
大模型:泛化即智慧,壓縮即一切
深度學習入門:理解泛化
泛化是指模型在未見數據上的表現。作為入門者,我們專註於觀察和理解現象,而不是深入探究。這篇總結旨在激發您對泛化的興趣,為進一步探索奠定基礎。
遵循 Scaling Law 定律,專註於為長期模型泛化能力獲取大量多樣化數據,勝過透過巧妙調整模型獲得短期效果。正如機器學習專家 Rich Sutton 在【苦澀的教訓】中強調的那樣,這種方法至關重要。
泛化能力,即從特定問題中提取一般性原理,並將其套用於其他領域的能力。孔子稱贊顏回具有舉一反十的泛化能力,凸顯了其重要性,因為它決定了一個人的上限。
人工智慧模型的泛化能力至關重要,因為它決定了模型在面對新數據時的預測準確性。泛化指模型從訓練數據中提取共性,使其能夠對未見過的數據做出可靠預測。
定義1: 模型的泛化程度與你將不同數據推入足夠高容量模型的速度成正比。
培養孩子泛化能力的關鍵在於構建穩固的基礎認知,猶如教育中的奠基工程,為後續的知識拓展和套用提供堅實支撐。
早期經驗會塑造兒童對世界的認知。就像蘋果一樣,如果只接觸單一顏色,兒童可能將其視為唯一顏色。透過暴露於各種顏色,他們擴大對現實的理解,意識到世界的多樣性。
透過訓練模型處理大量且多元的數據,模型能夠適應它從未接觸過的全新數據。然而,成功實作這一點的關鍵在於確保模型能夠有效地利用這些數據。
所以說,記憶是通向泛化的第一步。
1. 監督學習是優秀的數據海綿
深度神經網路擁有強大的數據吸收能力,得益於監督學習訓練。它們可以迅速記住大量數據,即使訓練批次大小達到數萬。
監督學習的優勢在於其數學保證:只要訓練數據充足且誤差低,模型對新數據的預測也會精準。這意味著,當訓練過程將誤差降至最低時,模型已有效「記住」訓練集。
有人可能會說,我們只是在擬合訓練集麽,為什麽能推匯出測試集泛化呢?
數據集中每個標記經過評估後,訓練損失實際上是下一個標記驗證損失。這表明模型正在學習預測下一個標記的機率分布,從而最大化標記序列中標記預測的準確性。
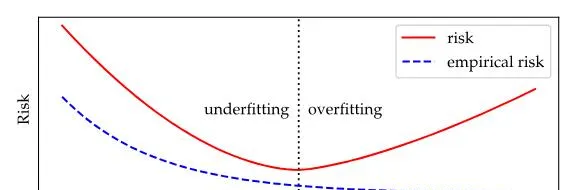
隨著模型復雜度的提升,經驗風險和泛化風險先減後增,在某一臨界點處達到平衡。此後,經驗風險繼續下降,而泛化風險卻持續上升。
教科書中的 U 形風險曲線表示復雜度與模型預測準確性之間的關系。欠擬合(復雜度過低)和過擬合(復雜度過高)均會導致較差的效能。
