存算一體芯片帶來了哪些驚喜?詳解其獨特優勢
全面的數據儲存和管理解決方案會帶來哪些驚喜?
近年來,隨著人工智慧套用場景的快速發展,人工智慧演算法對計算能力的要求急劇提高,其增長速度遠遠超過了莫耳定律所預測的硬體效能的提升。傳統計算芯片在計算能力、處理延遲和電源管理等方面逐漸表現出局限性,難以滿足高度並列的人工智慧計算要求。
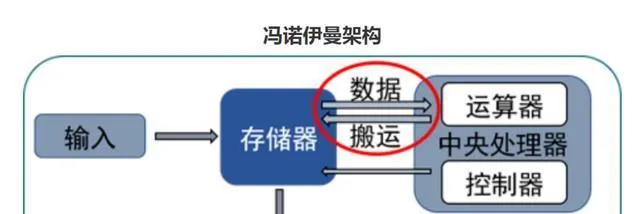
在智慧芯片中,傳統的馮-諾依曼架構以計算為主,處理器與記憶體的物理分離導致頻繁的大規模數據遷移,進一步限制了人工智慧芯片的整體效能。因此,傳統芯片架構面臨著 "記憶體墻"、"功耗墻 "和 "計算墻 "等重大挑戰,難以滿足人工智慧套用對低延遲、高能效和高擴充套件性的迫切需求。這就難以滿足人工智慧套用對低延遲、高能效和高可延伸性的迫切需求。

針對上述問題,業界提出了一種名為 "儲存和核算 "的解決方案。
什麽是 "記憶體墻"、"效能墻 "和 "編譯墻"?什麽是一體化系統?它如何解決這些問題?一體化記憶體技術的出現帶來了哪些驚喜?
芯片制造大樓前的三面墻
首先,我們要弄清楚什麽是 "儲物墻"。
記憶體墻指的是記憶體效能嚴重限制處理器效能的現象。在過去 20 年中,CPU 效能以每年約 55% 的速度快速增長,而記憶體效能的年增長率僅為 10%。長期累積的不均衡增長速度意味著當前記憶體的存取速度嚴重落後於處理器的計算速度,記憶體瓶頸導致強大的處理器難以充分發揮其效能,成為高效能計算發展的一大障礙。這種嚴重限制處理器效能的記憶體瓶頸被稱為 "記憶體墻",又稱 "記憶體瓶頸"。
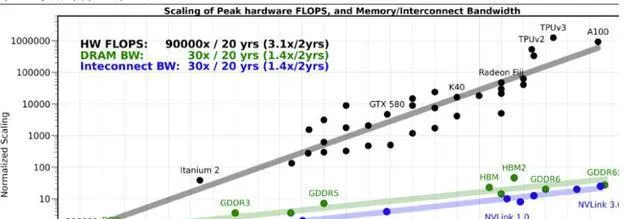
來源:OneFlow,艾訊泰克研究中心
除了記憶體墻問題,數據傳輸過程中還會消耗大量電能,導致芯片能效大幅降低,即所謂的能量墻問題。
造成 "功耗墻 "問題的主要原因是,隨著電腦系統頻寬需求的不斷增加,以及對更大容量和更快存取速度的追求,傳統 DRAM 和其他型別記憶體的功耗正在急劇增加,最終將達到一個臨界點,而這不是簡單地增加功耗預算就能解決的。
這部份是由於數據必須透過包括 L1、L2 和 L3 快取在內的多個儲存層次從 DRAM 轉移到處理器。 研究發現,在某些條件下,將 1 位數據從 DRAM 轉移到處理器所消耗的能量是處理器處理該位所需能量的數倍到十倍。
根據英特爾的研究,當半導體工藝達到 7 奈米時,數據處理功耗高達 35 pJ/bit,占總功耗的 63.7%。數據傳輸的功耗不斷增加,限制了芯片開發的速度和效率。

這兩種情況都隱含著 "編譯墻 "問題,因為在極短的時間內處理大量數據,編譯器無法以靜態可預測的方式最佳化運算子、函式、程式或整個網路,而手動最佳化又非常耗時。
過去,得益於先進的突破性工藝,這三座 "大山 "的缺點也可以透過計算能力的快速提升得到彌補。
然而,殘酷的現實是,近幾十年來,由於工藝技術的改進提高了芯片的計算能力,"老辦法 "正在逐漸失效--莫耳定律正在接近其物理極限,HBM、3D DRAM、更好的互連等傳統解決方案也在逐漸失效。這種 "解決方案 "也是 "治標不治本",晶體管的小型化越來越難以提高計算能力和降低功耗。

隨著大型模型時代的到來和電腦的普及,"三面墻 "的影響無疑越來越大。
綜合倉儲和會計技術的出現是應對這些挑戰的有效措施。
庫存與會計的整合會帶來哪些驚喜?
