白交 西風 發自 凹非寺
量子位 | 公眾號 QbitAI
剛剛,大模型再次攻下一城!
谷歌DeepMind宣布,他們數學AI「摘得」IMO(國際數學奧林匹克競賽)銀牌,並且距離金牌僅一分之差!
是的,沒有聽錯!就是難到絕大多數人類的奧數題。要知道今年IMO全部609名參賽者,也僅有58位元達到了金牌水平。

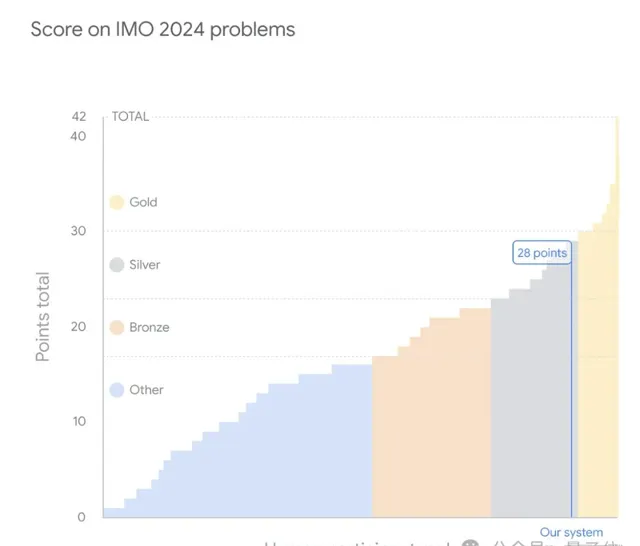
此次,谷歌AI解決了2024 IMO競賽6道題目中的4道,而且一做一個滿分,總共獲得28分
。(滿分42分,金牌分數線29分)
其中第四題幾何題,AI僅僅用時19秒?!
而號稱本屆最難的第六題,今年僅有五名參賽者拿下,它也完全答對。
此次的成績還得到了IMO組委的專業認證——由IMO金牌得主、費爾茲獎獲得者Timothy Gowers教授和兩屆IMO金牌得主、2024 IMO問題選擇委員會主席Joseph Myers博士進行評分。
Timothy Gowers教授直接驚嘆:遠遠超過我認知的最先進水平
。
來康康是如何做到的?
谷歌拿下IMO銀牌,Alpha家族新成員問世
此次拿下IMO銀牌的是谷歌兩位Alpha家族成員,他們各自數業有專攻。
AlphaProof
,Alpha家族新成員,基於強化學習的
形式數學推理系統。
AlphaGeometry 2
,此前AlphaGeometry改進版,專門用於解決幾何問題。
先來認識一下新成員——AlphaProof。
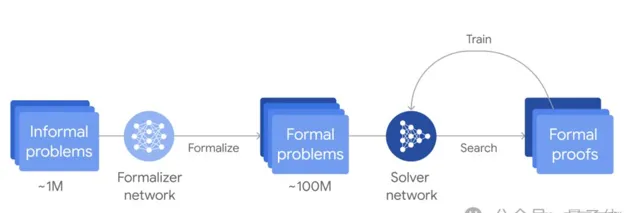
它是一個自訓練系統,能用形式語言Lean來證明數學陳述。它能將預先訓練好的語言模型與AlphaZero強化學習演算法結合在一起。
團隊透過微調Gemini,能自動將自然語言陳述轉換為形式語言Lean陳述,由此建立了一個大型數學題庫。
當遇到問題時,AlphaProof會生成解決方案候選,然後透過搜尋Lean中可能的證明步驟來證明或反駁這些候選。
每個找到並驗證的證明都會用於強化AlphaProof的語言模型,從而提高其解決後續更具挑戰性的問題的能力。
在比賽的前幾周內,它就這麽迴圈往復地用數百萬個IMO級別題目進行了訓練。
比賽期間也套用了訓練迴圈,不斷強化自身證明,直到找到完整的解決方案。
再來了解一下前進演化之後的AlphaGeometry 2
。它是一個神經-符號混合系統,其中語言模型基於Gemini。
它的前身1.0今年還登上了Nature:無需人類演示達到IMO金牌選手的幾何水平
。

跟上一個版本比,它使用了更大一數量級的合成數據進行從頭訓練。而它采用的符號引擎比其前代快兩個數量級。當遇到新問題時,會使用一種新的創用CC機制來實作不同搜尋樹的高級組合,以解決更復雜的問題。
在正式比賽之前,它就已經可以解決過去25年所有IMO幾何問題中的83%,而其前身的解決率僅為53%。
今年IMO賽事中,它僅用了19秒就完成了第四個問題。