定義2:狹義上,過度參數化的深度網路可以更好的泛化。
深度神經網路在極低訓練誤差下表現出驚人的泛化能力,挑戰了傳統對於過度擬合的理解。這表明過度參數化的模型即使在訓練損失接近零的情況下,也能有效避免過度擬合。
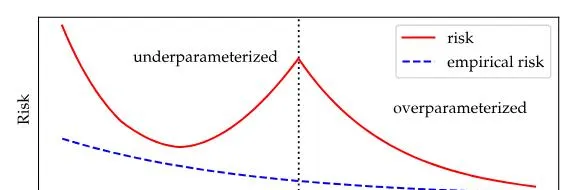
過度參數化的模型具有無限降低風險的能力,即使在訓練損失最小化後。模型復雜性的增加會持續降低風險,盡管收益遞減,但會趨向於一個穩定點。這種過度參數化與風險之間的經驗關系已被證明是可靠的。
復雜性與成本之間存在單一下降曲線,廣泛適用於各種情況。即使在復雜性極低的場景中,成本也隨復雜性的增加而減少,確保極佳的價效比。
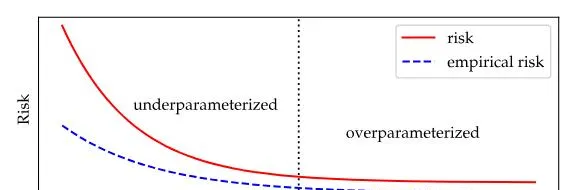
較大型模型不僅泛化性優於較小型模型,還具有樣本外預測能力更強的獨特特性。然而,大型化是否只是將泛化挑戰推遲,仍值得探索。
監督學習的關鍵在於保持測試分布和訓練分布的一致性。只有在這種情況下,監督學習理論才能有效發揮作用,實作準確的預測。
2. 無監督學習是針對不同任務的監督學習
監督學習是一種機器學習技術,它利用已標記的數據訓練模型。模型基於這些標記學習輸入與輸出之間的關系,並最佳化目標函式來提高預測準確性。
無監督學習采用未標記的數據,使模型自主發現潛在模式和規律。其優勢在於:
- 數據探索:幫助理解數據,找出隱藏特征和關聯性。
- 最佳化目標不明:無需預先定義特定目標,模型根據數據自行學習。
最佳化模型有效性的關鍵在於確保目標函式與實際套用場景相關。處理無標簽數據時,驗證目標函式在實踐中的有效性至關重要,以確保模型的輸出符合預期的成果。
透過學習數據的數學結構,即分布匹配,模型可以捕捉數據的本質特征。這意味著模型學習數據的分布特征,而不僅僅是最佳化目標函式。透過這種方法,模型能夠提高泛化能力,更好地適應新數據。
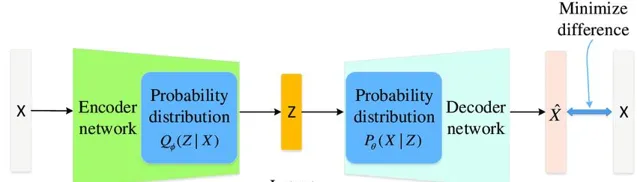
無監督學習利用未標註的數據,建立分布之間的對映。它不學習明確的函式f(x)~y,而是專註於在不同的分布之間建立聯系。透過捕捉數據固有結構,無監督學習可用於數據分組、模式辨識和異常檢測等任務。
分布匹配透過建立函式 f,將輸入資料來源 X 的分布轉換為類似於資料來源 Y 的分布。它在轉譯和文本轉語音中至關重要,利用了不同資料來源分布之間的關系。