根據記憶體與計算裝置整合技術的原理,記憶體與計算裝置整合的實質是將記憶體功能與計算功能整合在同一芯片上,直接利用記憶體裝置處理數據--透過修改儲存計算裝置架構中的 "讀 "電路,可以在 "讀 "電路中獲取運算結果,並將結果直接 "寫回 "目標記憶體地址,從而無需在計算裝置與記憶體裝置之間頻繁傳輸數據。透過修改儲存計算裝置架構中的 "讀取 "電路,可以在 "讀取 "電路中獲取運算結果,並將結果直接 "寫回 "目標記憶體地址,而無需在計算裝置和儲存裝置之間進行頻繁的數據傳輸,從而消除了數據傳輸造成的損耗,大大降低了功耗,並大大提高了計算效能。這樣就無需在計算裝置和儲存裝置之間頻繁傳輸數據,大大降低了功耗,並顯著提高了計算效能。
因此,整合儲存和計算技術可以有效克服馮-諾依曼架構的瓶頸。
考慮到技術優勢,整合儲存和計算技術在實際套用中能帶來哪些效能提升?
數據儲存芯片可在某些領域提供更高的計算效能(超過 1000 TOPS)和能效(超過 10-100 TOPS/W),明顯優於現有的專用積體電路。CCS 技術還可以透過利用儲存裝置參與邏輯運算來提高計算能力,這相當於在保持相同面積的情況下增加了計算內核的數量。
在電源管理方面,整合儲存和計算技術可以透過減少不必要的數據處理,將功耗降低到以前的 1/10~1/100,從而提高計算能力,降低功耗,整合儲存和計算技術自然也能更好地收回成本。
綜合儲存和結算技術的分類
根據儲存和計算之間的接近程度,儲存和計算的通用技術解決方案可分為三大類:近記憶體處理(PNM)、記憶體處理(PIM)和記憶體計算(CIM)。
近記憶體電腦是一種更先進的技術。它采用先進的封裝技術,將計算邏輯和記憶體結合在一起,透過縮短記憶體和計算單元之間的路徑來實作高密度的輸入和輸出,進而提供高記憶體頻寬和較低的存取開銷。近記憶體計算主要采用 2.5D 和 3D 堆疊等技術來實作,這些技術廣泛套用於各類 CPU 和 GPU。
相比之下,記憶體處理主要側重於盡可能將計算過程整合到記憶體中。這種實作方式的目標是降低處理器存取記憶體的頻率,因為大部份計算已經在記憶體中完成。這種實作方式有助於消除馮-諾依曼瓶頸帶來的問題,提高數據處理的速度和效率。
儲存計算也是一種將計算和儲存技術合二為一的技術。它有兩個主要目標。首先是透過電路升級使記憶體本身能夠執行計算。通常情況下,這涉及修改 SRAM 或 MRAM 等記憶體,以便在讀取數據的解碼器等地方實作計算功能。這種方法通常具有較高的能效系數,但計算精度可能有限。
其中,近記憶體計算和店內計算是嵌入式儲存技術的主要實作方式。大型制造商要求嵌入式計算架構既實用又能快速實作,作為最接近工程化的技術,近記憶體計算成為大型制造商的首選。近記憶體計算的典型代表是 AMD 的 Zen 系列處理器,而國內的創業公司則不拘泥於先進的處理技術,專註於店內計算,代表企業有神話、奇力軟體、閃盈、曉存、九天瑞信等。
三種主要儲存介質選擇
整合記憶體的電腦系統中的儲存介質可分為兩大類:一類是揮發性記憶體,即在系統正常或突然或意外關機時數據會遺失,如 SRAM 和 DRAM。
第二類是在上述條件下數據不會遺失的非揮發性記憶體,如傳統的 NOR 快閃記憶體和 NAND 快閃記憶體,以及新型記憶體:電阻式 RRAM(ReRAM)、磁性 MRAM、鐵流體 FRAM(FeRAM)和相變記憶體(PCRAM)。
那麽,我們該如何選擇正確的技術途徑,這些技術途徑又有哪些特點、障礙和優勢呢?