接著就來看看,此次IMO這兩位是如何配合發揮的。
首先,問題被手動轉譯成正式的數學語言,以便系統理解。
我們知道人類比賽時,分兩次送出答案,每次有4.5個小時。
而谷歌這兩個系統先是在幾分鐘內解決了一個問題,其他問題則是花了三天時間。
最終,AlphaProof透過確定答案並證明其正確性,解決了兩道代數題和一道數論題。
其中包括比賽中最難的一道題,也就是,今年的IMO比賽中僅有五名選手解出的第六題。

AlphaGeometry 2解決了幾何問題,而兩道組合問題仍未解決。
除此之外,谷歌團隊還試驗了一種基於Gemini的自然語言推理系統。換言之,無需將問題轉譯成形式語言,並且可以跟其他AI系統結合使用。
團隊表示,他們接下來還會探索更多用於推進數學推理的AI方法。
而關於AlphaProof的更多技術細節,也計劃很快釋出。
網友:不懂數學但大受震撼
看到這兩個系統的表現,網友們紛紛表示「不懂數學但大受震撼」。
AI程式設計師Devin團隊Cognition AI聯合創始人Scott Wu表示:
這樣的結果真是令人驚嘆。小時候,奧林匹克競賽就是我的全部。從未想過它們會在10年後被人工智慧解決。

OpenAI科學家Noam Brown也開麥祝賀:

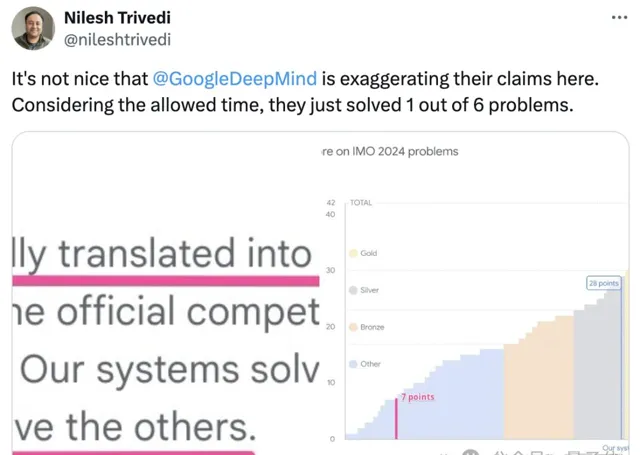
不過,也有網友表示,如果按照標準比賽時間(競賽分兩天進行,每天四個半小時,每天解決三個題),這兩個AI系統實際上只能解決6個問題中的一個。
這一說法立刻得到了部份網友反駁:
在此情境中,速度不是主要關註點。如果浮點操作次數(flops)保持不變,增加計算資源會縮短解決問題所需的時間。
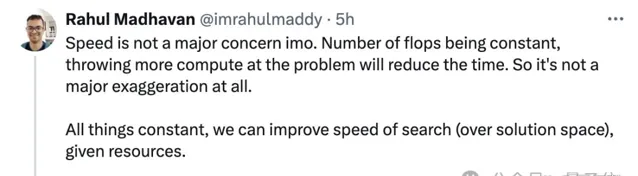
針對這一點,也有網友疑問道:
兩個AI系統沒能解答出組合題,是訓練的問題還是計算資源不夠,時間上不行?或者還存在其他限制嗎?

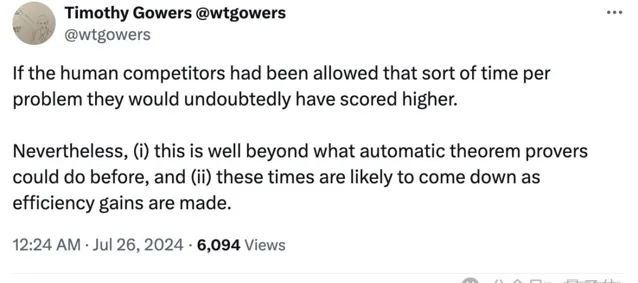
Timothy Gowers教授發推文給出了他的看法:
如果允許人類參賽者在每個問題上花費更多時間,他們的得分無疑會更高。然而,對於AI系統來說,這已經遠超以往自動定理證明器的能力;其次,隨著效率的提高,所需時間有望進一步縮短。
不過前兩天大模型還困於「9.11和9.9哪個數位更大?」這麽一個小學題,怎麽這一邊大模型又能解決奧數級別的難題了?!
失了智,然後現在怎麽又靈光乍現,恢復了智?