該技術透過一個函式 f,將英語句子分布轉換為類似法語句子的分布。函式 f 的約束非常接近真實約束,這表明函式 f 中可能蘊含大量約束。此外,這些約束可用來完整還原函式 f 的資訊。這種類似於監督學習的方法確保了學習的有效性。

真實機器學習場景中,轉譯場景設定可能包含人為因素,與實際情況存在差異。
設想你有數據集 X 和 Y,對應硬碟檔,擁有出色壓縮演算法 C。當將 X 和 Y 連線並輸入 C 時,會產生如下結果:
* 壓縮率提升: X 和 Y 聯合壓縮的壓縮率可能高於單獨壓縮。
* 潛在資訊泄露: X 和 Y 連線後,C 可能會發現兩個數據集之間的隱藏聯系,從而導致潛在的資訊泄露。
* 演算法效率提升: C 在處理連線數據集時,演算法效率可能會得到提升。
利用壓縮模型匹配數據分布,透過辨識共性和模式,將數據集 X 的壓縮模式套用於數據集 Y,建立分布對映。此過程展示了如何透過理解數據結構進行分布匹配和學習,類似於壓縮,以共性匹配和轉換分布。
精簡
壓縮,又稱泛化,是一種辨識數據共性並以簡潔方式表示數據的過程。壓縮成功表示捕捉到了數據的核心規則和特征,減少了冗余資訊。
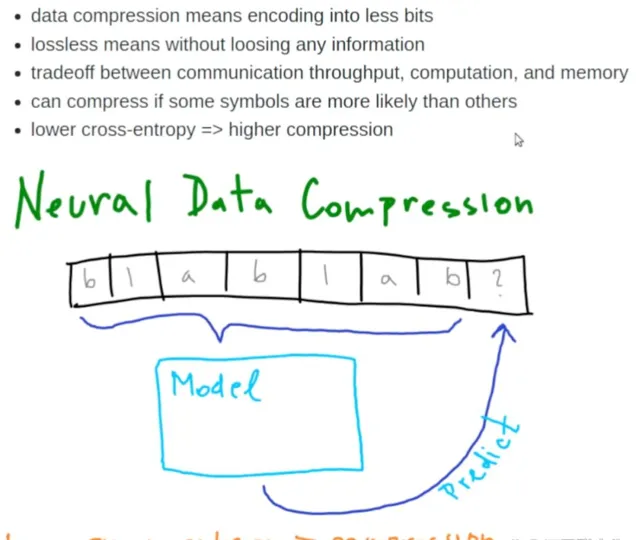
無失真壓縮揭示數據關鍵特征,強化泛化能力。實作最佳無失真壓縮的模型,能最大限度提取數據特征,在不同數據集上展現卓越的泛化效果。
2006 年,電腦教授 Marcus Hutter 發起 Hutter Prize 競賽,旨在獎勵設計出高效通用壓縮演算法的團隊。該演算法結合了人工智慧和資料壓縮技術,使其能夠針對不同數據集最佳化壓縮率,最大限度地減少檔大小。
困難在於壓縮數據的規律本身,然而,高壓縮比與智慧密切相關。
如果Hutter是對的,那我們就可以透過壓縮效率來近似量化模型的智慧。
定義5:壓縮和預測下一個單詞本質上是等價的。

泛化能力是模型對未知數據進行準確預測的能力,而泛化的關鍵在於深刻理解數據的數學規律。透過實作數據的「無失真壓縮」,模型能夠掌握數據的內在規律,從而在未知情況下進行準確預測。
大模型透過預測下一個符號,學習對世界的壓縮表示。這使得它們能夠高效地處理龐大復雜的數據集,獲得對現實的深刻理解。
GPT 升級可透過泛化模型壓縮來完成,無需原始數據訓練。分布之間的泛化使模型能夠將知識從大型模型壓縮器轉移到新任務中。
3. 湧現是模型對數據的數學結構深層理解和壓縮