就器件工藝成熟度而言,SRAM、DRAM 和快閃記憶體都是成熟的記憶體技術。
快閃記憶體是非揮發性記憶體件之一,具有成本低的優勢,一般適用於低計算能力場景;DRAM 成本低、容量大,但 eDRAM IP 核可用的工藝節點並不先進,讀取延遲也較高,需要定期重新整理數據;SRAM 在速度方面有很大優勢,在容量密度稍低的情況下,能效比幾乎是最高的,而且隨著精度的提高,可以保證更高的精度。精度高,一般用於雲端運算等計算密集型場景。
就工藝技術而言,SRAM 可在 5 奈米等先進工藝上制造,而 DRAM 和快閃記憶體可在 10-20 奈米工藝上制造。
就電路設計難度而言,DRAM>SRAM>Flash記憶體是。在儲存計算方面,SRAM 和 DRAM 的設計難度較大,它們屬於揮發性記憶體,工藝偏差會大大增加模擬計算的設計難度,Flash 屬於非揮發性記憶體,其狀態是連續可編程的,可以透過編程等方式校正工藝偏差,提高精度。近記憶體電腦的設計相對簡單,可以利用先進的記憶體技術和邏輯電路設計技術完成。
除了先進的數據儲存技術外,研究人員還更加關註各種 RRAM 在神經網路電腦中的套用。RRAM 使用電阻調變來儲存數據,讀取電流訊號而不是傳統的電荷訊號,可以實作更好的線性電阻特性。然而,提高 RRAM 工藝效能的工作仍在繼續,非揮發性記憶體固有的可靠性問題也尚未解決,因此它們仍主要用於低端計算和人工智慧邊緣計算。
儲存系統有哪些套用場景?