輝達科學家Jim Fan給出解釋:是訓練數據分布
的問題。
谷歌的這個系統是在形式證明和領域特定符號引擎上進行訓練的。某種程度上說,它們在解決奧林匹克競賽方面高度專業化,即使它們建立在通用大模型基礎上。
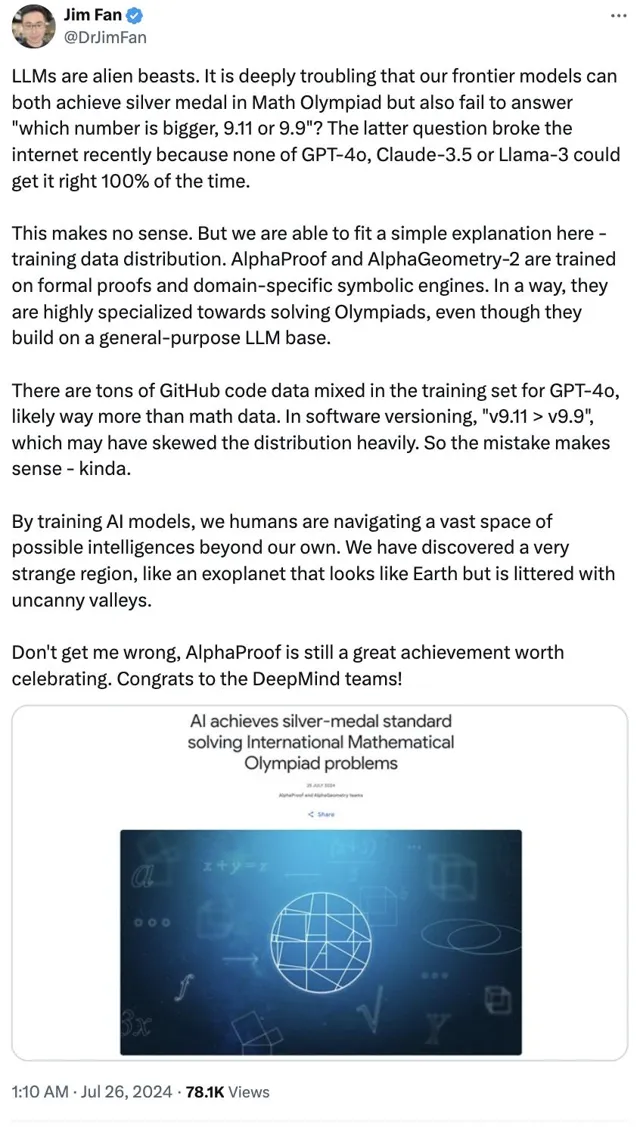
而像GPT-4o的訓練集中混有大量GitHub程式碼數據,可能遠遠超過數學數據。在軟體版本中,「v9.11>v9.9」,這可能會嚴重扭曲分布。所以說,這個錯誤還算說得過去。
對於這一奇怪現象,他將其形容為
我們發現了一個非常奇特的區域,就像一顆看起來像地球卻遍布奇異山谷的系外行星。
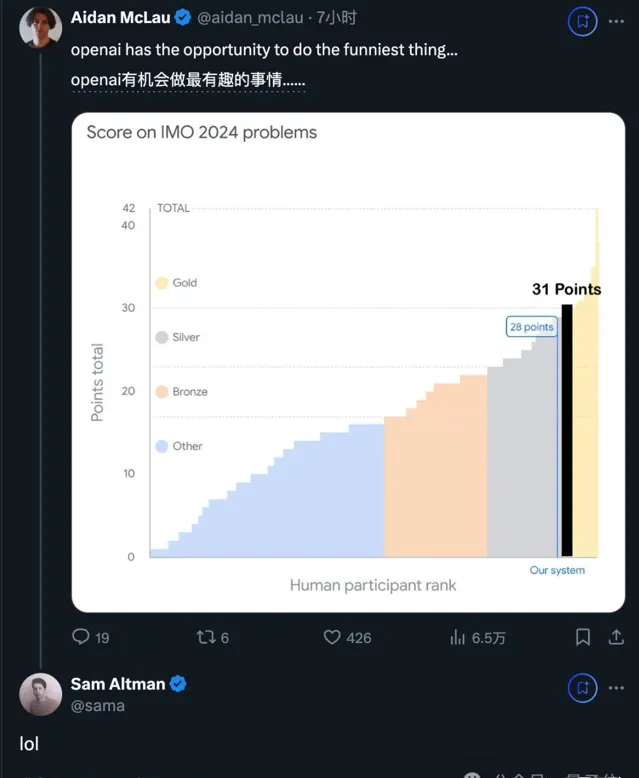
還有熱心的網友cue了下OpenAI,也許你們也可以嘗試……
對此,阿特曼的回復是:
參考連結:
[1]https://x.com/googledeepmind/status/1816498082860667086?s=46
[2]https://x.com/jeffdean/status/1816498336171753948?s=46
[3]https://x.com/quocleix/status/1816501362328494500?s=46
[4]https://x.com/drjimfan/status/1816521330298356181?s=46
[5]https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level











