全球 AGI(人工通用智慧)市場快速增長的背景下,企業套用成為推動這一領域發展的主要力量,企業如何選擇合適的技術來支撐其智慧化轉型顯得尤為重要。在墨天輪【資料庫技術如何增強 AI 大模型?】資料庫沙龍活動中,拓數派向量資料庫負責人邱老師分享了向量資料庫 PieCloudVector 在增強 AI 大模型方面的技術成果。
如今,大模型套用正以前所未有的速度改變著各個行業。從自然語言處理、電腦視覺到多模態任務的解決方案,AI 技術已經成為推動業務創新的核心力量。
然而,大模型的訓練和推理需要處理大量高維度的向量數據,傳統資料庫在面對這些需求時往往力不從心。為應對這一挑戰,向量資料庫應運而生, 本文將介紹 PieCloudVector 如何利用其獨特的雲原生架構和強大的向量處理能力助力 AI 大模型釋放全部潛力。
1 國內 AGI 發展趨勢
1.1 國內 AGI 市場分層
中國 AGI 市場自下而上分為基礎設施層、模型層、中間層和套用層,這四層結構共同構成了中國 AGI 市場的技術框架。
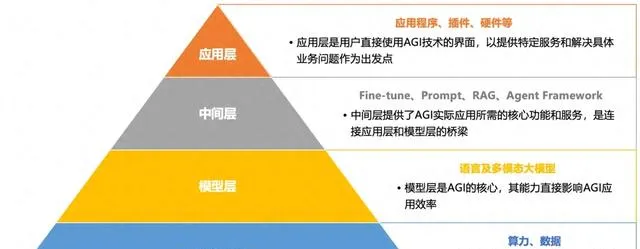
國內 AGI 市場分層
最底層的基礎設施層是 AI 套用的支柱,它提供硬體、算力和網路支持,任何 AI 套用都離不開這些技術;在基礎設施層之上,核心模型的研發是重中之重,所有 AI 套用都圍繞某個大模型構建,而模型的訓練和能力直接影響著 AGI 套用的實際效能;進一步往上,是圍繞模型提供的各種框架、工具、微調能力,它們為實際 AI 落地搭建了一個橋梁;最後的套用層面則是直面使用者業務、解決具體問題的地方。
1.2 AI Agent 推動 AI 迅速發展
最近,AI 領域的一大熱點是「AI Agent」,它正逐漸成為探索的核心路徑。單一的大模型只能生成文字或圖片,實際能夠落地套用的方向比較有限。Agent 的目的旨在讓大模型根據使用者設定的目標,透過與周圍環境互動、使用可存取的數據、呼叫介面和各種輔助工具,使大模型能夠獨立完成某些原本需要人工介入的任務,它的發展方向是深入垂直行業,透過明確和精細的任務範圍來提高實作效果。
目前,Agent 套用已經相當普遍,比如智慧型手機上的語音助手就是一種 Agent 的具體表現形式。
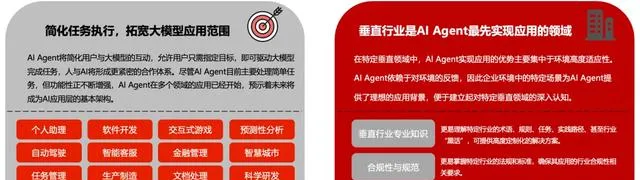
Agent的概念與套用
2 雲原生向量資料庫 PieCloudVector
拓數派雲原生向量資料庫 PieCloudVector 是大模型時代的分析型資料庫升維,可助力多模態大模型 AI 套用,進一步實作海量向量數據儲存和高效查詢,幫助基礎模型在場景 AI 的快速適配和二次開發,是大模型套用必備。
2.1 大模型時代向量資料庫的必要性
大模型透過龐大的語料庫訓練得出,但這些語料庫的數據有一個截止日期,因此它們無法回答關於即時性的問題。例如,如果詢問一個已經訓練好的大模型「現在中國隊在巴黎奧運會上拿了多少塊金牌?」它必然是無法回答的。在這種情況下,就需要對大模型提供外部的上下文,讓大模型可以理解即時的資訊,能夠更好的去回答這類問題。
其次,大模型訓練的語料一般是從公開渠道獲得的,並不能接觸到私域數據,因此訓練出來的大模型不會具有某個領域的專精知識,從而無法回答相關的問題。對於企業構建知識庫套用,數據安全是一個不可忽視的問題,數據不可以隨意出域暴露在公網上,這時則需要一個可以在私域部署的提供數據的平台。
最後,訓練好的大模型是靜態的,不包含長期記憶,例如在聊天機器人場景,使用者每次與模型重新對話時,它並不會記住之前的對話歷史或會話內容。
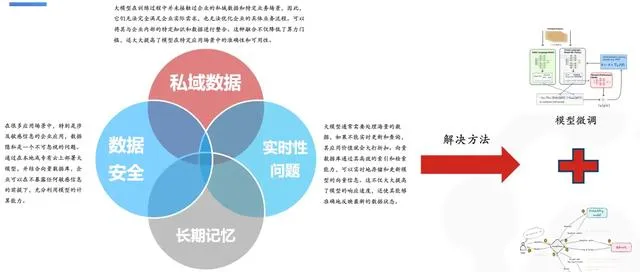