湧現能力指的是從簡單規則中產生復雜行為或高級功能的能力,也稱為頓悟。
基於 ICLR 研討會論文 "Grokking" 的研究,如果持續訓練模型至訓練損失歸零狀態,它可能在較長一段時間後突然頓悟,實作泛化能力,即論文中提到的 "湧現" 現象。
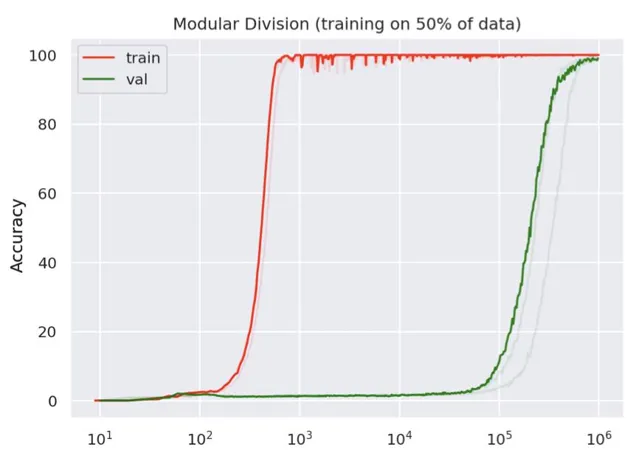
令人驚嘆的是,模型在訓練集上迅速達到 100% 準確率,卻在驗證集上出現過擬合現象。當訓練步數增加 3 個數量級後,驗證集的準確率才逐漸上升,最終接近訓練集。這表明,模型在早期過度關註訓練集的細節,導致在驗證集上的泛化能力較弱。隨著訓練的進行,模型逐漸學會了從訓練集中提取更通用的特征,從而提高了驗證集上的準確率。
在 a + b mod 67 模型驗證實驗中,透過劃分 a、b 配對為訓練和測試數據集,對模型進行訓練和評估。訓練數據用於調整模型,使之能夠輸出正確答案,而測試數據則用於驗證模型是否已獲得解決問題的通用能力。
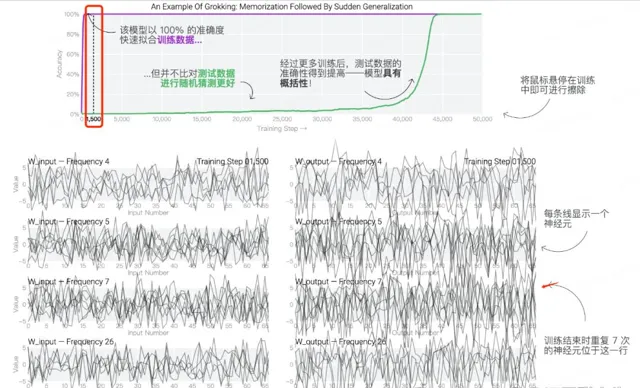
初始訓練階段,模型權重分布嘈雜,即使測試準確率已達100%。
透過分析神經元迴圈頻率,研究人員發現權重波動依然混亂,表明模型仍在學習和調整。
神經元活動展示出周期性模式,預示著測試準確性提升和模型泛化的出現。此發現為改善人工智慧模型的效能提供了重要見解。
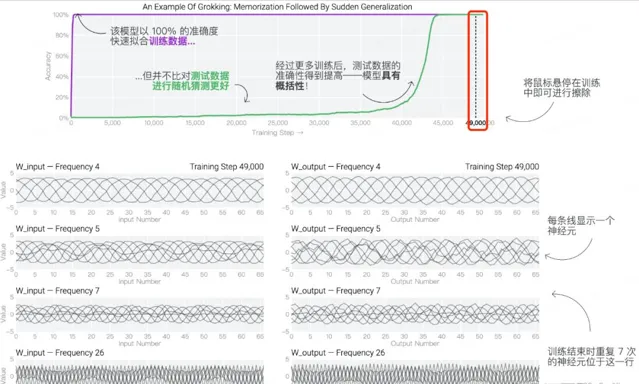
透過將數據推入模型,著重於長期泛化效能,而不是短期模型微調,可以應對具有挑戰性的問題,該方法超越了分析演算法改進的局限。
總結
訓練集上的經驗風險最小化模型是否能有效泛化至測試集中的新數據至關重要。VC維度和Rademacher復雜度等度量標準有助於評估模型的泛化能力,即使訓練集和測試集存在差異。
聯合壓縮是最大似然估計的無過擬合適用。對於一個數據集,似然之和代表壓縮成本,加上參數壓縮成本。合並多個數據集時,似然之和會累加,無需考慮額外參數成本。
泛化理解的局限性不僅體現在定量模糊上,也無法解釋關鍵的經驗觀察。Ilya的觀點提供新的啟發,值得進一步探討。
如果覺得這篇文章對你有所幫助,請點一下贊或者在看,是對我的肯定和支持~
-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-