低計算能力方案:邊緣對成本、功耗、延遲和開發問題非常敏感。
早期,單芯片上的儲存和算力很小,從1TOPS以上的小算力開始,為了解決聲音類、健康類和套用場景側的省電終端視覺、效能和功耗的AI落地芯片。舉例來說AIoT 套用。
眾所周知,在碎片化的人工智慧物聯網市場中,對先進處理器芯片的需求並不多,相反,廉價、高價效比和輕量級芯片更受青睞。
一體化儲存電腦正是滿足這些要求的芯片。
首先,整合儲存和計算技術可以透過限制儲存和計算裝置之間的數據流來大幅降低能耗。例如,傳統架構在傳輸大量數據時會消耗大量能源,而整合儲存和計算架構則可以避免這種不必要的能源消耗,讓電池供電的物聯網裝置(如電池供電的物聯網裝置)執行更長時間。
其次,整合數據儲存技術可以透過減少數據傳輸和提高整合度來降低芯片制造成本。對於大規模部署的人工智慧物聯網裝置而言,降低成本有助於擴大套用範圍。
整合記憶體和整合電腦芯片還能顯著提高計算速度並節省空間,這是支持人工智慧物聯網套用的兩個關鍵因素。
高效能計算場景:GPU 在效能和能效方面都無法與專用加速芯片相媲美。
在當今的雲端運算市場中,成像、推薦和 NLP 等不同人工智慧套用場景的離散演算法功能已無法放在單一的 GPU 架構中,它們都有自己通用的演算法架構。
隨著整合儲存和計算芯片計算效能的不斷提升,套用領域逐漸向高效能套用拓展。針對高計算能力場景,100TOPS,在無人車、泛機器人、智慧駕駛、雲端運算等領域,提供高計算能力、低成本的高效能產品。
此外,儲存芯片還有其他一些廣泛的套用,如感官儲存芯片、類腦芯片等。
國家綜合儲存和核算技術程式
國際傳統儲存制造商看準了這一技術的廣闊發展前景,紛紛踴躍進入這一市場。
在國際上,三星電子正在嘗試多種技術,包括推出新的 HBM-PIM(店內計算)芯片,以及全球第一個基於 MRAM(磁隨機記憶體)的店內計算研究。 台積電在 ISSCC 2021 上展示了基於數位增強 SRAM 設計的店內計算解決方案。英特爾也早就提出了近記憶體計算戰略,將數據上移到儲存層級,更接近計算單元。
在國內市場,記憶體和電腦芯片公司也正在進入這一領域,並將在 2021 年後逐步實作量產和產業化。此前的老牌企業正在利用較為成熟的技術,如易用快閃記憶體、新型記憶體技術、蘋果核心技術、知名數據儲存技術等,還有一些企業則專註於物聯網、可穿戴裝置、智慧家居等小型計算能力場景的其他部份。
隨著相關技術和套用的不斷發展,近年來湧現出的初創企業在高計算能力的安排和新技術的套用方面進行了大膽的嘗試。例如,億播科技、錢芯科技等公司都在專註於高計算能力的人工智慧場景,如大規模電腦建模、自動駕駛等。
在低算力領域,智存科技成功量產了全球首款基於模擬快閃記憶體的儲存芯片WTM2101,該芯片以極低的功耗大規模執行深度學習運算,廣泛套用於可穿戴裝置的智慧語音、醫療服務等場景。該芯片在推出不到一年的時間裏,出貨量已超過 100 萬顆。
蘋果公司近期推出了面向記憶體計算的PIMCHIP-N300整合NPU,采用28奈米和22奈米技術制造,以及PIMCHIP-S300多模態智慧感知芯片,為智慧可穿戴裝置、智慧安防、大規模人工智慧模型、健康數據分析等領域提供支持,特別是支持人工智慧和大規模推理模型等各類計算任務場景。
在高算力方面,後馬智慧推出了首款物理算力高達256TOPS的後馬鴻圖p0芯片,成為國內首家成功儲備高AI算力芯片的企業。目前,p0芯片已開始向Alpha客戶發貨測試,第二代p0芯片正在研發中,預計2024年推出,為2025年量產機型做好支持準備。 準備工作。
去年,EverFoundry 還推出了基於 ReRAM 的 PoC 芯片,具有高精度和低功耗的特點,可實作高計算效能。此外,它還開始開發基於超異構芯片與儲存整合概念的下一代芯片。
隨著技術的不斷發展和套用場景的不斷擴大,店內計算在未來將扮演越來越重要的角色,並推動新計算時代的發展。然而,店內計算仍然面臨著許多挑戰和問題。例如,店內計算的研發必須攻克關鍵技術問題,提高效能和可靠性;同時,店內計算的設計和最佳化必須充分考慮當前的套用需求,提高系統的可延伸性和靈活性。
整合儲存和計算芯片的大舉推出時間尚不明確,但可以預期會發生。技術發展永不停歇,市場需求也在不斷變化,當一切條件成熟時,儲存和計算芯片就會大放異彩。