向量資料庫幫助大模型更好地滿足企業需求
上述大模型面臨的局限性問題,都可以透過外部數據檢索系統來解決,向量資料庫則作為一種重要的解決方案應運而生。 透過 RAG 技術,將最新的資訊儲存在向量資料庫中,透過持久化儲存,為模型提供外部知識,提高模型在特定套用場景中的準確性和可用性。此外,還有一種方式是直接對模型進行微調,可以讓大模型本身具備一些最新的資訊,但其成本要高於使用向量資料庫。
2.2 向量計算引擎的核心能力要求
向量數據通常由文字、語音和影像透過內嵌(Embedding)操作轉換得來,對於向量資料庫來說,如何對海量向量數據進行快速且準確的檢索是一個巨大的技術挑戰。因此,向量資料庫必須采用更高級的技術和演算法。

向量計算引擎的核心能力表現
在海量的向量數據中,如何快速且準確地找到與查詢向量最接近的 N 個向量(KNN)是一個關鍵問題。為此,向量資料庫通常使用改進的數據結構(R 樹或 M 樹等),這些復雜的數據結構能夠更有效地組織和儲存高維數據,從而提高檢索效率。
另外,向量引擎還可以采用近似檢索演算法(ANN),透過犧牲一定程度的精度,近似檢索演算法能夠大幅提升檢索效率,常用的演算法包括 IVF、HNSW 等。目前沒有一個通用演算法能在任意數據集上達到所有指標(recall/qps/記憶體)均最優,一般都需要做取舍以達到整體平衡。
最後,向量間距離的計算是向量檢索的核心操作,與大模型的推理或訓練過程類似,即重復進行同樣的計算。這類操作非常適合使用 GPU 或 FPGA 進行加速,單純依賴 CPU 的效率則較低。因此,硬體加速是向量計算引擎不可或缺的能力。
2.3 雲原生向量資料庫 PieCloudVector
拓數派旗下雲原生資料庫 PieCloudVector 基於 PostgreSQL 內核打造,支持單機和分布式部署,具備完整的 ACID 特性。PieCloudVector 支持向量純量混合查詢,即在同一個表中包含向量列和純量列,可以使用 SQL 對向量列進行 ANN 近似尋找,並對純量列進行條件篩選。PieCloudVector 相容 LangChain、LlamaIndex 等主流大模型套用框架,並對外提供了 SQL/REST/Python 介面。
2.3.1 PieCloudVector 架構特點
PieCloudVector 整體架構由四個主要元件構成:管控服務、後設資料服務、計算節點和儲存底座。具體如下圖所示:
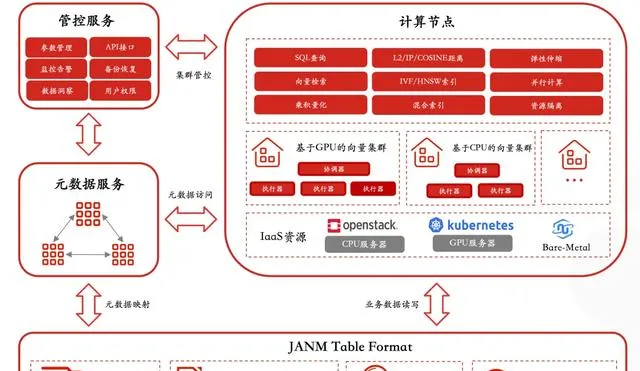
PieCloudVector 整體架構
PieCloudVector 的計算節點可彈性擴容,具備專用的後設資料儲存服務,可透過儲存底座存取本地檔案系統或 S3 或其他數據湖等儲存。計算節點預設分為協調器和執行器兩個角色,協調器負責接收 SQL 查詢,並進行解析和最佳化,最終將任務分發給執行器,執行器則負責實際的向量搜尋操作。
PieCloudVector 支持主流的 ANN 演算法, 包括 IVF、HNSW 以及新加入的 ScaNN 和 DiskANN, 並支持利用 GPU 進行加速計算 ,大幅提升效能。整套計算節點服務既可以在裸機上直接部署,也可以部署在帶有管控層的平台上,同時也支持在公有雲環境進行部署。
PieCloudVector 管控服務是與使用者直接進行互動的介面,提供了管控頁面和各種 API 介面,在管控服務中可以進行所有向量索引的管理、整個集群的監控、不同集群之間的備份、使用者許可權管理和數據洞察等操作。
2.3.2 PieCloudVector RAG 工作流程
