等級評估的情況, 每種實驗的評估準確率都較低. 如圖12所示, 當λ 逐漸增加, 評估準確率開始提高, 其中, 在實驗4、實驗5、實驗6、實驗8中, 隨著λ 超過0.25, 評估準確率逐漸提升. 在實驗2和實驗3中, 當λ 達到0.55時, 評估準確率逐漸提升. λ 增加到一定程度後, 評估準確率會有所下降, 例如, 在實驗6至實驗9中, 當共性權重因子增加至0.9時, 評估準確率出現下降情況. 在實驗10中, 當共性權重因子增加至0.75時, 評估準確率開始下降. 綜上所述, 為了使等級評估結果在不同故障資訊已知的情況下都相對最優, λ 的合理範圍選擇為0.55至0.75, 本文中λ=0.6。
圖 12 共性特征權重因子分析
套用結果驗證可知, CS-DBN方法可以透過深度挖掘熱連軋多規格帶鋼生產過程數據間的共性特征和個性特征, 構建更適合於多模態過程的故障等級評估模型. 該方法在故障等級數據不充分的情況下, 利用不同模態數據的共性故障特征同樣能取得較好的等級評估結果.
4.3.4 模型魯棒性分析
本文的魯棒性可從兩個方面進行分析. 首先, 與線性共性–個性特征提取方法相比, 當數據出現缺失或離群值時, 傳統方法透過構建投影空間或基向量來提取特征, 容易導致投影空間獲取偏差, 進而無法獲取準確的共性–個性特征, 而CS-DBN采用了神經網路的方法, 透過非線性啟用函式和訓練過程的dropout技術, 可以使訓練數據中離群值的影響較小, 提高了方法在低品質工業數據建模中的魯棒性. 其次, CS-DBN可以透過增加訓練過程的模態數量來更新所提取的共性特征和個性特征, 因此當測試數據為未參與訓練的數據時, 模型也能有良好的共性–個性特征提取結果. 以本文驗證過程為例, 一個時間段內采集的10個批次的熱連軋過程數據為數據集, 其中每個批次有各自的軋制過程設定. 實驗過程選擇其中的部份模態為訓練集, 另一部份作為測試集, 透過增加或減少參與訓練的模態數據提取模態的共性特征和個性特征. 驗證結果表明, 當參與訓練模態的數為4時, 提取的共性–個性特征已經能較好地覆蓋這10個模態的資訊, 有較好的故障等級評估結果. 但是由於本文所提模型仍具有一定局限性, 當過多模態數據參與模型訓練時, 網路復雜度會提高, 特征提取的結果也會有所影響, 因此, 本文的實驗驗證選擇4個模態進行訓練.
5. 結論
本文針對多模態過程的故障等級評估問題, 提出一種基於CS-DBN的故障等級評估方法. 首先, 在傳統DBN基礎上, 結合MK-MMD分布度量構建了CS-DBN模型, 以解決多模態過程中共性–個性特征提取問題. 同時, 融合多模態共性特征和個性特征構建了基於加權邏輯回歸的故障等級評估模型. 本文將所提出的方法套用到熱連軋多規格帶鋼的生產過程中, 並利用熱連軋過程故障註入系統生成多規格帶鋼多種故障等級數據進行方法驗證. 驗證結果表明, 與傳統評估方法相比, 所提方法在故障等級資訊缺失下能夠提高評估準確性; 當多模態故障等級資訊充足時, 評估準確率可達98.75%.
未來將針對其他深度學習演算法進行改進和最佳化, 提升多模態過程故障等級評估的精度, 並對復合故障下的多標簽評估與分類方法開展研究.
聲明: 公眾號轉載的文章及圖片出於非商業性的教育和科研目的供大家參考和探討,並不意味著支持其觀點或證實其內容的真實性。版權歸原作者所有,如轉載稿涉及版權等問題,請立即聯系我們刪除。
「人工智慧技術與咨詢」 釋出