PieCloudVector 支持 RAG 相關套用能力。 RAG 是一種將檢索模型(通常是向量資料庫)和生成模型結合在一起的技術,核心思路是使用來自私有資料來源的資訊來輔助模型生成更為準確的內容。
下面將介紹 PieCloudVector 基於 RAG 技術構建知識庫套用的流程:
對於套用使用者,當使用者提出問題時,套用會透過同樣的 Embedding 模型將問題轉換為向量,並在向量資料庫中進行向量搜尋找到與目標向量相關的所有知識塊,然後將這些知識塊包含的資訊與原問題進行組合形成新的提示詞輸入給大模型,最終得到品質更高的答案。
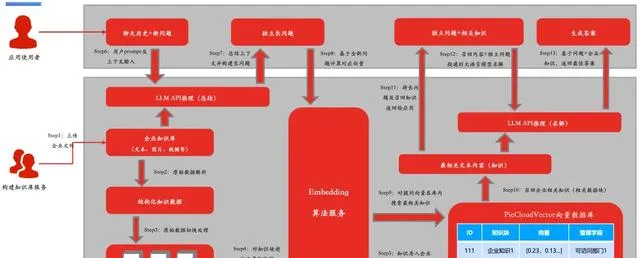
RAG 工作流程
盡管向量搜尋在 RAG 中非常有用,但也有其局限性。比如,透過向量搜尋得到知識庫內容同樣會導致結果出現「幻覺」,輸出與問題不相關的內容,這種現象可能與 Embedding 模型的選擇、切塊策略等因素有關。例如,如果切塊時將重要資訊分成了兩塊,或是上下文整合時遺失實際語意,還有可能是向量搜尋得到的結果無法與提示詞良好結合,這些因素都會影響最終生成的回答品質。 這也是為什麽 PieCloudVector 開始探索新一代 GraphRAG 架構的原因。
2.3.3 PieCloudVector 發展趨勢:新一代 GraphRAG 架構
為克服向量 RAG 的局限性,PieCloudVector 將在不久的未來,計劃結合向量搜尋和圖搜尋的優勢,即采用 GraphRAG 架構。其整體流程如下:
3 AIGC 全生命周期管理
對於使用者來說,他們更希望企業能夠基於使用者提供的私域知識、語料庫搭建一站式 AIGC 套用。而為了滿足這些需求,拓數派提出了大模型數據計算系統 PieDataCS,並支持包括向量資料庫 PieCloudVector 、雲原生虛擬數倉 PieCloudDB Database、大模型機器學習 PieCloudML 三款計算引擎。
PieDataCS 將整個模型生命周期管理整合在一起,包括模型的建立、訓練、品質測試、微調、部署和推理等所有操作,同時整合了多種計算引擎和各種框架,為使用者提供了一個完整的解決方案。
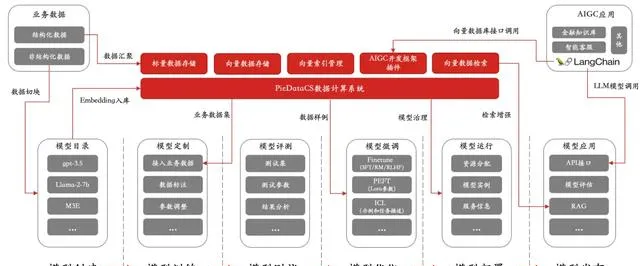
PieDataCS 整合整個模型生命周期
在 AIGC 套用中,模型和框架的能力各占一半。透過 PieDataCS 構建 AIGC 套用的流程可分成兩步:
拓數派雲原生向量資料庫 PieCloudVector 憑借其卓越的效能和廣泛適用性,已成功在多個行業領域中落地套用。
4 落地案例分享
4.1 某金融客戶 AIGC 套用實踐
在某金融客戶 AIGC 套用的實踐中,整個套用基於向量資料庫 PieCloudVector 與 LangChain 框架打造,透過 Embedding 模型將收集到的法律法規、政策檔、報告以及各種投研材料等內容轉換為向量並儲存到 PieCloudVector 中,構建了一個強大的 RAG 框架,最終在前端的套用中可以為使用者提供投研分析、量化分析、情緒分析等復雜任務,並實作了問答機器人的功能。
金融行業案例
02. 聯合某高校打造多模態數據分析課程
在另一個案例中,拓數派與某高校聯合打造了多模態數據分析的課程。整個數據分析的流程首先是使用 Embedding 模型將各種文本、語音、圖片等數據轉換為向量,然後透過對外提供的 Python SDK 將這些向量數據一同輸入到 PieCloudVector 中,利用 PieCloudVector 強大的向量數據處理和分析能力,最終實作智慧推薦、文件檢索等功能。
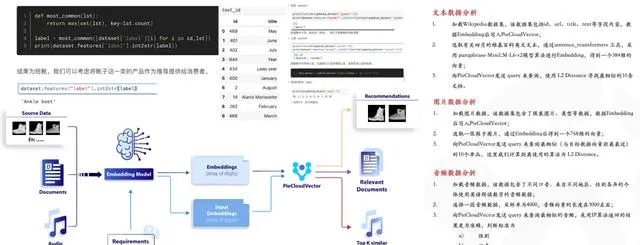
多模態數據分析課程











